이제 인공지능의 학습 방식의 흐름을 알았으니, 이를 떠올리며 MNIST 손글씨 인식 인공지능 코드를 다시 살펴보겠습니다!
https://colab.research.google.com/drive/1KdjBmrpzOF2ja6dSzf7bdPbVge3ImpMy?usp=sharing
일단 만들어보자!.ipynb
Colaboratory notebook
colab.research.google.com
1. 문제 정의
인공지능 공부하면서 느낀 것 중 하나는 어떤 문제를 풀던간에 "입력"과 "출력"의 형태를 확실히 파악하는 것이 중요하단 것입니다. MNIST의 입력과 출력을 확실히 정의하고 가겠습니다.
MNIST 데이터셋은 "이미지" 입니다. 이미지는 컴퓨터에게 픽셀들로 이루어진 행렬과 같습니다. MNIST 이미지는 가로 28줄, 세로 28줄의 픽셀값으로 이뤄진 행렬입니다.
각 픽셀은 0에서 255 사이의 정수 값으로 이뤄져 있습니다. 그렇기 때문에 MNIST 모델은 28*28개의 정수값을 입력 받아야 합니다.
또 저희가 하고자 하는 것은 각 이미지에 그려진 숫자가 0부터 9까지의 숫자 중 어느 숫자인지를 맞추는 것입니다. 즉, MNIST는 "분류" 문제입니다.
0부터 9까지의 숫자를 '라벨'이라고 하겠습니다. 저희가 만들려는 MNIST 모델은 이미지를 입력 받으면, 해당 이미지가 어떤 라벨일 확률이 가장 높은지를 나타내기 위한 각 라벨의 확률값을 최종 결과로 내놓아야 합니다.
<MNIST 모델>
입력값 x : 784(=28*28)개의 정수 값.
출력값 y : 0부터 9까지 10개의 숫자 라벨의 확률 분포.

앞 글에서 본 인공지능 모델과 다른 점은 2가지 입니다. 첫번째로 입력값의 수가 하나가 아니라는 점, 두번째는 출력해야 하는 값이 특정 수치가 아니라 분류에 대한 확률 분포라는 점입니다.
2. 모델 정의
이제 MNIST의 입력과 출력에 걸맞는 모델을 정의해 보도록 하겠습니다. 우선 저희가 알고 있는 가장 기본적인 모델부터 생각해 보겠습니다. 저번 글에서는 $y=wx+b$ 라는 정말 기초적인 형태의 모델을 살펴봤었습니다. 그러나 이는 입력값과 출력값이 하나씩이고, 둘 사이의 관계가 w, b 2개의 파라미터만으로 충분히 표현될 정도로 단순한 관계이기 때문에 가능했습니다. MNIST는 입력값의 수도 784개고, 출력해야 하는 값도 10개인데다, 그냥 생각해 봐도 입력과 출력 사이의 관계가 $y=wx+b$ 수식 만으로 나타내기에는 무리가 있을 것 같습니다. 모델을 어떻게 업그레이드 하는게 좋을까요?
흔히들 "딥러닝의 학습 방식을 인간의 뇌의 학습방식과 유사하다" 라고 표현합니다. 그 이유는 사람의 수많은 뇌세포들이 서로 함께 학습을 하는 것과 같이 딥러닝 역시 여러 개의 '뇌세포(뉴런)'를 사용하기 때문입니다.
$y=wx+b$를 하나의 뉴런으로 보겠습니다. 하나의 뉴런만으로 입력과 출력 사이의 관계를 추론하기 어렵다면, 뉴런의 수를 늘리면 어떨까요?
이 뉴런의 수는 2가지 방식으로 늘릴 수 있습니다. 굳이 표현하자면, 하나는 '깊이'를 늘리는 방식이고, 하나는 '너비'를 늘리는 방식이라고 표현하겠습니다.
우선 가장 기본적인 하나의 뉴런으로 구성된 모델을 아래와 같이 표현하겠습니다.

모델의 '깊이'를 늘리는 방법은 이 뉴런을 다음과 같이 확장시키는 것입니다.

입력값에 서로 다른 뉴런을 2번 적용시키는 것입니다. 수식으로 쓰면 아래와 같습니다.
$$y=w_2(w_1x+b_1)+b_2$$
위 모델은 2개의 '레이어'로 이뤄진 모델이라고 부릅니다. 첫번째 레이어는 앞의 뉴런을 가리키고 두번째 레이어는 뒤의 레이어를 가리킵니다.
