[딥러닝 기초] Convolutional neural network (CNN)
Dense layer(Fully connected layer, Linear layer)는 딥러닝 모델로서 훌륭한 성능을 보여줍니다. 특히 이들의 차원 수를 늘리거나 깊이를 늘리는 방식으로 그 성능을 더 높일 수 있었습니다.
그러나 dense layer는 깊게 쌓을수록 파라미터 수가 기하급수적으로 증가하고 이로 인해 메모리 증가, 학습 속도 저하 등의 문제가 생길 수 있습니다.
간단히 256차원의 dense layer를 5개만 쌓더라도 파라미터 수가 $256^5$개로 감당할 수 없는 숫자가 됩니다.
'좀 더 효율적으로 파라미터를 사용할 수는 없을까?' 해서 등장한 것이 convolution layer입니다. 기존의 dense layer가 모든 input 값마다 서로 다른 파라미터가 관여하는 구조라면, convolution layer는 이를 좀 더 지역적으로 보는 것입니다.

Convolutional Neural Network(CNN)은 어떻게 데이터를 처리하고, DNN에 비해서 파라미터를 어떻게 획기적으로 줄일 수 있는지, 어떻게 활용되는지 등등 모든 것들을 알아보도록 하겠습니다.
Convolutional Neural Network (CNN)
CNN은 입력값에 '필터'를 씌우는 것과 같습니다.

위 그림과 같이 5차원 벡터가 입력으로 주어졌을 때, CNN은 필터(mask)를 입력값에 돌아가면서 dot-product를 이용해 적용합니다.
만약 위와 같은 결과를 dense layer를 통해 얻고자 했다면 5*3=15개의 파라미터가 필요했을 것입니다. 그러나 convolution layer는 3개의 파라미터만으로 위와 같은 결과를 얻을 수 있습니다.
Convolution layer의 필터는 차원 수를 증가시킴으로써 2차원 이미지에도 적용이 가능합니다. 이전의 MNIST 문제에서 딥러닝을 적용하기 위해 일자로 이미지를 펴주는 작업을 수행했었지만, convolution layer를 이용하면 이미지를 그대로 사용할 수 있습니다.

Convolution layer는 위 그림과 같이 5*5 크기의 input에 3*3 크기의 필터를 적용함으로써 2*2 크기의 output을 내는 식으로 활용이 가능합니다. 직관적으로는, 필터가 입력 이미지로부터 중요한 정보들을 추려내는 작업을 하는 것과 같다고 볼 수 있습니다.
파라미터 수 역시, 기존 dense layer를 사용한다면, 5*5개의 input에서 2*2개의 output 정보를 얻기 위해선 5*5*2*2=100개의 파라미터가 필요하지만 convolution layer는 9개만의 파라미터로 이를 수행해낼 수 있습니다.
아무리 convolution layer가 효율적인 모델 구성을 위한 것이라 해도, 100개의 파라미터가 하던 일을 9개의 파라미터만으로 수행할 수 있다고 하는 것은 무리가 있을 수도 있습니다. Convolution layer의 파라미터 수를 늘리는 방법으로는 필터의 크기를 늘리거나 수를 늘리는 방법이 있습니다.
필터의 수를 늘리는 방법을 사용할 경우, 다음과 같이 적용할 수 있습니다.

5*5 크기의 input에 3*3 크기의 필터를 3개를 적용할 경우, 2*2 크기의 output 3개를 얻을 수 있습니다. 파라미터 수 역시 3*3*3=27개로 늘리면서 더 다양한 정보를 파악할 수 있습니다. 필터의 수는 출력 레이어의 채널 수를 결정합니다. 직관적인 의미로는 필터마다 서로 다른 정보를 이미지로부터 취하는 것과 같습니다.
필터의 크기도 3*3뿐만 아니라 5*5, 128*128 이런 식으로 늘릴 수 있습니다. 다만 효율성이 떨어지기 때문에 현재는 3*3 필터를 사용하는 것이 정석으로 받아들여지고 있습니다. 이에 대해서는 padding과 stride에 대해 설명한 뒤에 다시 설명하겠습니다.
지금까지의 예시는 입력 채널이 하나인 흑백 이미지가 input인 예시입니다. 일반적으로 이미지들은 보통 RGB 3채널로 이뤄진 칼라 이미지가 많죠. 이런 경우엔 채널까지 포함하여 3차원 크기의 마스크를 적용할 수 있습니다.

