[NLP-1] 인공지능이 텍스트를 처리하는 방법
NLP란?
NLP(Natural Language Processing)는 인공지능을 이용해 사람의 언어를 처리하는 연구분야 입니다. 언어를 처리하는 task에는 여러 종류가 있습니다. 감정 분석, 챗봇, 텍스트 요약, QA 등 다양한 task가 존재하죠. 인공지능은 언어를 어떻게 인식하고 처리하는지, 문제를 어떤 식으로 해결하는지에 대해서 차차 알아가 보도록 합시다. 오늘은 네이버 영화 리뷰 감성 분석 task를 해결하는 과정을 살펴보면서 NLP task의 해결 과정에 대해서 감을 잡아 보도록 하겠습니다.
NSMC
NSMC는 네티즌들이 네이버 영화에 남긴 영화 리뷰 댓글들의 감성을 분류하는 task입니다. 각 리뷰의 점수에 따라 해당 리뷰가 영화에 대해 긍정적인(1) 리뷰인지 부정적인(0) 리뷰인지를 나타내는 라벨이 부여되어 있습니다. 리뷰 점수가 9점 이상이면 긍정으로, 1~4점 이면 부정으로 분류했다고 합니다.
데이터셋은 총 20만 개의 댓글을 수집했으며, 15만 개의 댓글을 훈련 셋으로, 5만 개의 댓글을 테스트 셋으로 구성했으며 긍정과 부정의 비율은 반반으로 맞췄다고 합니다. 데이터셋은 아래 링크에서 확인할 수 있습니다.
GitHub - e9t/nsmc: Naver sentiment movie corpus
Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub.
github.com
그럼 지금부터 NSMC를 해결해 봅시다!
https://colab.research.google.com/drive/1RBRKaeV1Akj1IC8rJrDcIL-JcYAGL3jd?usp=sharing
nsmc_Moview_Review_1.ipynb
Colaboratory notebook
colab.research.google.com
코드는 위 colab 링크에서 확인 가능합니다.
데이터셋 확인하기
데이터셋은 txt 형식으로 저장되어 있습니다. 텍스트 파일을 읽을 땐 아래와 같이 불러올 수 있습니다.
with open("nsmc/ratings_train.txt", "r", encoding="utf-8") as f:
ratings_train = f.readlines()
with open("nsmc/ratings_test.txt", "r", encoding="utf-8") as f:
ratings_test = f.readlines()
print(len(ratings_train), len(ratings_test))
ratings_train[:10] # 0 - negative, 1 - positive

첫번째 줄에 제목 행이 있으며 id, document, label 정보가 담겨 있습니다. 각 열은 탭("\t")으로 구분되어 있으며 행은 줄바꿈("\n")으로 구분됩니다. 우선 제목행은 필요 없으니 빼고 가겠습니다.
# 제목 행은 제거
ratings_train = ratings_train[1:]
ratings_test = ratings_test[1:]데이터가 어떻게 생겼는지 알았으니 이제 모델에 입력하기 위해 데이터를 전처리 해보겠습니다. 인공지능 모델은 하나의 거대한 수식과 같습니다. 수식에는 숫자만 들어갈 수 있으니 이 텍스트들도 숫자로 바꿔줘야 합니다. 글자를 숫자로 바꾸는 것을 '토큰화(tokenize)'라고 합니다. 이 토큰화를 수행하는 것을 토크나이저(tokenizer)라고 하죠. 토크나이저는 글자와 숫자를 매핑한 일종의 사전을 보고 문장의 글자들을 숫자로 변환하는 역할을 합니다.

