[NLP-4] Attention is all you need, Transformer의 등장
1. RNN의 한계
2. Scaled dot product attention
3. Multi head attention
4. Transformer의 등장
1. RNN의 한계
지금까지 텍스트 데이터를 처리하는 문제에는 RNN 구조를 사용했습니다. RNN 구조를 사용한 이유는 텍스트 데이터에는 순서가 존재하기 때문이었습니다. 그리고 RNN 레이어는 그 순서 정보를 고려할 수 있기 때문에 이런 데이터에 이점을 가졌습니다.
하지만 RNN 레이어에도 단점이 존재합니다. 우선 텍스트가 지나치게 길어질 경우 RNN 레이어는 gradient vanishing/exploding(기울기 소실/증폭) 문제가 발생할 수 있습니다. 이 원인에 대해서는 RNN 레이어를 수식으로 보면 쉽게 알 수 있습니다. 길이가 3인 텍스트를 RNN 레이어로 처리한다면 아래와 같이 계산할 수 있습니다.
input : 다리미 [$x_1,x_2,x_3$]
RNN 레이어의 파라미터 : ($w_h, w_x, b$)
output : $w_h(w_h(w_x x_1+b)+w_x x_2+b)+w_x x_3+b$
보면 문장이 길어질수록 $w_h$가 반복적으로 많이 곱해지는 것을 볼 수 있습니다. 이는 역전파 과정에서도 마찬가지입니다. 위 수식을 $w_h$에 대해 미분해보면 맨 앞이 $3w_h^2$이 되는 것을 확인할 수 있습니다. 즉, 미분값에서도 $w_h$가 똑같이 반복적으로 곱해지게 됩니다.
그렇기 때문에 문제가 발생하기 쉬워집니다. 만약 $w_h$의 절댓값이 1보다 작다면, 문장이 길어질수록 기울기(미분값)가 점점 작아질겁니다. 그렇게 계속 작아지다 보면 0에 수렴하는 값을 갖게 되고 이는 기울기 소실(gradient vanishing)로 이어지게 됩니다. 반대로 $w_h$의 절댓값이 1보다 크다면 문장이 길어질수록 기울기(미분값)가 점점 커지게 되면서 무한대에 가까운 값을 갖게 됩고 이는 기울기 증폭(gradient exploding) 문제로 이어집니다.
또 다른 문제점은 RNN 모델은 계산이 오래 걸린다는 것입니다. 문장을 앞에서부터 순차적으로 처리하기 때문에 순서 정보를 고려할 수 있다는 장점을 갖지만, 앞에서부터 순차적으로 처리하기 때문에 문장이 길어질수록 계산이 오래 걸리고 이는 학습이 느려지는 결과로 이어지게 됩니다.
지금까지 RNN 레이어의 단점을 설명한 이유는, attention 레이어가 이 문제점들을 해결할 수 있기 때문입니다. Attention 레이어의 장점은 시퀀스의 길이가 길어져도 문제가 없으며 연산을 병렬적으로 처리해 RNN보다 속도가 빠르다는 장점을 갖습니다. 그럼 지금부터 attention 레이어에 대해서 알아보겠습니다.
2. Scaled dot product attention
Attention 레이어는 '문장 내에 있는 단어와 단어 사이의 연관성을 계산'하는 레이어라고 할 수 있습니다. 아래와 같은 문장을 봐보겠습니다.
"비가 온 날에는 예쁜 무지개를 볼 수 있어요."
위 문장에서 "예쁜"이라는 단어는 "무지개"라는 단어와 가장 연관성이 높을 겁니다. Attention 레이어는 이런 연관성을 계산하는 레이어입니다.
Attention 레이어에 대해 알아보기 위해 가장 기본적인 scaled dot product attention 구조를 알아보겠습니다. Attention 레이어는 3개의 요소를 이용합니다.
- Query : 다른 단어와의 연관성을 계산하고자 하는 타겟 단어.
- Key : 타겟 단어와의 연관성을 비교하는 주변 단어들.
- Value : 타겟 단어와 주변 단어 사이의 관계를 나타내는 가중치.

