Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
오늘 소개할 논문은 줄여서 RAG라고 불리는 연구입니다. RAG는 BART, GPT, T5와 같은 생성 모델의 성능을 보완하면서 모델이 학습한 정보를 컨트롤하기 쉽다는 장점을 가지는 모델입니다. RAG의 배경, 모델 구성, 실험 결과 순으로 소개를 하도록 하겠습니다.
1. 배경 소개
1-1. ODQA와 Retrieval
일반 QA task는 질문과 답변, 그리고 답이 담긴 관련 문서가 주어집니다. 그러면 딥러닝 모델은 질문과 관련 문서를 보고 답을 예측해내야 합니다. 그렇지만 ODQA(Open Domain Question Answering)는 관련 문서가 주어지지 않습니다. 질문과 답변만 주어지고 관련 문서는 거대한 문서 집합에서 모델이 직접 찾아내야 하는 것입니다.
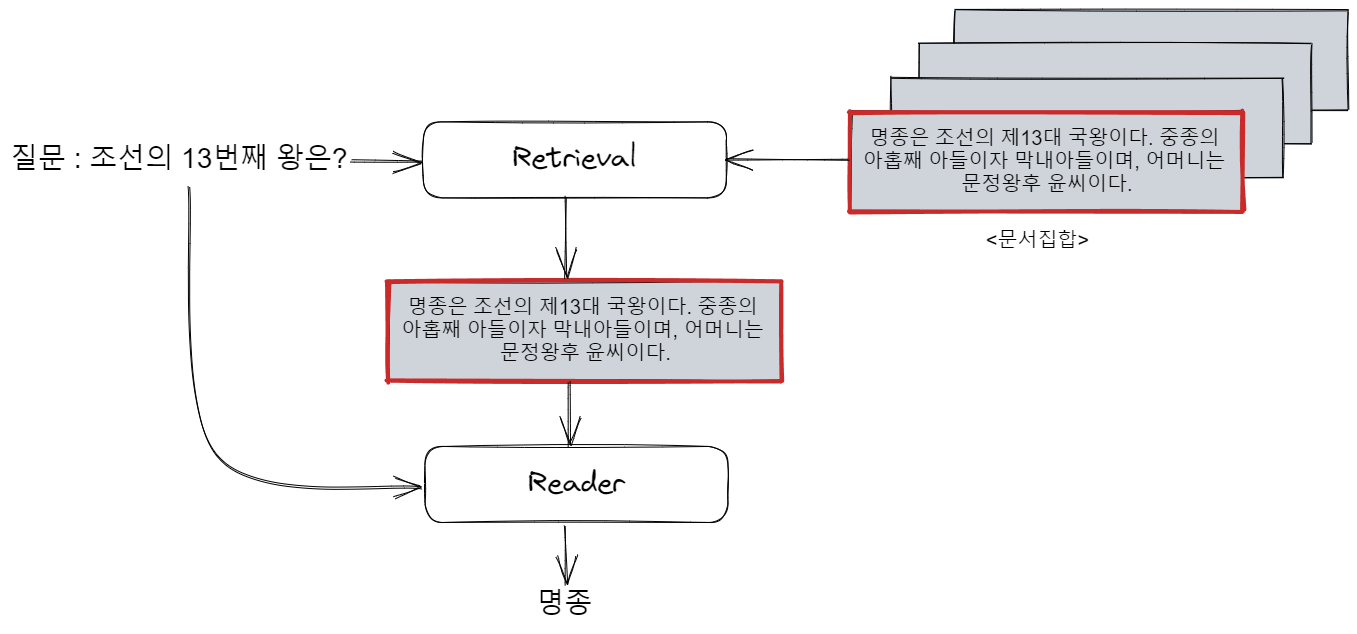
Retrieval는 ODQA 데이터의 훈련셋에 있는 질문과 관련 문서를 이용해 학습됩니다. Retrieval는 질문의 관련 문서와 관련 없는 문서를 구분하는 방법을 학습합니다.
1-2. NLP Generation task
NLP task는 Transformer가 등장한 뒤로, 대규모 텍스트 데이터를 이용한 사전 학습된 모델을 사용하는 것이 정석으로 자리 잡았습니다. 이는 문장 생성 task에서도 마찬가지로, 사전학습된 GPT, BART, T5를 사용하는 것이 관행이었습니다. 이런 방식은 꽤나 성공적이었지만 한계점도 존재합니다.
- 학습한 정보를 활용해야 하는 복잡한 task에 약함.
- 모델이 어떤 정보를 학습했는지 확인하기 어려움.
위의 한계점들로 인해 생기는 가장 큰 문제는 'hallucination'이라고 할 수 있습니다. 이는 모델이 거짓 정보를 진짜인 것처럼 그럴싸하게 말하는 것을 뜻합니다. 최근 chatGPT와 같은 모델들에서도 흔히 나타나는 문제지요. 특히 기존의 GPT와 같은 모델은 텍스트를 생성할 때 어떤 정보에 근거해서 텍스트를 만든 것인지 확인이 어렵기 때문에 이를 고치기가 더 어렵습니다.
1-3. RAG(Retrieval-Augmented Generation)
텍스트 생성 모델의 문제점을 본 뒤에 다시 retrieval에 대해 생각해 보겠습니다. Retrieval는 질문에 대한 답을 얻기 위해 이와 관련된 정보가 담긴 문서들을 찾아오는 모델입니다. 그리고 hallucination은 모델이 진짜처럼 만든 거짓 정보를 어디서 보고 만들어낸 것인지 알기 어려운 것이 문제였죠. 여기서 RAG의 저자는 이 retrieval를 텍스트 생성 모델과 함께 활용한다면 이런 문제를 완화할 수 있지 않을까? 라고 생각을 하게 됩니다.
RAG는 retrieval를 non-parametric memory, BART와 같은 생성 모델을 parametric memory라고 표현합니다. RAG는 기존 parametric memory만으로 이뤄진 모델과 비교했을 때, retrieval와 생성 모델을 함께 학습하면서 더 고도의 지식 활용을 요구하는 task에도 더 강한 모습을 보일 수 있고, 모델이 어떤 근거로 이런 텍스트를 생성했는지 확인 가능하다는 장점을 갖습니다.
2. RAG의 작동 방식
2-1. Retrieval: DPR
RAG의 retrieval에는 DPR(Dense Passage Retrieval) 모델이 사용됩니다. DPR은 2개의 BERT 인코더를 사용해 질문과 관련 문서를 각각 인코딩하는 방식을 사용합니다.