우선 매핑 사전을 만들기 위해 데이터셋에 사용된 글자들을 파악해 보도록 하겠습니다. 여기선 Counter를 사용하겠습니다. Counter는 입력된 데이터들에서 중복된 데이터의 수를 dictionary 형태로 기록해줍니다.
from collections import Counter
# Counter는 입력되는 데이터들의 수를 세서 dictionary 형태로 기록하는 python의 자료형이다.
char_counter = Counter()
for review in ratings_train:
# 리뷰 문장은 2번째 열에 있다.
sentence = review.split("\t")[1]
for charactor in sentence:
char_counter.update(charactor)
# 글자를 사용된 횟수 순으로 정렬한다.
char_counter = dict(sorted(char_counter.items(), key=lambda item: item[1], reverse=True))
이를 프린트해보면 아래와 같이 사용된 글자들을 중복 없이 모두 확인할 수 있습니다.

이 사전을 이용해서 맨 앞 글자부터 0, 1, 2... 순으로 숫자를 하나씩 부여하여 각 글자마다 숫자를 하나씩 매핑해줄 것입니다. 하지만 이대로 바로 토크나이저를 만드는 것이 아니라, 텍스트를 학습하는데 필요한 특수 토큰 2개가 더 필요합니다.
<pad> 토큰
<pad> 토큰은 padding을 나타냅니다. 텍스트에 왜 padding이 필요할까요? 영화 리뷰 문장들은 모두 글자 수가 서로 다릅니다. 잠시 학습을 하는 과정을 생각해 보겠습니다. 데이터는 모델에 입력될 때 학습 속도와 효율을 위해 '배치 단위'로 구성되어 모델에 입력됩니다. 더 정확히는 tensor 형태로 변환되어 모델에 입력되게 되는데 만약 서로 길이가 다른 문장들을 tensor로 변환하려고 하면 아래와 같이 에러가 발생하게 됩니다.
import torch
# 만약 길이가 맞지 않다면 아래와 같이 오류가 발생합니다.
sentences = [[1, 2, 3, 4], [2, 4, 5, 6, 7], [3, 1]]
batch = torch.tensor(sentences)
이는 각 문장(리스트)의 길이가 일치하지 않기 때문에 생기는 에러입니다. 사실 서로 길이가 다른 리스트끼리 이중 리스트를 작성할 수 있는건 파이썬이 유일하죠. 애초에 계산이 행렬연산 위주로 이뤄지는데 서로 길이가 다르면 행렬이 성립되지가 않습니다. 그렇기 때문에 문장들의 길이를 맞춰줄 필요가 있습니다.
여기서 사용되는 것이 <pad> 토큰입니다. <pad> 토큰은 짧은 문장의 뒤에 추가되어 긴 문장과 길이를 맞추는 역할을 합니다.

<unk> 토큰
<unk>는 unknown을 나타냅니다. 즉, 아직 보지 못한 글자를 나타내는 특수 토큰입니다. 모델이 훈련 과정에서 세상에 존재하는 모든 글자를 학습한다면 좋겠지만 세상의 모든 언어, 이모티콘 등을 모두 합치면 그 수가 정말 무한에 가깝습니다. 이런 글자들이 15000개의 짧은 영화 리뷰에 다 담길리가 없겠죠. 그렇기 때문에 텍스트 모델을 학습할 때는 본 적 없는 글자가 들어오는 경우도 대비를 해야 합니다. 이런 경우에 사용하는 것이 <unk> 토큰입니다.
이렇게 2개의 특수 토큰을 추가하여 글자-숫자 매핑 사전을 완성해 보도록 하겠습니다. 리스트 형태로 저장하여 각 문자의 인덱스 번호가 해당 글자에 매핑되는 숫자를 나타내도록 합니다.
vocab = ["<pad>", "<unk>"] + list(char_counter.keys())
print(len(vocab))
print(vocab)
글자 수는 총 3006개가 사용된 것을 확인할 수 있습니다.
