FASTSPEECH 2: FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH
이번엔 또 다른 TTS 모델 FastSpeech2에 대해서 알아보겠습니다. FastSpeech2의 특징이라고 하면 우선 빠릅니다. Self-attention 구조를 통해 mel-spectrogram을 순차적이 아닌 병렬적으로 만들어내기 때문에 훨씬 빠를 수 있습니다. 또 text에서 바로 waveform을 만들 수 있는 fastspeech2s에 대한 연구도 포함되어 있습니다.
1. 모델의 input과 output
FastSpeech2는 4개의 input을 필요로 합니다.
- text : 말 그대로 텍스트입니다. 글자를 잘못 발음하는 문제를 해결하기 위해 grapheme-to-phoneme 오픈소스 툴을 이용해 문장을 소리나는대로 바꿔주는 작업을 거쳤다고 합니다. ("오늘은 날씨가 좋군요." -> "오느른 날씨가 조쿤뇨.")
- duration : 음소의 길이 정보가 필요합니다. 사람이 말할 때 각 글자마다 소리의 길이 정보를 모델에 입력으로 제공합니다. FastSpeech에서는 음소의 길이 추출을 위해 사전학습된 TTS 모델을 활용했지만, FastSpeech2에서는 Montreal Forced Aligner(MFA)라는 툴을 사용합니다.
음소 길이는 mel-spectrogram의 길이에 맞춰서 제공됩니다. 만약 입력된 음소가 4글자의 feature가 ($H_{pho}=[h_1,h_2,h_3,h_4]$)이고, 각 음소의 길이 $D$가 $[2,2,3,1]$이라고 주어진다면, 음소 feature를 $[h_1,h_1,h_2,h_2,h_3,h_3,h_3,h_4]$와 같이 바꿔주는 Length Regulator를 적용합니다.
이 Length Regulator를 이용해 음성의 속도도 조절이 가능한데, 만약 음성의 속도 하이퍼파라미터 $\alpha$가 0.5라면, 각 음소의 길이에 0.5를 곱한 뒤 반올림을 통해 $D=[1,1,2,1]$로 바꿔주어 결과를 $[h_1,h_2,h_3,h_3,h_4]$와 같이 더 빠른 음성으로 바꿔줄 수 있게 됩니다. - pitch : 말의 소리와 억양에 관한 정보입니다. 그러나 pitch 정보는 값의 범위가 매우 넓기 때문에 모델이 제대로 예측하는데 어려움을 겪습니다. 그렇기 때문에 continuous wavelet transform(CWT)[1]라는 것을 활용해 pitch spectrogram으로 변환하는 작업을 수행한다고 합니다.
import librosa import pyworld as pw audio, sr = librosa.load("example.wav") hop_length = config["hop_size"] pitch, t = pw.dio( audio.astype(np.double), sr, frame_period=hop_length / sr * 1000 ) pitch = pw.stonemask(audio.astype(np.double), pitch, t, sr) - energy : energy는 음성의 크기와 관련된 정보입니다. 이는 STFT 결과에서 각 frame의 진폭에 L2-norm을 적용하여 계산된다고 합니다.
import librosa audio, sr = librosa.load("example.wav") D = librosa.stft( audio, n_fft=config["n_fft"], hop_length=config["hop_size"], win_length=config["win_length"], window=config["window"], ) S, _ = librosa.magphase(D) energy = np.sqrt(np.sum(S ** 2, axis=0))
이 3개 외에도 필요에 따라 여기에 말하는 사람의 감정, 말하는 사람의 정보 등을 추가하여 학습하는 방법도 future work로써 남겨놓는다고 했습니다.
- Mel-spectrogram : FastSpeech2의 출력결과로 waveform에 STFT(Short Time Fourier Transform)을 적용한 뒤, mel-scaling을 수행한 결과물입니다. 이를 만들기 위한 하이퍼 파라미터는 다음과 같이 사용했다고 합니다.
- frame size = 1024
- hop size = 256
- sample rate = 22050
2. 모델 구조