Attention 레이어는 query와 key 사이의 연관성을 계산하며 value를 이용해 두 단어 사이의 가중치를 나타냅니다. Attention을 계산하는 수식은 아래와 같습니다.
$$Attention(Q, K, V) = softmax({Q\cdot K^T\over \sqrt{d_k}})\cdot V $$
- Q, K, V : query, key, value를 나타내는 벡터.
- d_k : key 벡터의 차원 수
수식을 하나하나 살펴보자면, 우선 연관성을 계산해야하는 query와 key 사이에 dot-product 연산을 수행합니다. ($Q\cdot K^T$) 그리고 정규화를 위해 $\sqrt{d_k}$로 나눠줍니다.
이 값에 softmax 활성화 함수를 이용해 query와 key 사이의 연관성을 계산합니다. softmax 활성화 함수를 사용하면 query와 key 사이의 관계를 총합이 1인, 0에서 1사이의 값으로 나타낼 수 있게 됩니다.
마지막으로 이 값에 value와 dot product를 수행하는 것으로 attention 연산이 마무리 됩니다.

이제 이를 코드로 구현해 보겠습니다.
import torch.nn as nn
import math
class ScaledDotProductAttention(nn.Module):
def __init__(self, in_dim=512, out_dim=512, dropout_rate=0.2):
super().__init__()
self.query_layer = nn.Linear(in_dim, out_dim)
self.key_layer = nn.Linear(in_dim, out_dim)
self.value_layer = nn.Linear(in_dim, out_dim)
self.d_k = out_dim
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout_rate)클래스 생성자입니다. 입력되는 벡터의 차원 수(in_dim)와 출력되는 벡터의 차원 수(out_dim), dropout rate를 인자로 받습니다. query, key, value를 생성하는 linear레이어를 각각 정의하고, softmax와 dropout 레이어를 정의했습니다.
def forward(self, inputs, mask):
Q = self.query_layer(inputs)
K = self.key_layer(inputs)
V = self.value_layer(inputs)다음은 forward() 함수입니다. 입력은 inputs와 mask 2개의 tensor입니다. inputs는 [배치 크기, 시퀀스 길이, in_dim]의 shape를 갖습니다. (mask는 뒤에서 알아보겠습니다.)
우선 입력 벡터 inputs에 linear 레이어를 적용해 query, key, value를 각각 계산해냅니다. 각 query, key, value는 [배치 크기, 시퀀스 길이, out_dim]의 크기를 갖게 됩니다.
x = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(self.d_k)다음은 이 부분입니다. ($ {Q\cdot K^T\over \sqrt{d_k}} $) query와 key의 shape가 각각 [배치 크기, 시퀀스 길이, out_dim]이기 때문에 두 행렬의 곱을 계산하기 위해선 key의 shape를 transpose해줘야 합니다. transpose한 key는 [배치 크기, out_dim, 시퀀스 길이] shape를 갖게 되고, query와 key의 행렬곱은 결과적으로 [배치 크기, 시퀀스 길이, 시퀀스 길이]의 shape를 갖게 됩니다.

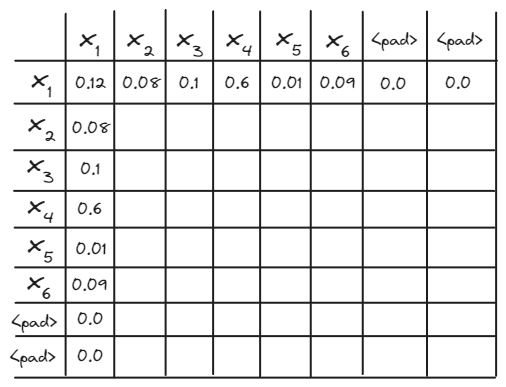
그 다음으로 앞의 수식에서 설명하지 않은 masking 과정이 필요합니다. masking은 모델에게 문장과 관련 없는 단어들을 보지 못하도록 가리는 작업을 말합니다. masking은 주로 <pad> 토큰을 가리는데 사용되는데요, 지금까지 봤다시피 서로 다른 길이의 텍스트 데이터를 배치 단위로 구성하기 위해 아래와 같이 텍스트에 <pad> 토큰을 추가해 길이를 맞춰줍니다.