인코딩된 질문과 문서의 벡터는 dot product를 통해 유사도를 계산합니다. 이 유사도 점수가 높을수록 질문과 문서가 관련 있다고 판단할 수 있게 됩니다. 또, dot product를 사용해 유사도를 계산하기 때문에 문서의 벡터들을 미리 계산해 두는 것이 가능합니다. 따라서 학습이 끝난 모델을 실제로 사용할 때는 벡터를 미리 계산해 둠으로써 관련 문서를 빠르게 찾을 수 있습니다.
(이렇게 2개의 BERT 인코더를 활용하는 방식을 Dual-Encoder라고 하며, 속도가 빠른 장점을 갖습니다. 이와 반대로 하나의 BERT 인코더를 활용해 질문과 문서를 함께 인코딩하는 Cross-Encoder 방식도 있는데, 이 방식이 성능은 더 좋지만 문서들의 임베딩 벡터를 미리 계산할 수 없기 때문에 속도가 느리다는 단점이 있습니다.)
2-2. Generator: BART
RAG의 생성 모델에는 BART를 사용합니다. BART는 BERT 인코더와 GPT 디코더가 결합된 구조를 가집니다. 두 방식이 결합됨으로써 BERT와 GPT의 장점을 모두 가질 수 있습니다.
생성 모델은 질문과 retrieval를 통해 찾은 관련 문서를 입력으로 받으며, 이를 보고 질문에 알맞은 정답을 생성하는 식으로 작동합니다.

2-3. RAG 유형
RAG는 retrieval가 가져온 k개의 관련문서(top-k)를 어떻게 활용하느냐에 따라 2가지 decoding 방식을 가집니다. 또한 RAG는 BART와 같이 텍스트 생성뿐만 아니라 분류 문제도 수행할 수 있습니다.
1) RAG-Sequence Model
1. 각 top-k 문서마다 답을 n개씩 출력합니다.
2. 각 답의 probability와 해당 답이 등장한 문서의 probability를 곱한 뒤에 모두 더해 최종 probability를 계산합니다.