3차원 필터를 사용하지만 이를 2d convolution이라고 합니다. 2d 이미지에 적용하는 필터이기 때문에 2d구나 하고 생각하면 좋습니다. 이전까지 봤던 2차원 필터를 적용하는 것은 1d convolution이 되겠죠.
Stride와 Padding
Convolution filter를 적용하는데는 stride와 padding이라는 2개의 옵션을 설정할 수 있습니다.
Stride는 '필터를 몇 칸 간격으로 움직일 것인가'를 나타냅니다.
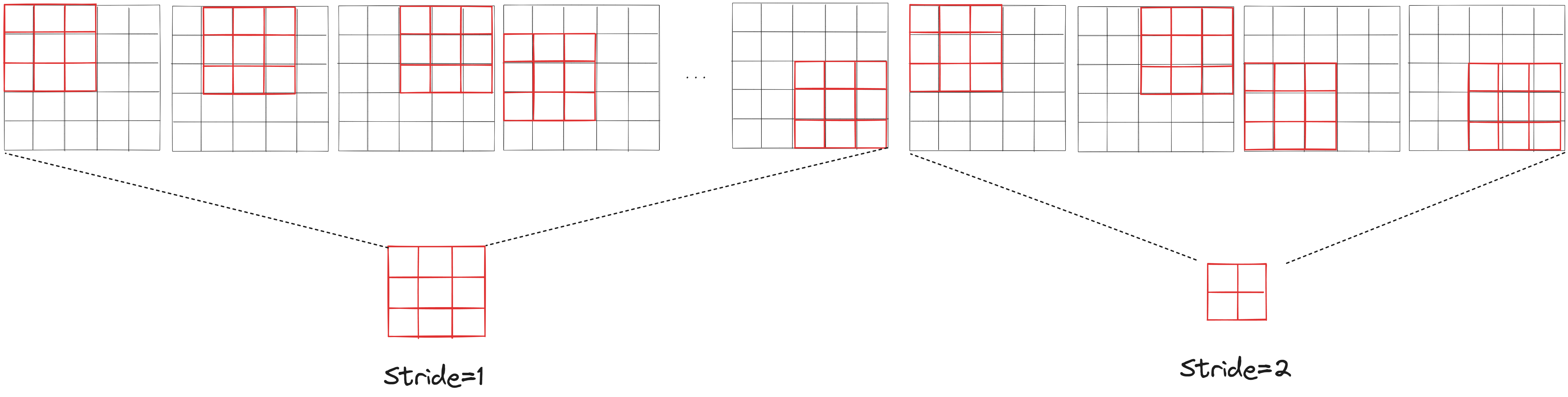
위 그림을 보면 알겠지만 stride에 따라서 같은 필터 크기라도 출력되는 결과물의 크기가 달라집니다.
Padding은 입력 이미지의 크기를 확장합니다. 왜 input의 크기를 확장할까요?