모델의 '너비'를 늘리는 방법은 다음과 같이 확장시키는 것입니다.

보면 각 레이어의 뉴런의 수가 늘어난 것을 확인할 수 있습니다. 그리고 모든 뉴런은 그 이전 레이어의 뉴런들과 서로 연결되어 있습니다. 이렇게 모두 연결되어 있는 레이어를 'fully connected layer' 또는 'linear layer'라고 합니다.
이렇게 입력과 출력 사이의 더 복잡한 관계를 규명할 수 있기를 기대하며 뉴런 수를 늘리는 방식을 택할 수 있습니다.
이렇게 깊이가 있는 모델을 DNN(Deep Neural Network)라고 합니다.
이 DNN에 대해서 조금 더 알아 보겠습니다. 우선 첫번째 레이어를 수식으로 작성한다면 아래와 같이 쓸 수 있습니다.
$ a_{(1,1)}=w_{(1,1)}x+b_{(1,1)} $
$ a_{(1,2)}=w_{(1,2)}x+b_{(1,2)} $
$ a_{(1,3)}=w_{(1,3)}x+b_{(1,3)} $
여기서 $a$는 각 뉴런의 출력값을 나타내며, $x$는 입력값을 나타냅니다. 각 변수의 $_{i,j}$는 i번째 레이어의 j번째 뉴런을 나타냅니다.
이렇듯, 하나의 레이어를 계산하는데 해당 레이어의 뉴런 수만큼의 수식이 필요하게 됩니다. 그러면 뉴런 수가 늘어날수록 필요한 연산 수가 기하급수적으로 늘어나게 될 것입니다. 그렇기 때문에 컴퓨터에서는 이를 행렬 연산을 통해 한번에 계산할 수 있도록 합니다.
$$ \begin{pmatrix}
a_{(1,1)}\\
a_{(1,2)}\\
a_{(1,3)}
\end{pmatrix}=
\begin{pmatrix}
w_{(1,1)}\\
w_{(1,2)}\\
w_{(1,3)}
\end{pmatrix} x+
\begin{pmatrix}
b_{(1,1)}\\
b_{(1,2)}\\
b_{(1,3)}
\end{pmatrix} $$
2번째 레이어는 2개의 뉴런으로 표현했습니다. 그러니 파라미터 w와 b도 2개가 필요합니다. 라고 생각하면 틀렸습니다. 왜냐하면 이 레이어는 입력이 3개이기 때문입니다. 파라미터 w는 입력 수와 출력 수의 곱만큼 필요합니다. 이유는 3개의 입력을 받아 2개의 출력 결과를 내기 위해 어떤 행렬 연산이 필요한지 생각해 보면 알 수 있습니다. 아래 수식을 보면 이해가 되실 겁니다.
$$ \begin{pmatrix}
a_{(2,1)}\\
a_{(2,2)}
\end{pmatrix}=
\begin{pmatrix}
w_{(2,1,1)}&w_{(2,1,2)}&w_{(2,1,3)}\\
w_{(2,2,1)}&w_{(2,2,2)}&w_{(2,2,3)}\\
\end{pmatrix}\cdot
\begin{pmatrix}
a_{(1,1)}\\
a_{(1,2)}\\
a_{(1,3)}
\end{pmatrix}+
\begin{pmatrix}
b_{(2,1)}\\
b_{(2,2)}
\end{pmatrix} $$
이렇게 3개의 입력을 받아 2개의 출력을 내기 위해선 3*2 크기의 w 행렬이 필요하다는 것을 알 수 있습니다.
마지막 레이어는 2개의 입력을 받아 1개의 출력을 냅니다. 따라서 2*1 크기의 w행렬이 필요할 것입니다.
$$ output=
\begin{pmatrix}
w_{(3,1,1)}&w_{(3,1,2)}\\
\end{pmatrix}\cdot
\begin{pmatrix}
a_{(2,1)}\\
a_{(2,2)}
\end{pmatrix}+b_3 $$
이 DNN을 코드로 표현한다면 아래와 같이 쓸 수 있습니다.
import torch.nn as nn
model = nn.Sequential(
nn.Linear(1, 3),
nn.Linear(3, 2),
nn.Linear(2, 1)
)
어떤가요, 이제 코드와 모델 구조에 대해 감이 오시나요? MNIST 모델 코드도 이 'linear layer'를 사용했었죠?
import torch.nn as nn
model = nn.Sequential(
nn.Linear(28*28, 256),
nn.Linear(256, 10)
)
nn.Sequential은 괄호 안의 레이어들을 연속적으로 포함하는 구조를 말합니다. 위 코드에 따르면 2개의 Linear 레이어를 일렬로 정렬한 구조가 되는 것입니다.