( 0 = <pad> 토큰 )
[[2, 387, 1341, 0, 0, 0, 0],
[2, 13, 2578, 63, 0, 0, 0],
[2, 857, 523, 49, 133, 0, 0],
[2, 33, 761, 99, 152, 87, 3]]
여기서 <pad> 토큰은 아무 의미도 갖지 않습니다. 원래 문장엔 없던 글자니까요. 그렇기 때문에 <pad> 토큰과 다른 글자 사이의 관계를 계산하는 것은 옳지 않겠죠. 따라서 <pad> 토큰 위치엔 masking을 해 다른 단어와 연관성을 계산하지 않도록 합니다. 입력 문장이 위와 같다면 mask는 아래와 같은 형태를 띠게 됩니다. 1이 있는 위치는 글자가, 0이 있는 위치는 <pad> 토큰이 위치한다는 뜻입니다.
mask =[
[1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1],
]
이 mask는 아래와 같이 pytorch의 masked_fill 함수를 사용해 적용할 수 있습니다.
# masking
x = x.masked_fill(mask==0, -1e9)x는 앞서 계산한 ( $ {Q\cdot K^T\over \sqrt{d_k}} $ ) 벡터로 [배치 크기, 시퀀스 길이, 시퀀스 길이]의 shape를 갖고 있습니다. 그리고 입력되는 mask는 [배치 크기, 시퀀스 길이]의 shape를 갖고 있습니다. pytorch의 masked_fill을 사용하기 위해선 mask와 x의 차원 수를 맞춰줘야 합니다. 따라서 mask.unsqueeze(1)을 통해 mask의 shape을 [배치 크기, 1, 시퀀스 길이]로 변형해줍니다. 이렇게 해야 mask와 x의 shape이 맞아 masked_fill을 적용할 수 있게 됩니다.
x.masked_fill(mask==0, -1e9) 의 의미는 tensor x에서 mask에서 0인 위치의 값들을 -1e9로 바꾸라는 뜻입니다. 0이 아니라 -1e9로 바꾸는 이유는 softmax() 함수의 수식에 $exp(log_e)$가 들어가기 때문입니다. $exp(0)$의 값은 1이 되지만 $exp(-1e9)$의 값은 0이 됩니다.
a = torch.Tensor([-1.39, 5.23, -1e9])
print(F.softmax(a))
#############################
# 결과 : tensor([0.0013, 0.9987, 0.0000]) x = self.softmax(x)마지막으로 softmax 레이어를 거칩니다. tensor x의 shape은 [배치 크기, 시퀀스 길이, 시퀀스 길이] 였죠. 여기에 softmax를 적용한다는 것은 각 단어 사이의 연관성을 총합이 1인, 0에서 1사이의 확률값으로 나타낸다는 뜻입니다.
x = self.dropout(x)
out = torch.matmul(x, V)
return out이제 마지막입니다. 과적합 방지를 위해 dropout 레이어를 거치고, 마지막으로 value와의 행렬곱 연산(matmul)을 통해 최종 output을 냅니다. x의 shape이 [배치 크기, 시퀀스 길이, 시퀀스 길이] 이고 value의 shape이 [배치 크기, 시퀀스 길이, out_dim]이므로 transpose해 줄 필요가 없고, 최종 output의 shape은 [배치 크기, 시퀀스 길이, out_dim]이 됩니다.
아래는 scaled dot product attention의 전체 코드입니다.
import torch.nn as nn
import math
class ScaledDotProductAttention(nn.Module):
def __init__(self, in_dim=512, out_dim=512, dropout_rate=0.2):
super().__init__()
self.query_layer = nn.Linear(in_dim, out_dim)
self.key_layer = nn.Linear(in_dim, out_dim)
self.value_layer = nn.Linear(in_dim, out_dim)
self.d_k = out_dim
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, inputs, mask):
Q = self.query_layer(inputs)
K = self.key_layer(inputs)
V = self.value_layer(inputs)
x = torch.matmul(Q, K.transpose(-1, -2)) / math.sqrt(self.d_k)
# masking
if mask is not None:
x = x.masked_fill(mask==0, -1e9)
x = self.softmax(x)
x = self.dropout(x)
out = torch.matmul(x, V)
return out3. Multi head attention
다음으로 가장 자주 사용되는 multi head attention까지 알아 보도록 하겠습니다. Multi head attention은 scaled dot product attention을 기반으로 합니다. 차이점은 attention 연산을 여러 개의 head로 분할해서 수행한다는 것입니다.