위 그림과 같이, padding을 통해 output의 크기를 줄이지 않고 convolution 연산을 수행할 수 있게 됩니다. 만약 padding을 사용하지 않는다면 convolution 연산을 진행할수록 이미지의 크기가 줄어들게 될 것입니다. 그렇기 때문에 padding을 사용해 이미지의 크기를 유지시켜줄 필요가 있습니다.
그렇다면 padding한 공간에는 어떤 값들이 들어갈까요? 여러가지 방법이 있지만 가장 많이 사용되는 방법은 0으로 채우는 것입니다. Padding의 의미는 output의 크기를 유지하기 위함인데 다른 값이 들어가서 output의 값에 영향을 주면 좀 그렇겠죠?
CNN 모델을 설계하기 위해선 Padding과 Stride를 적절히 사용해 이미지의 크기를 조절해주는 것이 필요합니다. 그러기 위해선 stride와 padding을 설정했을 때 출력될 이미지의 크기를 계산할 수 있어야겠죠. 이미지의 크기는 다음과 같은 수식으로 계산할 수 있습니다.
$$ (OH,OW)=({H+2P-FH\over S}+1,{W+2P-FW\over S}+1) $$
Padding 수치를 $P$, Stride 수치를 $S$, 필터의 너비와 높이를 $FW$, $FH$라고할 때, input의 너비(W)와 높이(H)에 대한 output의 너비(OW)와 높이(OH)는 위와 같이 계산할 수 있습니다.
만약 $H+2P-FH$나 $W+2P-FW$가 $S$로 나눠 떨어지지 않는 경우엔 소수점을 떼고 값을 내려주면 됩니다. (${5\over2}:=2$)
여기서 통상적으로 필터의 크기는 3*3, padding은 1로 많이 설정합니다. 이 경우 위 수식은 아래와 같이 될 것입니다.
$$(OH,OW)=({H-1\over S}+1,{W-1\over S}+1) $$
이 경우, stride를 1로 설정한다면 input과 output의 크기가 같아지게 되고, stride를 2로 설정한다면 output의 크기는 input의 크기의 절반이 될것입니다. Output의 크기를 계산하기가 굉장히 쉬워지죠.
필터의 크기
앞서 말했듯 필터 크기는 3*3으로 적용하는 것이 일반적입니다. 그 첫번째 이유는 padding과 stride를 통해 output의 크기를 편하게 계산하기 위함도 있습니다. 또 다른 이유는 필터의 크기를 키우는 것이 비효율적이기 때문입니다.
100*100 크기의 input 이미지가 주어졌을 때, 5*5 convolution filter를 stride=1, padding=0으로 적용해 보겠습니다. Output의 크기는 다음과 같이 계산될 겁니다.
$(OH,OW)=({100+2*0-5\over1}+1,{100+2*0-5\over1}+1)=(96,96)$
3*3 필터를 이용한다면 어떻게 될까요?
$(OH,OW)=({100+2*0-3\over1}+1,{100+2*0-3\over1}+1)=(98,98)$
5*5 필터를 한번 적용한 것과 같이 96*96 크기의 output을 내기 위해선 3*3 필터를 한 번 더 적용해야 합니다.
$(OH,OW)=({98+2*0-3\over1}+1,{98+2*0-3\over1}+1)=(96,96)$
결과적으로 100*100 크기의 input을 받아 96*96 크기의 output을 출력하고자 한다면, 5*5 필터는 한 번, 3*3 필터는 두 번 적용해야 합니다. 이 때 사용된 파라미터의 수를 비교해 볼까요? 5*5 필터를 한 번 적용한 경우엔 5*5=25개의 파라미터가 사용됩니다. 그러나 3*3 필터를 두 번 사용한 경우엔 3*3*2=18개의 파라미터가 사용됩니다. 즉, 같은 크기의 output을 내는데 3*3 필터를 적용하는 것이 더 적은 파라미터를 사용하는 것입니다. 따라서 3*3보다 더 큰 필터를 사용하는 것은 효율성이 떨어지기 때문에 3*3 필터를 주로 사용합니다.
Convolution layer의 bias
뉴런의 구성은 weight와 bias로 이루어져 있습니다. y=wx+b와 같이 말이죠. 지금까지는 편의를 위해 weight만 고려하여 CNN을 설명하고 있었습니다. CNN에서 bias는 필터마다 하나씩이라고 생각하면 됩니다.

Pooling Layer
CNN 모델을 구성할 때 convolution layer와 함께 빠지지 않는 친구가 하나 있습니다. 바로 pooling layer입니다. Pooling 레이어 역시 출력층의 크기를 조절하기 위해 사용됩니다. Pooling layer 역시 필터를 사용합니다. 다만 convolution layer와의 차이점은 pooling 레이어에는 학습 가능한 파라미터가 존재하지 않습니다.
Pooling layer는 필터 크기만큼의 범위에서 가장 중요한 값을 추출합니다. 이 중요한 값을 추출하는 방식에 따라 MaxPooling과 MeanPooling으로 나눠집니다.

위 그림과 같이 MaxPooling은 필터 범위의 최댓값을 추출합니다. 그리고 MeanPooling은 해당 범위 값들의 평균값을 추출합니다.
Pooling layer 역시 필터의 크기, stride, padding을 설정할 수 있습니다. 보통은 stride=2, padding=1로 하여 이미지의 크기를 절반으로 줄이는데 많이 사용됩니다.
Dense layer와 convolution layer
Convolution layer의 개념을 넓게 살펴보면, dense layer 역시 convolution layer의 일종이라고 볼 수 있습니다. Dense layer는 사실 1*1 크기의 필터를 사용하는 convolution layer와 같기 때문이죠.