FastSpeech2의 전체 모델구조는 위와 같이 그릴 수 있습니다. 지금부터 하나씩 뜯어보도록 하겠습니다.
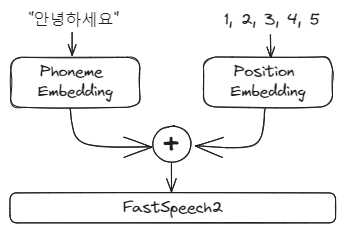
2-1. Phoneme Embedding + Positional Encoding
Phoneme Embedding 레이어는 입력 text(Phoneme)를 feature representation으로 변환해주는 임베딩 레이어입니다. 여기에 Positional Encoding이 추가되는데, 이는 텍스트들의 위치 정보를 모델에 추가로 제공해주겠다는 뜻입니다.
Tacotron2와 달리 FastSpeech2에서 위치 정보를 추가로 줘야 하는 이유는 Tacotron2와 달리 autoregressive하지 않은 attention 메커니즘을 사용하기 때문입니다. 무슨 뜻이냐 하면, Tacotron2의 경우 시퀀스를 앞에서 뒤까지 순서대로 출력하는 학습을 하면서 자연스럽게 시퀀스의 순서를 함께 학습합니다. 하지만 FastSpeech2의 경우 attention 메커니즘을 사용해 전체 시퀀스를 한번에 예측하기 때문에 시퀀스의 순서에 대한 정보를 알기 어렵습니다.

따라서 모델이 문장의 순서를 알 수 있도록, 앞에서부터 position_id를 0,1,2,....,n(문장 길이)까지 부여해 모델에 알려주는 것입니다. 문장의 길이 만큼의 숫자 배열은 임베딩 레이어를 거친 뒤, phoneme embedding의 feature에 더해지게 됩니다.
2-2. Encoder & Decoder
FastSpeech2의 인코더와 디코더는 똑같이 feed-forward Transformer block 4개로 구성됩니다. Feed-forward Transformer block은 self-attention과 1D-convolution 레이어로 구성됩니다.

Attention의 경우 시퀀스가 길어질수록 정보를 유실하던 RNN 레이어의 단점을 개선하기 위한 구조입니다. Attention은 앞에서부터 순차적으로 정보를 받던 RNN과 달리 시퀀스 전체의 정보를 입력받아 처리하는 식으로 구성되어 있는데 Transformer, BERT, GPT 등 텍스트 시퀀스를 다루는 모델들이 이 attention 구조를 사용해 큰 성능 향상을 가져온 선례가 있습니다. FastSpeech2에서도 위와 같이 self-attention과 Conv1D 레이어를 활용해 Feed-forward Transformer block을 구성하여 시퀀스 정보를 처리합니다.
2-3. Variance Adaptor
Variance adaptor는 음성의 pitch, energy, duration 정보들을 생성하는 모듈입니다. 3가지 모두 유사한 구조를 가지며(같은 구조지만 세세한 파라미터를 다르게 적용), 앞서 본 인코더에서 출력한 phoneme의 feature representation을 입력으로 받아 음성의 pitch, energy, duration 정보들을 복원한 뒤, 원래 pitch, energy, duration 정보와 비교하여 MSE Loss를 통해 학습됩니다.

Variance adaptor를 통해 예측된 pitch와 duration은 임베딩 레이어를 통해 feature representation으로 변환되어, 인코더의 output에 더해집니다.
그 뒤, 예측된 duration을 이용해 Length Regulator를 적용하여 phoneme 길이로 되어 있던 feature를 spectrogram의 길이로 변환해 줍니다.
마지막으로 스펙트로그램의 길이에 맞춰서 position_id를 한번 더 위치 정보로 제공해 줍니다.

3. FastSpeech2s
텍스트를 스펙트로그램으로 변환하는 것과 달리 바로 음성 신호로 변환하는데는 문제가 있습니다.
- 입력과 출력 간의 정보 차이 : 텍스트에서 mel-spectrogram을 만드는 것은 가능하지만 바로 waveform을 만드는 것은 어렵습니다. 이는 waveform이 mel-spectrogram보다 더 많은 정보를 담고 있기 때문입니다. 그 중에서도 특히 위상 정보(phase information)는 복구하기가 매우 어렵습니다. (위상 정보란 음성에서 나타나는 파형의 모양이라고 볼 수 있습니다.)
이전의 연구(Engel et al., 2020)에서 variance predictor(위상 정보를 예측하는 모델)로는 위상 정보를 예측하는 것이 어렵다는 것을 밝힌 적이 있습니다. 이를 해결하기 위해 FastSpeech2s는 이를 adversarial training 방식을 사용해 위상 정보를 모델이 스스로 복구하는 방법을 학습할 수 있도록 합니다. - mel-spectrogram은 오디오의 길이가 길어도 크기가 그렇게 커지지 않지만, waveform의 경우 오디오가 길어질수록 그 크기가 매우 커집니다. 그렇기 때문에 용량 문제가 발생하기 쉽습니다. 그래서 보통 학습을 위해 오디오를 작은 크기로 나눠서 학습을 하게 되는데 이럴 경우 정보 손실이 발생하게 됩니다.
잘리지 않은 전체 음성을 확인하는 능력을 기르기 위해 fastspeech2의 mel-spectrogram 디코더를 사용합니다. fastspeech2의 디코더는 텍스트 전체를 입력으로 받기 때문에 잘리지 않은 전체 음성 내용 정보를 담을 수 있습니다. 따라서 FastSpeech2의 디코더를 함께 학습하는 것만으로 모델이 음성 전체를 고려할 수 있도록 하는 효과를 받을 수 있습니다. 이 mel-spectrogram 디코더는 함께 학습되지만 fastspeech2s inference 시에는 사용되지 않습니다.