이제 이를 이용해서 토크나이저를 구현해 보도록 하겠습니다. 토크나이저는 글자를 숫자로 바꾸거나(encode), 숫자를 글자로 바꾸는(decode) 역할을 수행합니다.
class Tokenizer:
def __init__(self, vocab):
self.vocab = vocab
self.pad_id = self.vocab.index("<pad>")
self.unk_id = self.vocab.index("<unk>")
def encode(self, sentence):
ids = []
for ch in sentence:
if ch not in self.vocab:
id_ = self.vocab.index("<unk>")
else:
id_ = self.vocab.index(ch)
ids.append(id_)
return ids
def decode(self, ids):
sentence = ""
for id_ in ids:
sentence += self.vocab[id_]
return sentence
tokenizer = Tokenizer(vocab)이제 이 토크나이저를 이용해서 데이터셋을 만들어 보겠습니다.
import torch
from torch.utils.data import Dataset, DataLoader
class ReviewDataset(Dataset):
def __init__(self, ratings: list, tokenizer: object):
super().__init__()
self.reviews, self.labels = self.preprocess(ratings)
self.tokenizer = tokenizer
def preprocess(self, ratings):
reviews, labels = [], []
for rating in ratings:
_, review, label = rating.split("\t")
label = int(label[0])
reviews.append(review)
labels.append(label)
return reviews, labels
def __len__(self):
return len(self.reviews)
def __getitem__(self, idx):
review = self.reviews[idx]
label = self.labels[idx]
ids = self.tokenizer.encode(review)
return {"review": review, "ids": torch.tensor(ids), "label": label}
train_dataset = ReviewDataset(ratings_train, tokenizer)
test_dataset = ReviewDataset(ratings_test, tokenizer)
example = next(iter(train_dataset))
print(example)이제 DataLoader를 이용해 배치 단위로 구성해 주겠습니다. 여기서, 앞에 설명했던 <pad> 토큰을 활용해 문장의 길이를 맞춘 뒤 배치로 구성할 수 있도록 코드를 작성할 겁니다. 이는 DataLoader의 collate_fn이라는 함수를 직접 정의해서 구현할 수 있습니다. collate_fn은 직접 코드를 작성한 뒤, DataLoader의 인자로 전달할 수 있습니다.
collate_fn은 pytorch의 pad_sequence를 이용해서 코드를 작성할 겁니다. pad_sequence는 서로 길이가 다른 시퀀스와 <pad> 토큰의 인덱스(id, 숫자)를 입력하면 앞서 설명했던 <pad> 토큰의 역할을 그대로 실행해 줍니다.
from torch.nn.utils.rnn import pad_sequence
class Collate_fn:
def __init__(self, pad_id):
self.pad_id = pad_id
def __call__(self, batch):
reviews, ids, labels = [], [], []
for b in batch:
reviews.append(b["review"])
ids.append(b["ids"])
labels.append(b["label"])
# pad_sequence를 사용하면 문장 padding을 쉽게 구현할 수 있습니다.
ids = pad_sequence(ids, batch_first=True, padding_value=self.pad_id)
return reviews, ids, torch.tensor(labels).float()
collate_fn = Collate_fn(tokenizer.pad_id)
# collate_fn은 DataLoader를 정의할 때 argument로 추가할 수 있습니다.
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, collate_fn=collate_fn)
next(iter(train_loader))
결과를 확인해 보면 텍스트 토큰들 뒤에 <pad> 토큰의 id인 0들이 추가되어있는 것을 확인할 수 있습니다. 길이가 맞아 tensor로 변환되는 것도 에러없이 잘 처리 되었고요.
이제 모델을 구현하도록 하겠습니다. 모델은 아래와 같은 구조로 구성했습니다.

숫자로 토큰화된 문장이 입력되면, embedding 레이어는 해당 토큰의 embedding feature 값을 찾아서 출력합니다. 이 embedding feature 값은 학습을 통해서 결정되며 모델이 해당 글자를 해석하는 방식이라고 해석할 수 있습니다.