3*3 크기의 input은 1*1*9 크기로 형태를 변환시킬 수 있습니다. 이는 가로 세로 길이가 1인, 9개의 채널로 이뤄진 이미지와 같이 생각할 수 있습니다.
9개의 input을 이용해 1개의 output을 출력하기 위해 dense layer를 사용한다면, 9*1 크기의 weight 행렬을 사용할 수 있습니다. 이는 1*1*9 크기의 필터를 하나 사용하는 2d convolution과 같이 생각할 수 있습니다.
즉, dense layer는 convolution layer의 장점을 하나도 활용하지 않는 convolution layer와 같습니다.
실습 코드
이제 CNN의 성능을 직접 확인해 볼 시간입니다.
https://colab.research.google.com/drive/1tBEqHOyZB3E4ztuRLXBUxhMIUMKw8BXS?usp=sharing
Convolutional Neural Network.ipynb
Colaboratory notebook
colab.research.google.com
코드는 위 colab 링크에서 확인할 수 있습니다.
이번에도 역시 MNIST를 사용할 건데요, 이전에 사용했던 dense layer 위주의 모델과 CNN 모델을 비교해 보려고 합니다.
import torch
import numpy as np
import random
def set_seed(random_seed):
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
set_seed(16)똑같은 실험 결과를 얻기 위해서 랜덤 시드들을 고정했습니다.
import torchvision.datasets as datasets
mnist_train = datasets.MNIST(root='MNIST_data/',
train=True,
download=True)
mnist_test = datasets.MNIST(root='MNIST_data/',
train=False,
download=True)
from torch.utils.data import Dataset, DataLoader
class mnist_dataset(Dataset):
def __init__(self, data):
super(mnist_dataset, self).__init__()
self.images = data.data
self.labels = data.targets
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
return {
"images": self.images[idx].unsqueeze(0)/255,
"labels": self.labels[idx]
}
train_dataset = mnist_dataset(mnist_train)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataset = mnist_dataset(mnist_test)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)이번엔 2d Convolution을 이용한 모델에서 데이터를 처리할 계획입니다. 그렇기 때문에 데이터의 형태도 2d convolution 레이어에 알맞게 전처리를 다르게 해줘야 합니다.
__getitem__ 함수를 보시면, 이미지 전처리를 이전과 다르게 한 것을 확인할 수 있습니다.
# for dense layer
"images": self.images[idx].view(-1)/255
# for convolution layer
"images": self.images[idx].unsqueeze(0)/255이전엔 dense layer에 이미지를 넣기 위해서 이미지를 일자 형태로 펴주는 전처리를 수행했었습니다. 그러나 2d convolution은 2d 이미지를 처리할 수 있기 때문에 일자로 펴줄 필요가 없습니다.
그리고 2d convolution을 적용하기 위해선 채널이 필요하죠. MNIST는 흑백 이미지이기 때문에 1채널입니다. 채널 수를 표현하기 위해 .unsqueeze(0)를 통해 이미지의 차원을 (28, 28) 에서 (1, 28, 28)로 변환해 주었습니다.
(unsqueeze는 squeeze의 반대로 차원 수를 늘려주는 역할을 합니다. '0'은 맨 첫번째 자리의 차원을 늘려주겠다는 뜻입니다.)
다음으로 모델 코드를 보겠습니다. 편의를 위해 지난번과 다르게 Sequential()을 이용하지 않고 클래스를 새로 만들었습니다. PyTorch에서 모델을 만드는 방법은 Sequential()을 사용하는 방법과 nn.Module을 상속받아 클래스를 만드는 방법이 있습니다. Sequential()은 방식이 간단한 대신 여러가지 모델 설계에 제약이 많기 때문에 정말 간단한 모델을 만드는데 사용됩니다.