2) RAG-Token Model
- 일반 생성모델과 같이 이전 시퀀스까지의 probability를 이용해 다음 토큰을 예측하지만, 여기에 top-k retrieval 점수를 곱해서 최종 probability를 계산합니다.
- Beam search를 수행합니다. Beam search는 최고 probability를 갖는 n개의 후보들을 비교하여 최종 결과를 선정하는 탐색 방법입니다.

2-4. 훈련 방식
DPR과 BART는 각 논문의 방식대로 사전학습된 모델을 사용합니다. RAG는 이들을 결합하여 fine-tuning 합니다. RAG의 학습에는 retrieval가 가져와야 할 문서에 대한 정보를 제공하지 않고, GPT와 BART를 훈련할 때와 같이 입력 텍스트와 출력 텍스트 쌍만이 데이터로 주어집니다.
관련 문서가 정해져 있지 않기 때문에 RAG는 BART보다 더 많은 것을 고려하고 답을 추론해 내야 합니다. 그렇기 때문에 일반 생성모델보다 더 고도의 정보 활용 능력을 기를 수 있게 됩니다.
- 'Retrieval가 가져온 문서들이 진짜로 답과 관련이 있는가?'
- '문서들이 답과 관련이 없다면 어떻게 답을 생성해야 할까?'
또, DPR의 문서 인코더는 학습 속도를 위해 학습하지 않습니다. 문서들은 길이도 길고 수도 굉장히 많기 때문에 이들의 임베딩 벡터를 다시 계산하는데 시간이 너무 오래 걸리고, 이들을 업데이트 하면서 학습한다고해서 모델의 성능이 크게 향상되지도 않았기 때문입니다.
3. 실험 결과
- RAG의 non-parametric memory는 2018년 12월 날짜의 wikipedia 문서를 이용해 학습되었습니다.
- FAISS의 MIPS를 활용해 더 빠르게 관련 문서를 탐색할 수 있도록 합니다.
- top-k는 상위 5개, 10개 문서로 설정해서 학습합니다.
RAG의 성능을 다방면에서 검증하고 분석하기 위해 ODQA, AbstractQA, Jeopardy Question Generation, FEVER 4가지로 실험을 진행했습니다.
3-1. ODQA
RAG의 지식 활용 능력을 테스트하기 위해 ODQA task 실험을 수행했습니다. 데이터셋은 Natural Questions(NQ), TriviaQA(TQA), WebQuestions(WQ), CuratedTrec(CT) 4가지를 사용했으며, CT와 WQ는 데이터의 양이 적기 때문에, 데이터가 많은 NQ를 이용해 RAG를 사전학습해서 사용했다고 합니다.

결과는 위와 같았습니다. T5-11B+SSM은 T5 모델에 Salient Span Masking(문장에서 중요한 단어를 masking하는 사전학습 방식)을 적용한 방식으로, RAG는 이런 사전 학습을 수행하지 않고도 T5보다 좋은 점수를 달성했습니다.
또, 위표의 DPR은 하나의 BERT 인코더를 활용해 top-k 문서들을 rerank하는 방식을 사용한 결과인데, RAG는 이런 rerank 방식을 사용하지 않고도 SOTA를 달성했습니다. (Rerank 방식은 cross-encoder를 활용하므로 보통 dual-encoder 방식보다 성능이 더 좋습니다.)
ODQA를 푸는 데는 extraction 방식과 generation 방식이 존재합니다. Extraction 방식은 주어진 문서에서 정답의 위치를 추출하는 방식으로 일반적으로 generation 방식보다 성능이 좋지만, 문서에 정답이 존재하지 않는 경우엔 답을 낼 수 없다는 단점을 가집니다. 반대로 generation 방식은 모델이 직접 텍스트를 생성하기 때문에 extraction 방식보다 성능이 떨어지지만 답이 문서에 존재하지 않더라도 맞출 수 있다는 장점을 가집니다. 하지만 실험 결과 RAG는 generation 방식임에도 extraction 방식보다 좋은 점수를 받았습니다.
3-2. Abstractive QA(MS MACRO)
MS MACRO 데이터셋은 bing 검색엔진의 결과를 이용해 질문과 관련 문서 쌍을 구성한 데이터셋입니다. RAG는 MS MACRO의 관련 문서를 사용하지 않고 질문과 답변 쌍만을 이용해 학습을 했습니다. MS MACRO의 모든 질문의 답을 wikipedia에서 찾는 것은 불가능하지만, RAG의 retrieval는 wikipedia로 학습이 되어 있습니다. 따라서 RAG가 MS MACRO에서 좋은 성능을 보이기 위해선, non-parametric memory보다 parametric memory를 더 잘 활용할 수 있어야 합니다.

