SimCSE: Simple Contrastive Learning of Sentence Embeddings
Sentence BERT에 이어서 SimCSE를 살펴보겠습니다. SimCSE는 Sentence BERT의 업그레이드 버전이라고 볼 수 있습니다. SimCSE는 아래와 같은 점들을 기여합니다.
1. contrastive learning을 unsupervise 방식으로 수행하는 방법을 제시
2. 더 효율적인 방식의 supervised learning.
3. Supervised learning에서 hard-negative의 적용.
하나씩 알아가 보도록 하겠습니다.
1. Contrastive Learning
Contrastive learning이란 서로 연관 있는 임베딩끼리는 가깝게, 연관 없는 임베딩끼리는 멀도록 매핑하는 학습방법을 뜻합니다. SBERT에서는 NLI 데이터셋을 이용해 'entailment' 라벨의 문장은 긍정 쌍(positive pair)으로, 'contradiction' 라벨의 문장은 부정 쌍(negative pair)으로 하여 두 문장의 임베딩 사이의 거리를 cosine similarity를 사용해 계산하여 학습했습니다. SimCSE에서는 In-batch negative라는 방식을 사용해 이를 수행합니다. 기존의 SBERT의 방식은 한번에 '한 쌍'의 데이터만 학습할 수 밖에 없는 단점을 가집니다. In-batch negative는 batch 단위로 '여러 쌍'의 데이터를 학습할 수 있는 방법입니다.
1-1. In-batch negative
하나의 배치에 4개의 긍정 쌍을 구성했다고 가정해 보겠습니다.

이를 그대로 학습한다면, 모델은 4 쌍의 문장을 이용해 4번의 학습을 수행하게 될 것입니다.
In-batch negative는 자기 자신의 positive 쌍을 제외한, 같은 배치의 다른 positive 쌍들을 자신의 negative 쌍으로 간주하는 것을 말합니다.

그림과 같이 In-batch negative를 사용한다면, 모델은 4쌍의 데이터만으로 16번의 학습을 진행할 수 있게 됩니다. 학습의 효율성이 크게 올라가게 되는 것이죠.
이는 cross-entropy를 사용해 학습할 수 있습니다. $h_i$와 $h_i^+$가 입력문장 $x_i$와 $x_i^+$의 임베딩 벡터라 하고 N개의 쌍으로 이뤄진 미니배치 N에서, in-batch negative의 목적 함수는 다음과 같이 쓸 수 있습니다.
$$ l_i=-log{{e^{sim(h_i,h_i^+)/\tau}}\over{\Sigma^N_{j=1}e^{sim(h_i,h_j^+)/\tau}}} $$
$\tau$는 cross entropy의 temperature 하이퍼 파라미터(출력 라벨의 분포 간의 차이를 줄이는 역할)를 뜻하고, $sim(h_1,h_2)$는 유사도 계산 함수로 cosine similarity를 사용합니다.
SimCSE는 In-batch negative를 이용해 unsupervise 방식과 supervise 방식으로 문장 임베딩을 학습합니다.
1-2. Positive pair
어쨌거나 In-batch negative를 사용하려면, 긍정 쌍 데이터셋이 필요합니다. Supervise 방식은 STS나 NLI 데이터셋을 사용할텐데, SimCSE에서 Unsupervise 방식은 어떻게 적용할까요?
비전 영역이라면 이미지를 회전시킨다던지, 일부를 자른다던지, 뒤집는다던지 하는 augmentation 방식을 적용하여 긍정 쌍을 구축할 수 있습니다. 그러나 NLP에서는 이런 증식 기법들을 적용하기가 힘들죠. 문장의 일부 단어가 바뀐다거나 순서가 바뀐다거나 하는 것만으로도 그 뜻이 달라질 수 있기 때문입니다.
SimCSE에서는 dropout mask를 이용해 긍정 쌍을 확보합니다. Dropout은 원래 모델 레이어의 일부분을 무작위로 꺼버려서 모델의 과적합을 막는데 사용되는 방법입니다. 무작위로 적용되기 때문에, 같은 문장이 입력되더라도 서로 다른 결과가 나오게 됩니다. BERT 모델에는 Transformer block 마다 dropout 레이어가 존재합니다. 그렇기 때문에 이 dropout 레이어를 사용해 동일한 문장의 다른 값을 갖는 서로 다른 임베딩을 얻을 수 있게 됩니다. 이렇게 dropout이 적용된 같은 문장의 다른 임베딩을 긍정 쌍으로 사용합니다.
class SimCSE(nn.Module):
def __init__(self, model_name, dropout_prob):
super(SimCSE, self).__init__()
self.bert = AutoModel.from_pretrained(model_name, hidden_dropout_prob=dropout_prob)
self.cosine_similarity = nn.CosineSimilarity()
def forward(self, src_ids):
# 다른 dropout mask가 적용된 output을 얻기 위해 input을 같은 bert에 2번 forward 시킵니다.
outputs1 = self.bert(**src_ids).pooler_output # shape = [batch_size, hidden_dim]
outputs2 = self.bert(**src_ids).pooler_output
'''
shape을 맞추기 위해 unsqueeze를 합니다.
outputs1 shape -> [batch_size, 1, hidden_dim]
outputs2 shape -> [1, batch_size, hidden_dim]
score shape -> [batch_size, hidden_dim]
'''
score = self.cosine_similarity(outputs1.unsqueeze(1), outputs2.unsqueeze(0))
return outputs1, score
criterion = nn.CrossEntropyLoss()
simcse = SimCSE("klue/bert-base", 0.1)
simcse.bert.train()
# 같은 위치의 문장 쌍이 positive pair입니다.
labels = torch.arange(batch_size)
scores = simcse(**inputs)
loss = criterion(scores, labels)1-3. Alignment & Uniformity
Contrasitve learning에는 2가지 중요한 요소가 있습니다.
1. Alignment : 입력 벡터와 입력 벡터의 긍정 쌍에 해당하는 벡터 사이의 거리.
2. Uniformity : 학습된 임베딩 벡터가 얼마나 균등한 값을 갖는지를 측정.
Alignment는 contrastive learning을 통해 자연스럽게 작아지도록 학습됩니다. 서로 관련 있는 임베딩끼리는 거리가 가까워야겠죠? Uniformity는 모델이 잘 학습되었다면, 서로 다른 벡터마다 모두 개성있는 값을 가져야 합니다. 개성있는 값을 가진다는 말은, 임베딩 벡터가 512차원이라면, 512개의 값이 균등한 것보다는 그 벡터의 특징을 잘 드러내는 차원의 값은 크고, 아닌 값은 작아야 겠죠. 즉, alignment와 uniformity가 작을수록 임베딩 벡터를 잘 학습한 모델이라고 볼 수 있습니다.

