[딥러닝 기초] 활성화 함수 (Activation function)
활성화 함수의 필요성
딥러닝 모델의 성능을 높이는 방법 중 하나는 레이어의 깊이를 늘리는 것입니다.

위 그림의 모델 수식은 아래와 같이 쓸 수 있습니다.
$$ y=w_3(w_2(w_1x+b_1)+b_2)+b_3=w_3w_2w_1x+w_3w_2b_1+w_3b_2+b_3 $$
그러나 이 모델을 자세히 본다면, 사실상 weight가 $w_3w_2w_1$이고 bias가 $w_3w_2b_1+w_3b_2+b_3$인 하나의 뉴런으로 이루어진 모델과 같다는 걸 알 수 있습니다.

즉, 뉴런을 아무리 깊이 쌓아봤자 사실상 뉴런 하나짜리 모델과 크게 다르지 않게 되는 것입니다.
이를 해결하기 위해 사용하는 것이 '활성화 함수(activation function)'입니다.
앞서 봤듯이, 선형 함수(wx+b와 같이 그래프 형태가 직선 형태인 함수)를 아무리 모델을 깊게 설계해봤자 크게 의미가 없게 됩니다. 활성화 함수는 이 선형 함수를 비선형 함수 형태로 바꿔주는 역할을 합니다.
활성화 함수의 종류에 대해 알아보고 실제로 성능을 실험해보는 식으로 진행해 보겠습니다.
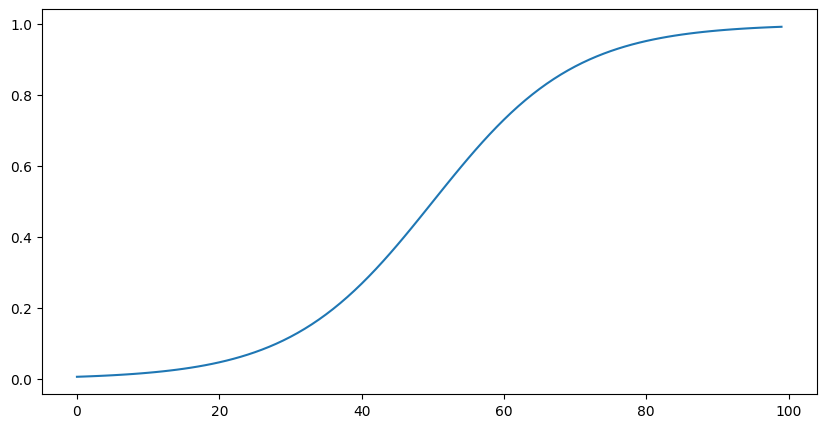
Sigmoid
Sigmoid 함수는 다음과 같습니다.
$$ \sigma(z)={1\over 1+e^{-z}} $$
Sigmoid를 사용하면 모든 값의 범위가 0에서 1사이의 범위로 제한됩니다.
Tanh
Tanh(Hyperbolic Tangent) 함수는 다음과 같습니다.
$$ tanh(z)={e^z-e^{-z}\over e^z+e^{-z}} $$
Tanh를 사용하면 모든 값의 범위가 1에서 -1 사이의 값으로 변환됩니다.

ReLU
Sigmoid와 Tanh도 아주 훌륭하지만, 두 활성화 함수 모두 뉴런의 출력값 z가 너무 크거나 작아질 경우에 도함수가 0에 가까워져 학습이 더뎌지게 되는 문제가 발생할 수 있습니다.
$$ ReLU(z)=max(0,z) $$
ReLU는 음수값들을 모두 0으로 바꾸는 역할을 합니다. 이를 이용하면 양수에서의 도함수가 0이 될 걱정은 없게 됩니다.
ReLU는 현재 가장 많이 사용되는 활성화 함수입니다.

그런데 ReLU는 굳이 보자면 선형 함수에 가깝지 않나요? 활성화함수로써의 역할을 제대로 수행할 수 있을까요?
관련된 좋은 글이 있어서 소개 드립니다.
간단히 요약하자면, ReLU 자체는 선형 함수에 가깝지만, 그 수가 많이 쌓였을 땐 다른 활성화 함수와 마찬가지로 비선형 그래프 형태를 만들 수 있다는 것입니다. 그리고 음수값들을 0으로 바꿔주는 것이 모델의 추론에 필요 없는 정보들을 필터링해주는 역할도 해줄 수 있습니다.
Softmax
분류에 사용되는 Softmax도 활성화 함수입니다.
$$p_i={e^{z_i}\over\Sigma^k_{j=1}e^{z_j}},(i=1,2,...,k)$$
Softmax는 모델이 출력한 확률 분포의 값들을 0과 1사이 범위로 제한하여 총합이 1이 되도록 하는 역할을 합니다.
여기에 자연 상수 $e$를 사용하는 이유는 다음과 같습니다.
- $e^x$ 꼴은 Probability 값을 항상 양수로 만들어줍니다.
- $e^x$는 x의 값이 커질수록 그 값이 더 커집니다. 따라서 높은 확률값을 더 강조하는 효과를 얻을 수 있습니다.
- $e^x$의 미분은 $e^x$로 미분이 굉장히 쉽습니다.
실험
MNIST 학습 모델에서 활성화 함수의 효과를 직접 실험해 보겠습니다.
https://drive.google.com/file/d/1P_qk34g-VJqklPZkniipa0LRrXDaVlci/view?usp=sharing
서로 다른 활성화 함수를 사용하는 4개의 모델을 실험할 것입니다.
import torch.nn as nn
model1 = nn.Sequential(
nn.Linear(28*28, 256),
nn.Linear(256, 128),
nn.Linear(128, 10)
)
model2 = nn.Sequential(
nn.Linear(28*28, 256),
nn.Sigmoid(),
nn.Linear(256, 128),
nn.Sigmoid(),
nn.Linear(128, 10)
)
model3 = nn.Sequential(
nn.Linear(28*28, 256),
nn.Tanh(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 10)
)
model4 = nn.Sequential(
nn.Linear(28*28, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 10)
)그 외의 조건은 다음과 같이 모두 통일했습니다.
- optimizer : Adam
- learning rate : 1e-3
- batch size : 16
- epoch : 3
- random seed : 16
실험 결과 테스트셋에 대한 정확도는 다음과 같이 나타났습니다.
| 모델1 (no activation) | 90.94% |
| 모델2 (sigmoid) | 97.14% |
| 모델3 (Tanh) | 97.35% |
| 모델4 (ReLU) | 97.39% |
활성화 함수를 추가하는 것만으로도 활성화 함수를 사용하지 않은 모델과 7%가량의 성능 차이가 발생했습니다.
또, 활성화 함수 중에서도 sigmoid < tanh < ReLU 순으로 성능이 더 좋았습니다.
(당연히 이런 결과가 다른 데이터, 모델에서도 절대적인 것은 아닙니다. 다만 대체로 ReLU가 가장 좋기는 합니다.)