클래스를 이용해 모델을 만드는 방법은 위와 같이 nn.Module을 상속 받아 클래스를 만들면 됩니다.
클래스의 생성자에는 모델에 필요한 레이어들을 정의하면 되고, forward() 함수는 모델에 input이 들어왔을 때, 이를 어떻게 처리하면 될지를 정의하면 됩니다.
import torch
import torch.nn as nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(3, 3), stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(3, 3), stride=1, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=(2,2), stride=2)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=16, kernel_size=(3, 3), stride=1, padding=1)
self.conv4 = nn.Conv2d(in_channels=16, out_channels=16, kernel_size=(3, 3), stride=1, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=(2,2), stride=2)
self.dense = nn.Linear(7*7*16, 10)
self.relu = nn.ReLU()
def forward(self, inputs):
batch_size = inputs.shape[0]
x = self.conv1(inputs)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool1(x)
x = self.conv3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.relu(x)
x = self.pool2(x)
x = x.view(batch_size, -1)
outputs = self.dense(x)
return outputs
def test_shape(self, input_shape=(16, 1, 28, 28)):
dummy_inputs = torch.randn(input_shape)
batch_size = input_shape[0]
print("Input shape :", input_shape, "\n")
with torch.no_grad():
x = self.conv1(dummy_inputs)
print(self.conv1)
print("output shape :", x.shape, "\n")
x = self.conv2(x)
print(self.conv2)
print("output shape :", x.shape, "\n")
x = self.pool1(x)
print(self.pool1)
print("output shape :", x.shape, "\n")
x = self.conv3(x)
print(self.conv3)
print("output shape :", x.shape, "\n")
x = self.conv4(x)
print(self.conv4)
print("output shape :", x.shape, "\n")
x = self.pool2(x)
print(self.pool2)
print("output shape :", x.shape, "\n")
x = x.view(batch_size, -1)
print("Reshape Tensor")
print("output shape :", x.shape, "\n")
outputs = self.dense(x)
print(self.dense)
print("output shape :", outputs.shape)제가 임의로 Conv2d와 MaxPool2d를 이용해 모델을 작성했는데, 직접 커널 크기나 padding, stride 수치 등을 조절해보면서 중간중간 크기가 어떻게 변화하는지 확인해 보시기 바랍니다. (이를 위해서 test_shape() 함수를 추가했습니다.)
주의할 점은, 마지막에 .view()를 통해 이미지를 일자로 편 뒤에, 이를 linear 레이어에 입력으로 제공하는데, 여기서 linear 레이어의 input dimension을 직접 입력해야 합니다. 즉, 변경하신 convolution setting으로 인해 어떤 shape이 최종적으로 나타났으며, 이를 일자로 편 tensor의 dimension이 어떻게 되는지를 계산해서 올바르게 적어야 오류가 발생하지 않습니다.
'''
convolution layer를 수정할 경우, 여기에 7*7*16이 아니라 다른 값이 들어가게 될 수 있으니
잘 계산해서 수정해야 합니다.
'''
self.dense = nn.Linear(7*7*16, 10)현재의 구조는 다음과 같습니다.