Fastspeech2s는 FastSpeech2에서 Waveform Decoder가 추가된 형태입니다. Waveform Decoder는 잘려진 음성들에 해당하는 텍스트 시퀀스들을 입력받아 해당 텍스트에 알맞는 음성 wave를 출력합니다. 구조는 다음과 같습니다.

Waveform decoder는 adversarial training을 통해 학습됩니다. 그렇기 때문에 discriminator 모델이 하나 더 필요합니다. Discirimnator는 Parallel WaveGAN 모델과 같은 구조로 설계했는데 이는 Upsample을 위한 transposed 1D-convolution과 leaky ReLU를 하나의 블럭으로 했을 때 총 10개의 블럭을 쌓은 구조입니다.
Adversarial training에는 LSGAN discriminator loss를 사용한다고 합니다. LSGAN은 기존 GAN의 gradient vanishing 문제를 해결하기 위해 손실 함수를 cross entropy loss에서 least square loss로 바꾼 형태입니다.
결과적으로 FastSpeech2s는 mel-spectrogram Decoder의 스펙트로그램을 만들어내는 loss와 Waveform Decoder의 LSGAN loss, 총 2개의 loss로 학습되게 됩니다.
4. 실험
4-1. 데이터셋
- LJSpeech Dataset
- 총 24시간 분량의 13,100개의 음성 클립.
- 평가는 테스트셋에서 100개의 샘플을 랜덤하게 추출하여 진행.
- 글자를 잘못 발음하는 문제가 없도록 문장들을 소리나는대로 바꿈. (ex. "날씨가 좋군요." -> "날씨가 조쿤뇨.")
- Mel-Spectrogram 파라미터
- frame size = 1024
- hop size = 256
- sample rate = 22050
4-2. 모델 파라미터

4-3. Training 설정
FastSpeech2
- GPU : 1 NVIDIA V100
- batch size : 48
- optimizer : Adam($\beta_1=0.9,\beta_2=0.98,\epsilon=10^{-9}$)
- Transformer와 같은 learning rate scheduler 사용.
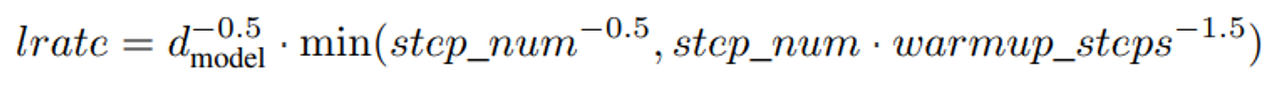
learning rate shceduler - 총 16만 step 훈련.
- Vocoder(스펙트로그램을 waveform으로 변환하는 모델) : 사전학습된 Parallel WaveGAN.
FastSpeech2s
- GPU : 2 NVIDIA V100
- batch size : 6
- 음성 길이는 20,480 샘플 크기 기준으로 자름.
- adversarial training 방식은 Parallel WaveGAN의 방식을 따름.
- 총 60만 step 훈련.
- 그 외에는 fastspeech2와 동일.
4-4. 실험 결과


저는 위의 2가지 결과에 주목했습니다. MOS 수치의 경우 FastSpeech2가 가장 실제 음성의 MOS와 유사하게 높은 수치를 보였습니다. 그와 동시에 아래의 추론 속도를 보면 FastSpeech2가 앞의 모델들보다 훨씬 빠르다는 것을 알 수 있습니다.
사실 MOS 수치가 앞선다는 것은 사람들이 직접 청중 평가를 수행하는 것이기 때문에 다른 모델들보다 조금 더 앞선다고 해서 큰 인상을 주지는 않습니다. 하지만 기존 모델들과 비슷하거나 더 높은 성능을 내면서 추론 속도가 훨씬 빠른 것은 꽤 인상적이었습니다.