2. Unsupervised SimCSE
Dropout이 data augmentation의 역할을 제대로 수행하는지를 검증해 볼 필요가 있습니다. 논문에서는 STS-B을 이용해 다른 augmentation 기법들과 비교 실험을 진행합니다.

위 표를 보면 다양한 augmentation 기법을 사용하여 in-batch negative를 수행한 결과, SimCSE의 Dropout mask 기법이 가장 높은 점수를 받은 것을 확인할 수 있습니다.
또 기존의 연구에서 수행했던 next sentence objective와의 비교도 실험했습니다. (비지도 학습으로 문장 임베딩을 학습하기 위한 방법으로 next sentence prediction 방법을 수행했던 연구)

결과는 SimCSE의 점수가 압도적으로 높았습니다. 또, 인코더로 2개의 BERT를 사용해 학습하는 것보다 하나의 BERT로 학습하는 것이 성능이 더 좋았습니다.
Dropout rate의 경우도 실험을 통해 0.1을 사용하는 것이 가장 성능이 좋다는 것을 확인했습니다.

여기서 하나 주목해 볼만한 점은, dropout rate를 0으로 설정했을 때와 Fixed 0.1로 설정했을 때입니다. Fixed 0.1은 Dropout을 적용하기는 하지만 어느 레이어를 끌지를 고정하는 방식을 말합니다. 0이나 Fixed 0.1이나 둘 다 같은 문장 임베딩을 출력할 것입니다. 그러나 위 표를 보면 성능이 30점 가까이 차이나는 것을 확인할 수 있습니다.
논문에 써있지는 않은데 이는 Develop 셋에 inference할 때는 dropout이 적용되지 않기 때문에 이런 차이가 난 것으로 보입니다. Dropout rate를 0.1로 적용했을 때도 마찬가지이기는 하겠지만, 서로 다른 임베딩을 positive 쌍으로 본다는 것에서 차이가 발생한 것으로 보이고, 이는 SimCSE의 방식이 효과적이라는 것을 입증하기 때문에 이런 내용을 쓴게 아닐까 싶습니다.