'첫번째 Linear 레이어는 28*28개의 입력값을 받아 256개의 출력값을 낸다는 것이고, 두번째 Linear 레이어는 256개의 입력값(첫번째 레이어의 출력값)을 받아 10개의 출력값을 내는 구조다' 라고 정의한 것입니다.
문제) 그렇다면 이 모델의 파라미터 수는 총 몇개일까요?
잠깐 생각해 보고 아래를 봅시다.
w와 b를 나눠서 생각하는 것이 좋습니다. 우선 w만 보자면, 첫번째 레이어는 784개의 입력을 받아 256개의 출력을 냅니다. 이를 위해선 784*256개의 w가 필요하죠. 2번째 레이어는 256개의 입력을 받아 10개의 출력을 내므로 2560개의 w가 필요할 것입니다.
b는 입력과 관계없이 출력 차원 수만큼만 필요합니다. 따라서 첫번째 레이어에선 256개, 2번재 레이어에선 10개가 필요합니다. 즉, 총 파라미터 수는 784*256+2560+256+10개가 되겠습니다.
문제를 잘 풀었다면, Linear 레이어에 대해선 거의 마스터라고 봐도 됩니다. 못 풀었어도 계속 보면서 적응하면 되니깐요, 일단 넘어갑시다.
3. 손실 함수
손실 함수를 보기 전에, 우선 모델의 출력값에 대해 생각해 볼 필요가 있습니다. 저희 MNIST 모델은 '분류 모델'입니다. 각 라벨 별 확률값을 출력하는 것이 모델의 최종 목표입니다.
확률값을 나타내기 위해선, 이 10개의 출력값의 총합이 '1'이 되어야 합니다. 이를 위해 쓰이는 '활성화 함수'가 있습니다. 활성화 함수란, 레이어의 값을 특정 범위 내로 조정하는 역할과 동시에 모델이 $y=wx+b$의 선형 구조를 벗어나 비선형 구조를 가질 수 있도록 해주는 역할을 합니다. 이에 대해서도 추후 다시 자세히 보도록 하겠습니다.
일단 softmax라는 활성화 함수에 대해서만 집중해 보겠습니다. softmax는 레이어의 출력 결과가 총합이 1인 확률값이 되도록 값을 조정하는 역할을 합니다. 특정 라벨의 확률값은 어떻게 계산할까요? 보통 아래와 같이 계산할 것입니다.
$$ p_j={y_j'\over\Sigma_{c=1}^C y_c'} $$
네, 한 라벨의 출력값($y_j'$)을 전체 라벨의 출력값의 합으로 나눠주면 됩니다. 그러면 모든 라벨의 출력값의 합이 1이 되겠죠. Softmax도 이와 같습니다. 다만, 활성화 함수는 "미분"이 가능해야 합니다. 최적화(optimizer) 기억나시죠? 최적화는 미분을 통해서 이뤄지기 때문에 각 활성화 함수도 미분이 가능해야 합니다. 이를 위해 지수 함수 e를 사용합니다.
$$ softmax(p_j)={e^{y_j'}\over \Sigma_{c=1}^C e^{y_c'}} $$
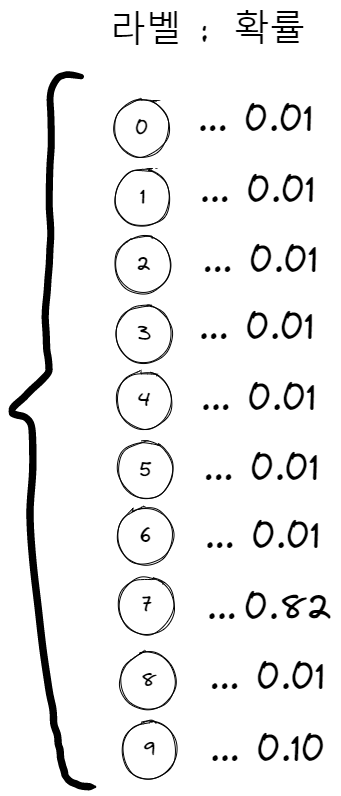
자, 그러면 MNIST 모델이 낼 수 있는 가장 이상적인 확률 분포는 무엇일까요? 만약 정답이 '7'이라면, 아래와 같은 확률 분포를 갖는 것이 가장 이상적이지 않을까요?