이는 뒤의 LSTM 레이어로 이어집니다. 2개의 LSTM 레이어를 거친 뒤 최종 hidden state를 Linear layer에 입력한 뒤, 최종적으로 0에서 1사이의 확률값 하나를 출력하게 됩니다.
import torch.nn as nn
class ReviewSentimentClassifier(nn.Module):
def __init__(self, vocab_size: int):
super().__init__()
self.embedding = nn.Embedding(vocab_size, 256)
self.rnn = nn.LSTM(256, 256, num_layers=2, batch_first=True, dropout=0.1)
self.linear = nn.Linear(256, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
x = self.embedding(inputs)
x, (h, c) = self.rnn(x)
x = self.linear(h[-1])
x = self.sigmoid(x)
return x.squeeze()
model = ReviewSentimentClassifier(vocab_size = len(vocab))이진 분류 문제이기 때문에 손실 함수는 Binary Cross Entropy Loss를 사용하는 것이 적절합니다.
epochs = 5
lr = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)그리고 학습을 진행합니다.
from tqdm import tqdm
from sklearn.metrics import accuracy_score
model.to(device)
train_losses, eval_losses, eval_accuracies = [], [], []
for epoch in range(epochs):
print(f"epoch {epoch+1}/{epochs}")
model.train()
train_loss = []
for data in tqdm(train_loader):
_, ids, labels = data
ids = ids.to(device).int()
labels = labels.to(device).float()
preds = model(ids)
loss = criterion(preds, labels)
train_loss.append(loss.detach().cpu().item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_losses.append(sum(train_loss)/len(train_loss))
model.eval()
eval_loss = []
eval_preds = []
for data in tqdm(test_loader):
_, ids, labels = data
ids = ids.to(device).int()
labels = labels.to(device).float()
with torch.no_grad():
preds = model(ids)
loss = criterion(preds, labels)
eval_loss.append(loss.cpu().item())
eval_preds.append(preds.cpu())
eval_preds = torch.cat(eval_preds, dim=0)
eval_preds = [1 if pred > 0.5 else 0 for pred in eval_preds]
acc = accuracy_score(test_dataset.labels, eval_preds)
eval_losses.append(sum(eval_loss)/len(eval_loss))
eval_accuracies.append(acc)학습 결과는 아래와 같습니다.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2)
ax[0].plot(train_losses, label="train loss")
ax[0].plot(eval_losses, label="eval loss")
ax[0].legend()
ax[0].set_title("Loss graph")
ax[1].plot(eval_accuracies)
ax[1].set_ylim(0, 1)
ax[1].set_title("Accuracy graph")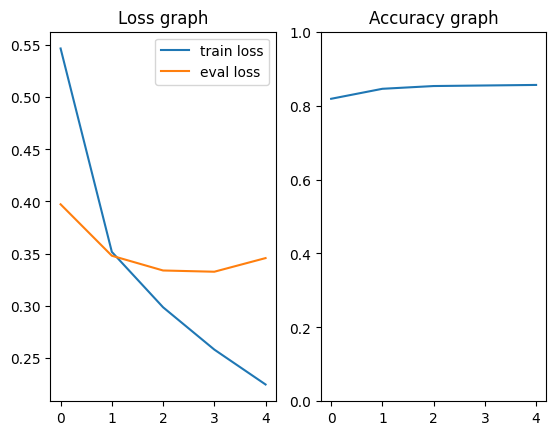
이렇게 학습된 모델과 토크나이저를 이용해 직접 리뷰를 작성하고 결과가 긍정이나 부정으로 잘 분류되는지 확인할 수 있습니다.
def evaluate(model, sentence):
inputs = tokenizer.encode(sentence)
model.eval()
model.to(device)
inputs = torch.tensor(inputs).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(inputs)
if outputs.item() > 0.5:
return "긍정"
else:
return "부정"
sentence = "이 영화는 시리즈가 갈 수록 참.. ㅋㅋ"
print(evaluate(model, sentence))
가장 쉽게 접하는 이미지를 처리하는 인공지능 모델과 이번에 본 텍스트 모델을 비교해 봤을 때 가장 큰 차이점은 당연히 데이터 전처리에 있을 겁니다. 이미지는 이미 각 픽셀값이 숫자로 이뤄져 있는 것에 반해 텍스트는 그렇지 않으므로 텍스트를 어떤 식으로 컴퓨터에 입력해 줄 것이냐 하는 텍스트 전처리는 NLP에서 특히 더 중요한 요소 중 하나입니다.