결과는 위 표의 가운데와 같이 BART보단 RAG의 성능이 더 좋았습니다. 게다가 RAG가 wikipedia의 정보만으로 해결할 수 없는 질문에 대해서도 정답을 잘 맞추는 것을 확인할 수 있었다고 합니다. 학습을 통해 parametric memory도 충분한 추론 능력을 가진다는 것을 알 수 있습니다.
3-3. Jeopardy Question Generation
Jeopardy Question Generation은 일반적인 QA와 다르게 질문에 대한 답을 생성하는 것이 아니라, 답에 대한 질문(또는 설명)을 생성해야 하는 task 입니다. 예를 들면, 'The World Cup'이라는 단어가 입력으로 주어지면, "In 1986 Mexico scored as the first country to host this international sports competition twice."와 같은 문장을 출력해야 합니다. 따라서 모델에게는 단답형의 답을 제시해야하는 QA task들에 비해서 더 어려운 문제일겁니다.
물론 위 표와 같이 RAG가 SOTA를 달성했습니다. 그리고 또 하나 흥미로운 사실을 하나 발견할 수 있었습니다. Jeopardy question generation을 위해선 보통 2개 이상의 문서의 내용을 결합하여 추론할 수 있는 능력이 필요합니다. 이를 확인하기 위해 RAG가 토큰을 생성할 때마다 어떤 문서를 참고했는지를 확인하기 위해 아래와 같이 attention map을 그려봤습니다.

결과를 보면 "Sun"이라는 글자를 만들 땐 2번 문서를 참고했고, "A"라는 글자를 만들 땐 1번 문서를 참고했습니다. 즉, 2개 이상의 문서 정보를 고려하고 있단 것을 확인할 수 있습니다.
또한 "The Sun Also Rises"는 책의 제목인데 모델이 여기서 'Sun'을 생성할 때만 2번 문서를 참고하고 나머지는 거의 참고하지 않았단 것을 확인할 수 있습니다. 그리고 "A Farewell to Arms"라는 제목에서도 'A'를 생성할 때만 1번 문서를 참고한 것을 확인할 수 있습니다. 이를 저자들은, parametric memory가 'Sun'이라는 글자만 보고도, 나머지 'Also Rises'라는 제목을 생각해낼 수 있는, 혹은 'A'라는 글자만 보고도 'Farewell to Arms'라는 나머지 제목을 생각해낼 수 있는 능력을 갖고 있다라고 해석하였습니다. (꼭 non-parametric memory가 모든 최종 출력 토큰에 관여하지 않는다.)
이를 통해 RAG의 non-parametric memory와 parametric memory가 서로 어떻게 협력하여 문장을 생성하는지를 알 수 있습니다.
3-4. FEVER
FEVER는 어떤 주장이 텍스트로 주어지면, 해당 주장이 사실인지 아닌지를 판별하는 분류 task 입니다. FEVER는 해당 주장이 '사실'인지 '거짓'인지를 판단해야 하는 2-way classification과, '알 수 없음'까지 3가지를 분류해야 하는 3-way classification 두 가지 분야가 있습니다.
RAG는 SoTA에 가까운 성능을 보여줬습니다. SoTA는 모델 학습에 FEVER에 주어진 관련 문서를 학습에 활용했지만, RAG는 관련 문서를 활용하지 않았음에도 유사한 성능을 보인 것이라고 합니다. 어쨌든 이를 통해 RAG가 분류 문제도 잘 풀 수 있다는 것을 증명했습니다.
또, 결과를 분석했을 때 RAG가 찾은 document가 FEVER에 주어진 gold passage와 겹치는 비율이 높았다고 합니다.(Top-1은 71%, Top-10까지 봤을 경우 90%가 겹침) 즉, gold passage를 학습에 사용하지 않더라도 retrieval가 제 역할을 충분히 잘 해내고 있단 것을 확인할 수 있었습니다.
4. 추가 분석
4-1. 언어의 다양성