해당 이미지의 라벨에 해당하는 확률값만 1이고, 나머지는 0인 것이 가장 이상적인 확률 분포일 것입니다. 즉, 분류문제의 loss는 위와 같이 정답 라벨의 확률값만 1이고, 나머지는 모두 0일 때 그 loss 값이 0이 되어야 합니다. 이를 위해 사용되는 손실 함수는 'CrossEntropyLoss' 입니다. 왜 softmax를 먼저 보고 왔느냐 하면, 이 CrossEntropyLoss는 softmax를 사용하기 때문입니다.
$$ CrossEntropyLoss(y_j,y'_j)=1-log{e^{y_j'}\over \Sigma_{c=1}^C e^{y_c'}} $$
여기서 $j$는 정답 라벨입니다. 즉, 정답 라벨의 확률값($e^{y_j'}$)이 1에 가까워질수록, 우항의 값이 커지게 됩니다. 이를 1에서 빼므로, 우항의 값이 커질수록 loss는 작아지게 됩니다.
4. 최적화 (Optimizer)
모델 파라미터의 최적화는 어떻게 이뤄졌었나요? 각 파라미터마다 손실 함수를 미분한 뒤, 해당 미분값으로 파라미터 값을 갱신하는 방식을 사용했었습니다.
$$w=w-\alpha{dL \over dw}, (L=Loss\_function, \alpha=learning\_rate) $$
그러나 이는 가장 기본적인 최적화 방식이고, 더 효율적이고 성능 좋은 최적화 방식을 찾기 위해 연구자들이 수많은 최적화 방식들을 발명해 냈습니다. Adam은 그중에서도 현재 가장 많이 쓰이는, 가장 무난하게 성능이 잘 나오는 최적화 방식 중 하나입니다. 그 방식에 대해서는 나중에 따로 자세히 알아보도록 하겠습니다.
from torch.optim import Adam
optim = Adam(model.parameters(), learning_rate=1e-4)
PyTorch의 optimizer는 2가지 파라미터를 기본적으로 필요로 합니다. 첫번째 인자에는 최적화를 수행하고자 하는 파라미터들을 입력해 주어야 합니다. 그리고 learning_rate를 설정해야 합니다. 저는 0.0001(=1e-4)로 설정했는데요, 제가 임의로 설정한겁니다. 가장 이상적인 learning rate 수치는 사실 정해져 있지 않습니다. 각 모델마다, 실험마다 모두 다르기 때문에 보통 여러가지 수치를 실험해 보고 가장 결과가 좋은 수치를 결정합니다. 여러분도 한번 바꿔서 실험해 보세요. 더 좋은 점수가 나올 수도 있습니다.
4. 학습하기
마지막으로 학습 코드를 살펴보겠습니다.
for data in tqdm(train_dataset):
data = {k: v.to(device) for k, v in data.items()}
images = data["images"]
output = model(images)
loss = criterion(output, data["labels"])
train_loss.append(loss.detach().cpu().item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
for문을 통해 전체 데이터를 한바퀴 순회합니다. 처음 4줄까지는 데이터를 준비하는 코드이고 그 다음 줄부터 자세히 살펴 보겠습니다.
output = model(images)
여기서 output의 shape은 어떻게 될까요?
정답은 (배치 크기, 10)입니다. MNIST 모델의 목표는 10개의 라벨에 대한 확률 분포를 출력하는 것이라는 것을 다시 떠올리면 좋을 것 같아서 질문했습니다.
loss = criterion(output, data["labels"])
다음은 모델이 예측한 확률 분포(output)와 실제 라벨(data["labels"])을 비교하여 loss를 계산하는 코드입니다. 앞서 설정했듯이, CrossEntropyLoss를 통해 계산됩니다.
여기서 주의할 점은, output과 label의 형태인데요, output은 [배치 크기, 10] 크기의 tensor이지만, data["labels"]는 단순히 정답 라벨들을 담고 있는 1차원 tensor입니다.
output=
tensor([[-6.5160e-02, 6.8005e-02, ...]...], device='cuda:0', grad_fn=<AddmmBackward0>)
data["labels"]=
tensor([9, 8, 4, 0, 6, 6, 6, 6, 7, 1, 9, 6, 2, 0, 7, 9], device='cuda:0')
사실 CrossEntropyLoss를 엄밀히 계산하고자 한다면, 라벨값도 위와 같은 형태가 아니라 아래와 같이 배치 개수만큼의 확률 분포로 나타나야 합니다.