Convolution과 MaxPooling을 적절히 활용하여 이미지 정보를 추렸고, 마지막에 .view()를 활용하여 이미지를 다시 일자로 펴주는 작업을 수행했습니다. 이유는 모델이 출력해야 하는 결과는 이미지가 아니라 10개의 tensor로 이뤄진 벡터이기 때문입니다.
'지금까지 기껏 convolution layer의 효용성에 대해 설명하고, dense layer도 사실 convolution layer와 같다는 둥 설명을 하고 마지막엔 결국 dense layer를 쓰는거냐!' 하고 생각이 드셨다면 이 dense layer 역시 convolution layer로 대체가 가능하다는걸 알려드리며, 더 자세한게 궁금하다면 'fully convolutional network'에 대해 찾아 보시는걸 추천 드립니다.
from torch.optim import Adam
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)다음으로 학습 세팅을 하고, 학습을 수행해 보겠습니다.
from sklearn.metrics import accuracy_score
from tqdm import tqdm
train_losses = []
for epoch in range(3):
print("epoch :", epoch)
model.train()
train_loss = []
for step, data in enumerate(tqdm(train_loader)):
data = {k: v.to(device) for k, v in data.items()}
images = data["images"].float()
output = model(images)
loss = criterion(output, data["labels"])
train_loss.append(loss.detach().cpu().item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step%1000==0 and step > 0:
step_loss = sum(train_loss)/len(train_loss)
print(f"{step} loss :", step_loss)
train_losses.append(step_loss)
train_loss = []
model.eval()
outputs = []
for data in tqdm(test_loader):
data = {k: v.to(device) for k, v in data.items()}
images = data["images"].float()
with torch.no_grad():
output = model(images)
outputs.append(output.cpu())
outputs = torch.cat(outputs, dim=0)
preds = torch.argmax(outputs, dim=-1)
acc = accuracy_score(preds, mnist_test.targets)
print(f"model accuracy on test set : {acc*100}")기본 모델로 학습을 수행하면, test셋에 대해서 정확도가 98.85가 나오는 것을 확인할 수 있습니다. 저번 '활성화 함수' 편에서 ReLU를 사용한 dense layer의 정확도가 97.39였던 것보다 성능이 1.5점 가량 향상되었습니다.
더 놀라운건, 저번 DNN 모델과 이번 CNN 모델의 파라미터 수는 몇개일까요?
연습을 위해 직접 계산해 보셔도 좋고, 쉽게 확인하기 위해 'torchsummary'라는 라이브러리를 활용해 보겠습니다.
!pip install torchsummarytorchsummary는 colab에 설치되어 있지 않기 때문에 위와 같이 설치를 해주어야 합니다.
사용법은 아래와 같습니다.
import torchsummary
torchsummary.summary(model, input_size=(1, 28, 28))
'''
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 28, 28] 320
ReLU-2 [-1, 32, 28, 28] 0
Conv2d-3 [-1, 32, 28, 28] 9,248
ReLU-4 [-1, 32, 28, 28] 0
MaxPool2d-5 [-1, 32, 14, 14] 0
Conv2d-6 [-1, 16, 14, 14] 4,624
ReLU-7 [-1, 16, 14, 14] 0
Conv2d-8 [-1, 16, 14, 14] 2,320
ReLU-9 [-1, 16, 14, 14] 0
MaxPool2d-10 [-1, 16, 7, 7] 0
Linear-11 [-1, 10] 7,850
================================================================
Total params: 24,362
Trainable params: 24,362
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.92
Params size (MB): 0.09
Estimated Total Size (MB): 1.01
----------------------------------------------------------------
'''torchsummary.summary의 첫번째 인자에는 확인하려는 모델을, 두번째 input_size 인자에는 모델의 입력 사이즈를 입력하면 됩니다.
확인해 보면, CNN 모델은 24,362개의 파라미터가 사용되었습니다. 그런데 DNN 모델은..?
dense_model = nn.Sequential(
nn.Linear(28*28, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 10)
).to(device)
torchsummary.summary(dense_model, (1, 28*28))
'''
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 1, 256] 200,960
ReLU-2 [-1, 1, 256] 0
Linear-3 [-1, 1, 128] 32,896
ReLU-4 [-1, 1, 128] 0
Linear-5 [-1, 1, 10] 1,290
================================================================
Total params: 235,146
Trainable params: 235,146
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 0.90
Estimated Total Size (MB): 0.91
----------------------------------------------------------------
'''
235,146개로 CNN 모델의 10배가 사용되었음에도, 정확도가 더 떨어지는 것을 확인할 수 있습니다.
이는 CNN 레이어가 이미지를 처리하는데 특화되어 있을 것이다라는 생각을 입증하며, 실제로 이미지 처리에선 CNN이 정석적으로 사용되고 있습니다.
마지막으로 CNN의 또 다른 장점은, 모델이 어떻게 이미지를 인식하고 추론하는지를 시각화해볼 수 있다는 것입니다.
import matplotlib.pyplot as plt
sample = train_dataset[0]['images']
with torch.no_grad():
x = model.conv1(sample.to(device))
x = model.relu(x)
x = model.conv2(x)
x = model.relu(x)
x = model.pool1(x)
# x = model.conv3(x)
# x = model.relu(x)
# x = model.conv4(x)
# x = model.relu(x)
# x = model.pool2(x)
fig, ax = plt.subplots(4, 4, figsize=(10, 10))
for i in range(4*4):
ax[i//4][i%4].imshow(x[i].cpu())위와 같은 코드로, 모델 중간 레이어에서 출력한 결과가 어떤지 시각화 해보면, CNN의 각 필터가 이미지의 어떤 부분을 분석하고 있는지를 확인할 수 있습니다.

보면 필터마다 이미지에서 중점적으로 보는 것이 저마다 다르다는 것을 확인할 수 있습니다. 신기하지 않나요?
이는 딥러닝 모델이 어떤 식으로 학습되고 있고, 왜 이런 결과를 내는지 분석하는데 중요한 단서가 될 수 있습니다.
이렇게 Convolution layer에 대해서 알아봤습니다. Convolution layer는 dense layer보다 효율적으로 파라미터를 사용할 수 있습니다. 또 2d convolution은 이미지를 처리하는데 특화되어 있습니다.