여러 개의 head로 나눠 연산함으로써 가질 수 있는 이점은 한번의 연산으로 모델이 문장 내 단어 사이의 연관성을 더 다양한 관점에서 볼 수 있다는 것입니다. 실제로 scaled dot product attention과 성능 차이도 꽤 나는 편입니다.
Multi head attention의 코드를 살펴 보도록 하겠습니다.
class MultiHeadAttention(nn.Module):
def __init__(self, emb_dim, dropout_rate, num_heads):
super().__init__()
self.num_heads = num_heads
self.dim_heads = emb_dim//num_heads
self.d_k = self.dim_heads
assert (emb_dim%num_heads == 0), "emb_dim이 num_heads로 나눠떨어지지 않습니다."
self.query_layer = nn.Linear(emb_dim, emb_dim)
self.key_layer = nn.Linear(emb_dim, emb_dim)
self.value_layer = nn.Linear(emb_dim, emb_dim)
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout_rate)생성자에서 추가된 인자는 num_heads입니다. embedding을 몇 개의 head로 나눌지를 결정하는 것입니다. 여기서 주의해야 할 점은 embedding의 차원 수가 num_heads로 나눠 떨어져야 한다는 겁니다. 예를 들어 embedding dimension이 512이라면 num_heads는 512의 약수인 4나 8과 같은 값으로 지정해줘야 합니다. 그래야 각 head마다 똑같은 차원 수를 갖게 되고 남는 차원이 없게 되기 때문이죠. 만약 num_heads가 8이라면 각 head는 64의 차원 수를 갖게 됩니다.
추가로 query, key, value가 각각 여러 개의 head로 나눠지면서 dim_heads의 차원 수를 갖게 되므로, d_k의 값도 dim_heads로 변경해줬습니다. 그리고 마지막으로 linear layer가 추가로 필요해 정의해 줬습니다.
def forward(self, inputs, mask):
batch_size, seq_len, _ = inputs.size()
Q = self.query_layer(inputs)
queries = Q.view(batch_size, seq_len, self.num_heads, self.dim_heads).permute(0, 2, 1, 3)
K = self.key_layer(inputs)
keys = K.view(batch_size, seq_len, self.num_heads, self.dim_heads).permute(0, 2, 1, 3)
V = self.value_layer(inputs)
values = V.view(batch_size, seq_len, self.num_heads, self.dim_heads).permute(0, 2, 1, 3)다음은 forward() 함수입니다. query, key, value를 계산하는 것까진 앞과 동일합니다. 여기서 각 벡터를 num_heads개로 나눠주는 작업이 추가로 필요합니다. .view()와 .permute() 함수를 활용해 벡터의 shape을 변형해줍니다.

x = torch.matmul(queries, keys.transpose(-1, -2)) / math.sqrt(self.d_k)
if mask is not None:
x = x.masked_fill(mask==0, -1e9)
x = self.softmax(x)
x = self.dropout(x)
x = torch.matmul(x, values)그 뒤는 scaled dot product attention과 같습니다. query와 key의 행렬 곱을 계산하고, 마스킹을 적용한 뒤에 softmax, dropout. 그리고 value와 행렬곱까지 똑같이 수행합니다. 마지막 x는 [B, n_head, s, d_head] shape을 갖게 됩니다.
x = x.permute(0, 2, 1, 3).contiguous()
out = x.view(batch_size, seq_len, self.num_heads*self.dim_heads)
return out이제 나눠졌던 head를 다시 하나로 합쳐 줍니다. permute()를 통해 [B, s, n_head, d_head]로 shape를 변경해주고, .view()를 이용해 head들을 다시 합쳐줍니다. ([B, s, out]) 마지막으로 linear 레이어를 하나 통과하면서 multi-head attention 레이어는 마무리 됩니다.
전체 코드는 아래와 같습니다.