또 Dropout rate와, Delete one word 방식을 10에포크 학습하면서, 각 에포크의 체크포인트마다 모델을 저장하여 각 모델의 alignment와 uniformity를 시각화한 그래프도 그려봅니다. 위 그래프를 보면 Dropout rate를 0이나 Fixed 0.1로 설정했을 때는 학습이 진행됨에 따라 alignment가 증가되는 모습을 보입니다. 그러나 SimCSE는 학습이 진행되더라도 alignment가 증가되지 않습니다. Dropout을 이용한 augmentation이 alignment 학습에 도움을 준다는 것을 입증하는 듯합니다.
Delete one word 방식은 alignment가 더 작긴 하지만 그만큼 uniformity가 커서 SimCSE보다 낮은 점수를 받은 것으로 보입니다.
3. Supervised SimCSE
SimCSE는 Superivsed learning에서도 In-batch negative를 사용합니다. 이를 위해선 긍정 쌍을 구성할 수 있는 데이터셋을 사용해야 합니다. SimCSE는 여러가지 데이터셋들을 테스트 해봅니다.
1. QQP : Quora Question Pair
2. Flickr30k : Flickr의 이미지들을 5명의 사람이 각각 직접 이미지의 자막을 달아 놓았습니다. 같은 이미지의 자막을 positive pair로 간주합니다.
3. ParaNMT : Back-translation을 적용한 대량의 문서 데이터셋입니다.
4. NLI : SNLI와 MNLI의 entailment 쌍을 사용.
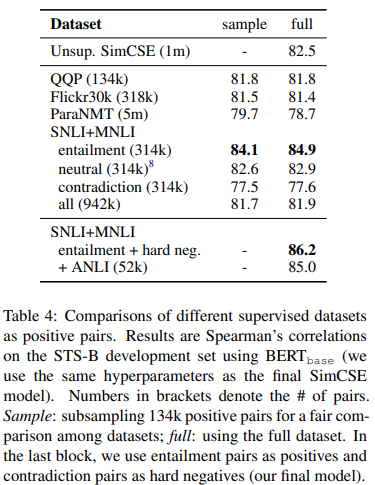
공정한 비교를 위해 4가지 데이터셋 모두 같은 개수의 데이터 쌍을 사용했습니다. 이 중에서 가장 성능이 좋았던 것은 NLI 데이터셋이었습니다. NLI 데이터셋이 가장 목적에 적합하기도 하고, 단어를 최대한 다르게 사용해야 한다는 가이드라인에 따라 작성되었기 때문에 2 문장에 겹치는 단어가 가장 적기도 하여 이런 결과를 낸 것으로 봅니다.
3-1. Contradiction as hard negatives
NLI 데이터셋에는 하나의 문장에 대해서 entailment 문장과 contradiction 문장이 각각 하나씩 주어집니다. SimCSE의 저자들은 entailment 문장 쌍뿐만 아니라 contradiction 문장 쌍도 hard negative로 활용하고자 합니다.
Hard negative는 확실한 negative pair라고 볼 수 있습니다. In-batch negative는 같은 배치의 다른 positive pair들을 negative로 간주하고 학습하는 방법입니다. 그러나 이 positive pair들은 사실 진짜 negative pair는 아닙니다. 재수없게 같은 내용의 문장이 같은 배치에 들어갈 수도 있고, 서로 'contradiction' 관계라기 보다는 '관계없음'일 확률이 훨씬 높죠. 그렇기 때문에 'contradiction' 라벨의 문장을 negative 쌍으로 활용할 수 있다면 모델에 도움이 될 수 있습니다.

이렇게 hard negative를 추가함으로써 1.3점 정도 성능 향상을 볼 수 있었다고 합니다. 데이터셋 별 결과와 Hard negative 추가의 결과는 아래 표에서 확인할 수 있습니다.
4. Connection to Anisotropy
좀 더 깊게 들어가 보겠습니다. Contrastive learning이 필요한 이유가 뭘까요? 이 즈음에 NLP 영역에서 문제로 제시되던 주제가 있었습니다. Anisotropy라는 것은, 거대한 벡터 공간 내에서 언어 임베딩이 차지하는 공간이 narrow cone 모양처럼 아주 좁다는 것을 말합니다. 그리고 이것이 언어 모델의 표현력을 떨어트린다는 점을 지적합니다.