data["labels"]=
tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [0, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 0, 0, 0, 1, ...], ...], device='cuda:0')
원래는 이렇게 바꿔주는 것이 정확하지만, PyTorch는 CrossEntropyLoss 내부에서 이를 자체적으로 수행해 줍니다. 그렇기 때문에 라벨을 그대로 넣어줄 수 있는 것입니다. (제가 이것 때문에 헷갈렸던 적이 많아서 적어봤습니다.)
train_loss.append(loss.detach().cpu().item())
그 다음 코드는 loss 값들을 학습이 끝나고 확인하기 위해 train_loss라는 리스트에 그 값을 기록하는 코드입니다. loss 뒤에 뭐가 주렁주렁 달려 있는데요, 하나씩 설명하겠습니다.
- .detach() : 해당 tensor의 gradient 정보들을 지워주는 역할을 합니다. 학습에 사용되는 모든 tensor들은 gradient 정보가 포함되어 있습니다. 이는 최적화(optimize)를 빠르게 하기 위해 PyTorch가 자체적으로 저장해두는 값인데요, 이렇게 학습 중간에 tensor 값을 기록하고자 할 때, 이런 정보들이 필요가 없다면, 무조건 .detach()를 붙여서 이를 지워주시는 것이 좋습니다. 왜냐하면 이게 용량이 꽤 돼서 .detach()를 붙이지 않고 학습하다 보면 금방 저장공간이 다 차거든요...
- .cpu() : 해당 tensor를 gpu에서 cpu로 옮겨오는 역할을 합니다. 빠른 학습을 위해서 보통 모델과 데이터들을 gpu에 올려놓고 학습을 진행합니다. 그러나 gpu는 용량이 작기 때문에 이런 loss값 같은 것들을 gpu에 올린 상태로 그대로 저장하다 보면 gpu 메모리가 금방 차서 학습이 중단됩니다. 그러니 gpu를 활용해 학습하고 있다면 loss를 기록할 때 무조건 .cpu()를 붙여 cpu 메모리로 값들을 옮겨 옵시다.
- .item() : pytorch의 loss function을 통해 나온 출력 결과물은 tensor입니다. 이는 결과물이 단 하나의 실수더라도 tensor 형태로 출력이 됩니다. .item()을 붙이면 tensor에 저장된 실수값만을 불러올 수 있습니다.
optimizer.zero_grad()
optimizer의 gradient 정보를 0으로 만들어주는 코드입니다. PyTorch는 빠른 최적화를 위해 gradient 값들을 그대로 저장하고 있습니다. 그렇기 때문에 매 학습 step마다 이를 초기화 해줘야 합니다. 만약 초기화를 하지 않는다면, 이전 gradient 정보에 그대로 gradient 정보가 추가되어 학습이 이상하게 진행될 수가 있습니다.
loss.backward()
최적화를 위한 미분값(${dL\over dw}$, ${dL\over db}$)을 계산합니다.
optimizer.step()
계산된 미분값을 이용해 파라미터 값들을 갱신합니다.
optimizer.zero_grad(), loss.backward(), optimizer.step() 이렇게 3줄의 코드는 그냥 PyTorch 학습의 공식과 같습니다. 이 3줄은 매 step마다 무조건 이뤄져야 합니다. 이 3줄의 코드가 모델을 학습시키는 핵심 코드라고 볼 수 있습니다.
마무리
여기까지 MNIST의 코드를 다시 보는 것을 마무리 해보도록 하겠습니다. 맨처음 코드를 막 만들었을 때와 지금이랑 코드를 봤을 때 느껴지는 이해도가 다를 겁니다. 이제 학습과정에 대해서도, 학습 코드에 대해서도 대략적인 기본 틀은 잡혔다고 생각이 됩니다.
다음에는 최적화(optimizer), 활성화 함수, 모델 등을 하나씩 더 자세히 다뤄보도록 하겠습니다. 감사합니다.
'처음부터 하는 딥러닝' 카테고리의 다른 글
| [딥러닝 기초] 손실 함수 (Loss function) (2) | 2023.05.17 |
|---|---|
| [딥러닝 기초] 경사 하강법(Gradient descent) (0) | 2023.05.09 |
| [딥러닝 기초] 학습은 어떻게 이루어질까 (0) | 2023.04.30 |
| [딥러닝 기초] 일단 만들어보기 (0) | 2023.04.24 |
| [딥러닝 기초] 딥러닝 기초 내용 포스팅의 목표 (0) | 2023.04.24 |