# 전체코드
class MultiHeadAttention(nn.Module):
def __init__(self, emb_dim, dropout_rate, num_heads):
super().__init__()
self.num_heads = num_heads
self.dim_heads = emb_dim//num_heads
self.d_k = self.dim_heads
assert (emb_dim%num_heads == 0), "emb_dim이 num_heads로 나눠떨어지지 않습니다."
self.query_layer = nn.Linear(emb_dim, emb_dim)
self.key_layer = nn.Linear(emb_dim, emb_dim)
self.value_layer = nn.Linear(emb_dim, emb_dim)
self.softmax = nn.Softmax(dim=-1)
self.dropout = nn.Dropout(dropout_rate)
def forward(self, inputs, mask):
batch_size, seq_len, _ = inputs.size()
Q = self.query_layer(inputs)
queries = Q.view(batch_size, seq_len, self.num_heads, self.dim_heads).permute(0, 2, 1, 3)
K = self.key_layer(inputs)
keys = K.view(batch_size, seq_len, self.num_heads, self.dim_heads).permute(0, 2, 1, 3)
V = self.value_layer(inputs)
values = V.view(batch_size, seq_len, self.num_heads, self.dim_heads).permute(0, 2, 1, 3)
x = torch.matmul(queries, keys.transpose(-1, -2)) / math.sqrt(self.d_k)
if mask is not None:
mask = mask.unsqueeze(1).repeat(1, seq_len, 1).unsqueeze(1)
x = x.masked_fill(mask==0, -1e9)
x = self.softmax(x)
x = self.dropout(x)
x = torch.matmul(x, values)
x = x.permute(0, 2, 1, 3).contiguous()
out = x.view(batch_size, seq_len, self.num_heads*self.dim_heads)
return out4. Transformer의 등장
지금까지 attention 레이어에 대해 알아봤습니다. NLP에서 attention 레이어가 많이 쓰이게 된 이유는 바로 'attention is all you need'(https://arxiv.org/abs/1706.03762)라는 논문에서 등장한 transformer 구조 때문입니다. 'Attention is all you need'라는 제목답게 transformer 모델은 rnn 계열의 레이어를 사용하지 않고 오로지 attention 레이어 만으로 구성되어 있습니다.
Transformer는 기계번역을 수행하는 모델입니다. 번역하려는 언어를 처리하는 인코더와, 번역 결과를 생성하는 디코더로 구성되어 있습니다. 이 인코더와 디코더는 모두 attention 레이어로 구성된 n개의 block으로 구성됩니다.

오늘은 이 transformer의 구조를 자세히 보기보단 이 모델이 NLP에 미친 영향 자체에 대해서만 얘기해 보도록 하겠습니다. 우선 NLP에는 rnn 계열의 레이어가 정배다라고 하는 기존의 틀이 이 모델로 인해 완전히 깨졌습니다. 앞에서도 설명했듯이 attention레이어는 rnn 레이어보다 긴 시퀀스도 잘 처리하고, 데이터의 처리도 병렬적으로 이뤄져 forward 속도가 더 빠릅니다. 따라서 attention 레이어만으로 구성된 모델은 더 많은 데이터를 더 빠르게 학습이 가능합니다.
이런 장점들로 인해서, attention 레이어로 구성된 모델을 이용해 대규모 텍스트 데이터를 사전학습하고, 각종 task들에 fine-tuning을 하는 방식이 가능해졌습니다. 이 논문 뒤에 등장한 GPT, BERT 모델을 선두로 NLP의 트렌드는 대규모 텍스트 데이터를 학습한 transformer 모델을 이용해 전이학습을 하는 식으로 바뀌었습니다. 따라서 NLP를 공부하려고 하면 transformer, attention에 대한 것을 반드시 알아야 하며 BERT와 GPT에 대해서도 알아야 할 수 밖에 없습니다.
오늘은 attention레이어가 rnn과 비교해 갖는 장점들에 대해 알아보고, attention의 구조에 대해서 알아봤습니다. 다음에는 transformer 구조와, 이를 이용해 NLP task들이 어떻게 처리되고 있는지에 대해 알아 보겠습니다. 감사합니다.