RAG와 BART의 텍스트 생성 결과를 비교 분석한 결과, 위와 같이 RAG가 BART보다 더 사실적이고 세세한 답변을 내놓는 것을 확인할 수 있었습니다. 또, RAG-Sequence가 RAG-Token보다 더 다양한 언어를 사용한 결과를 내놓는 것을 확인할 수 있었습니다.

4-2. Retrieval 실험 분석
RAG 학습 방식의 효용성 확인을 위해 다양한 retrieval 설정으로 실험을 진행해 보았습니다.

BM25는 딥러닝 방식이 아닌 알고리즘 방식의 retrieval로, 두 텍스트 사이에 겹치는 단어의 비율에 따라 관련 문서를 찾습니다. RAG의 retrieval로 DPR 대신 BM25를 사용한 결과 FEVER를 제외하고 점수가 떨어지는 것을 확인할 수 있었습니다. FEVER의 경우, 데이터셋 구성이 문서와 질문 사이에 겹치는 단어가 많도록 구성되어 BM25가 더 좋은 결과를 보인 것으로 분석하고 있습니다.
또, RAG 학습 시에 retrieval에게 어떤 문서를 가져오라고 가르쳐 주지 않는 것이 효과가 있는지를 확인하기 위해, retrieval를 freeze하고 학습을 진행해 보았습니다. 결과를 보면 freeze하지 않은 것이 더 좋은 성능을 냈으며, 이는 retrieval에게 어떤 문서를 가져오라고 가르쳐 주지 않더라도 더 좋은 방향으로 학습이 진행된다는 것을 보여줍니다.
4-3. Index hot swapping
논문엔 신기한 실험이 한 가지 더 있습니다. RAG의 non-parametric memory를 2016년도의 위키문서로 학습 시킨 뒤에, 추가 학습 없이 소스를 2018년도 위키문서로 교체하고 2016년에서 2018년 사이에 교체된 세계의 대통령 이름과 관련한 질문들에 대해 대답해보도록 한 것입니다.
| source: 2016 wiki | source: 2018 wiki | |
| 2016년도 대통령의 이름을 맞춘 비율 | 0.68 | 0.04 |
| 2018년도 대통령의 이름을 맞춘 비율 | 0.12 | 0.70 |
결과는 위 표와 같이, 추가 학습 없이 문서들의 내용을 2016년에서 2018년으로 업데이트 한 것만으로 2018년도 대통령의 이름을 맞추는 것을 확인할 수 있었습니다. 즉, RAG는 시간에 따라 정보가 변화하더라도 추가 학습 없이 비교적 쉽게 모델 업데이트가 가능하다는 것입니다. 지속적인 모델 업데이트가 꽤나 골치 아픈 문제란 것을 생각하면 엄청난 이점으로 보입니다.
5. 정리
RAG는 retrieval(non-parametric memory)와 generator(parametric memory)가 결합된 모델입니다.
두 모델이 결합됨으로써, 기존의 generator-only 모델에 비해 더 사실적이고 세세한 텍스트를 생성해낼 수 있었습니다. 이는 기존 생성 모델의 큰 문제점이었던 hallucination을 어느정도 해결할 수 있을 뿐더러, retrieval를 활용하기 때문에 좀 더 해석 가능한 결과를 얻을 수 있습니다. 한 발 더 나아가, 시간이 지남에 따라 업데이트 되는 정보들을 모델과 함께 업데이트 하기에도 용이합니다.
최근 chatGPT에서 자주 등장하는 hallucination 문제의 해결의 단서가 된다는 점이나, 항상 골치인 모델의 업데이트 문제를 해결하기 위한 단서가 제시되어 있다는 점에서 상당히 읽을만한 논문이었던 것 같습니다.