그 외에도 모델의 성능을 높이기 위해 텍스트에 어떤 전처리를 추가로 할 수 있을까에 대한 고민도 필요하겠죠. nsmc에서 간단히 이런 고민을 다뤄보겠습니다. 이 학습 데이터에 있는 영화 리뷰들은 모두 모델 학습에 도움이 될까요? 15000개의 문장을 모두 일일히 살펴보기는 어려울 수 있겠죠. 그래서 우선 혹시 길이가 너무 짧은 문장은 없는지 확인해 보겠습니다.
sentences = train_dataset.reviews
short_sentences = []
for sentence in sentences:
if len(sentence) < 3:
short_sentences.append(sentence)
print(len(short_sentences))
print(short_sentences)이 결과를 보면 '최고', '졸작', '버려', '망함'과 같이 두 글자 만으로도 충분히 영화에 대해 긍정적인지 부정적인지를 알 수 있는 리뷰들도 존재합니다. 하지만 '1', '4', '^^', 'ㅋㅋ'과 같이 글자만으로는 이 리뷰가 영화를 긍정적으로 보는건지 부정적으로 보는건지 알 수 없는 리뷰들도 다수 존재하는 것을 확인할 수 있습니다. 이런 리뷰들은 모델의 학습에 방해가 될 가능성이 높지 않을까요?
모델의 학습에 도움이 되는 두 글자 리뷰와 도움이 되지 않는 두 글자 리뷰의 가장 큰 차이점은 온전한 글자, 단어를 사용하지 않고 있다는 것입니다. 이를 필터링 하기 위해 re 라이브러리를 활용해 보겠습니다.
import re
code = "[^가-힣]"
meaningless = []
for sentence in sentences:
if len(sentence) < 3:
if re.search(re.compile(code), sentence) != None:
meaningless.append(sentence)
print(len(meaningless))
print(meaningless)위 코드는 리뷰의 글자 수가 3글자 미만이면서 '가'~'힣' 사이의 글자를 포함하지 않는 리뷰를 찾아내는 코드입니다. 결과를 보면 아래와 같은 리뷰들을 찾을 수 있는 것을 확인할 수 있습니다.
503
['1', '4', 'ㅇㅇ', '4', '굿!', 'ㅎㅎ, 'ㅉㅉ', '야.', ....]
총 503개의 리뷰가 검출되었으며 중간에 '굿!'과 같이 괜찮은 리뷰도 소수 존재하지만 대부분 의미 없는 글자로 구성되어 있는 리뷰들이라는 것을 확인할 수 있습니다.
그럼 이번에는 이 리뷰들을 학습 데이터에서 제거한 뒤, 모델을 다시 학습해 보도록 하겠습니다.
filtered_ratings_train = []
for rating in ratings_train:
sentence = rating.split("\t")[1]
if len(sentence) < 3 and re.search(re.compile(code), sentence) != None:
continue
filtered_ratings_train.append(rating)
filtered_train_dataset = ReviewDataset(filtered_ratings_train, vocab, tokenizer)
filtered_train_loader = DataLoader(filtered_train_dataset, batch_size=64, shuffle=True, collate_fn=collate_fn)
model2 = ReviewSentimentClassifier(vocab_size = len(vocab))
epochs = 5
lr = 1e-3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model2.parameters(), lr=lr)
결과를 보면 필터링을 수행한 모델이 미세하게 성능이 더 좋아진 것을 확인할 수 있습니다. 전체 15000개 중 500개의 도움이 되지 않는 리뷰를 제거한 것만으로도 성능이 어느정도 향상되는 것을 확인할 수 있습니다.
이런 식으로 오늘은 NLP task의 수행 과정을 살펴보고, NLP에서만 고민해 볼 수 있는 텍스트 처리 방식에 대한 고민도 간단히 살펴봤습니다. 앞으로는 NLP task를 해결하는 방법들에 살펴보면서 어떻게 발전해왔는지, 어떤 고민들이 필요한지 하나씩 알아가 보도록 하겠습니다.