이것이 왜 문제가 될 수 있을까요? 문장 임베딩들 간의 거리가 가깝다는 것은 그만큼 모델이 문장들을 잘 구분해내지 못한다는 것을 의미합니다. 서로 전혀 의미가 다른 문장도 가까운 거리에 있다는 것이니까요. 반대로 문장 임베딩들 간의 거리가 멀다면, 그만큼 모델이 각 문장들의 의미를 잘 구분하고 있다고 해석할 수 있습니다. (물론 절대적인 것은 아닙니다.)
Anisotropy 문제는 앞에서 말한 uniformity와도 연관이 있습니다. 만약 uniformity가 높아 문장 임베딩 값이 균일하다면, 그만큼 각 문장의 고유한 의미를 나타내기가 어렵다고 볼 수 있습니다. 고유한 의미를 나타내기 어렵다는 것은 그만큼 각 문장들의 임베딩이 유사하다는 것이고, 이는 임베딩 공간이 narrow cone처럼 작아진다는 것을 의미합니다.

머리로 그려볼 수 있게 2차원 벡터를 생각해 보겠습니다. 만약 2차원 벡터들의 uniformity가 높다면(x와 y의 값이 유사), 좌측 그림과 같이 벡터들이 형성될 것입니다. Cosine similarity는 벡터의 방향을 측정하는 척도입니다. 좌측 그림과 같은 벡터들은 모두 비슷한 방향을 가리키기 때문에 높은 cosine similarity를 가질수 밖에 없습니다. 반대로 벡터들의 uniformity가 낮다면, 벡터들이 우측 그림과 같이 그려질 것입니다. 모두 다양한 방향을 가리키고 있기 때문에 cosine similarity도 낮아질 수 있습니다.
Contrastive learning은 이런 문제들의 해결책이라고 볼 수 있습니다. Negative pair의 거리를 멀게하는 것은 곧 임베딩 공간의 크기를 늘리는 것과 같습니다. 그리고 임베딩 공간을 늘리기 위해서는 각 문장의 임베딩이 구분되어야 하고 독립적인 값을 가져야 하고 이는 uniformity의 감소로 이어질 수 있습니다.(Figure 2)

5. 실험
SimCSE의 성능을 테스트하기 위해 7가지 STS task들로 모델을 평가합니다. (STS 2012-2016, STS-B, SICK-Relatedness)
모델 훈련은 사전학습된 BERT와 RoBERTa 모델을 사용해 전이학습으로 이뤄지며 CLS Pooling을 사용합니다. (SimCSE는 SBERT와 다르게 Pooling 방법에 따른 성능 차이가 거의 없었다고 합니다.)
Unsupervised SimCSE는 $10^6$개의 위키피디아 문서의 문장들을 사용해 학습을 하며, supervised SimCSE는 MNLI와 SNLI 데이터셋을 사용해 학습합니다.

Unsupervised learning의 실험 결과는 위와 같습니다. 결과는 문장 임베딩을 생성하고자 한 기존의 연구들과 비교를 합니다. SimCSE의 결과가 다른 결과들에 비해 꽤 압도적인 성능을 보여주는 것으로 보입니다.

Supervised learning의 실험 결과는 위와 같습니다. SBERT와 비교해 봐도 적게는 3점에서 많게는 7점까지 점수 차이가 나는 것을 확인할 수 있습니다.

SBERT와 같이 SimCSE도 STS, NLI 외의 task들에 transfer learning을 적용했을 때 기존 SOTA와 유사하거나, 더 좋은 성능을 보이는 것을 확인할 수 있습니다.

위 그림은 모델 별로 alignment와 uniformity를 그린 그래프입니다. whitening과 flow는 임베딩의 uniformity를 낮추기 위해 사용되는 기법으로 확실히 낮은 uniformity를 보이고 있지만 높은 alignment 수치를 보입니다. SimCSE는 uniformity도 낮은 편이지만 alignment도 많이 낮은 모습을 보이고 있습니다.
6. 결론
SimCSE를 통해 in-batch negative를 이용한 contrastive learning이 pretraining 방식에도 효과적이란 것을 알 수 있었습니다. 이 논문을 통해 contrastive learning에 대해서 alignment와 uniformity를 이용해 더 깊게 이해할 수 있었습니다. 그리고 contrastive learning을 비지도 학습에도 적용할 수 있다는 것에서 인상적이었던 것 같습니다.
https://arxiv.org/abs/2104.08821
SimCSE: Simple Contrastive Learning of Sentence Embeddings
This paper presents SimCSE, a simple contrastive learning framework that greatly advances state-of-the-art sentence embeddings. We first describe an unsupervised approach, which takes an input sentence and predicts itself in a contrastive objective, with o
arxiv.org