이미지와 텍스트를 함께 학습하는 멀티 모달에 대해 궁금하던 차에 본 논문을 읽어보게 되었습니다. 일단 논문 내용이 완전히 이미지와 텍스트 사이의 관계에 대해서 다루는 내용은 아니었습니다. 그보다는 "비전 영역에서 언어 모델의 특징과 장점들을 활용할 수 있는 방법이 없을까?"에 관련된 내용입니다. 기대했던 내용은 아니었지만, 꽤 흥미로운 주제인 것 같아서 읽고 리뷰해보게 되었습니다.
(논문이 굉장히 길기 때문에 제가 흥미 있거나 중요해 보이는 부분들 위주로 작성했습니다. 때문에 논문의 전체 내용을 정리하지는 않았다는 점... 유의해 주시기 바랍니다.)
목차
1. 배경 소개
2. CLIP 모델 구조
3. 데이터셋
4. 실험 결과
4.1. Zero-shot Transfer
4.2. Zero-shot CLIP performance
4.3. Few-shot CLIP performance
4.4. Representation Learning
4.5. Robustness to Natural Distribution Shift
5. 정리
1. 배경 소개
우선 비전 영역에서 활용하고 싶은 언어 모델의 장점이 무엇일까요?
비전 영역에서는 대량의 이미지를 라벨링한 뒤 분류 학습을 하여 사전학습모델을 만듭니다. 이미지의 라벨은 해당 이미지에 찍힌, 그려진 대상으로 할 수 있겠죠. 그러나 텍스트는 이런 식으로 라벨을 부여하는 것이 이미지보다 기준이 애매하고 복잡한 경우가 많습니다. 이런저런 문제로 이미지처럼 대규모의 라벨 데이터를 구축하는 것이 어렵습니다.
그래서 NLP 영역에서는 대규모의 '라벨이 없는' 텍스트로 모델을 학습하는 방식을 개발하게 됩니다. 대표적으로 문장의 일부를 '마스킹'한 뒤, 해당 부분에 알맞은 단어를 예측하는 방법이나, 지금까지 작성된 단어들을 보고 그 뒤에 올 알맞은 단어를 예측하는 방식이 있습니다.
이런 방식들의 놀라운 점은, 사전학습에 라벨링 과정을 생략할 수 있다는 것뿐만 아니라 이런 사전학습을 통해서 모델이 언어체계와 관련 지식들에 대해서 일종의 '이해도'를 갖추게 된다는 것입니다. 단지 문장에 알맞는 다음 단어를 예측하는 식으로 학습했을 뿐인데, 이를 이용해 문장 분류, 문장 생성, QA, 문장 관계 분류 등 다양한 방식의 task에도 fine-tuning을 거치면 높은 성능을 보인다는 것입니다.

연구자들은 여기서 그치지 않고, 한 발 더나아가 few-shot이라는 개념을 내놓습니다. GPT라는 언어 모델 연구에서 등장한 개념인데, 다음 단어를 예측하는 방식으로 사전학습된 모델이 fine-tuning을 거치지 않고도 문제를 해결할 수 있는 능력이 있다는 것입니다.
예를 들어 '영화 리뷰의 감성 분석'을 수행하고자 한다면, 사전학습된 GPT (혹은 BERT) 모델에 분류를 위한 dense layer를 추가하여 fine-tuning한 뒤에 성능을 얻는 것이 일반적입니다. 하지만 정말 대규모 텍스트로 학습된 언어 모델은 이런 과정 없이도 추론이 가능하다는 것입니다.
"'이번 영화는 정말 완벽해.'의 감성은 긍정,
'이번 영화는 좀 재미없다.'의 감성은 부정,
'이번 영화는 전작에 비해 아쉽다.'의 감성은?
추가 fine-tuning 없이 위와 같은 문장을 사전학습 모델에 입력하면 '부정'이라고 출력을 할 수 있다는 것입니다. 이를 few-shot prediction이라고 하며, 위와 같이 문제의 예시가 2개 주어진 경우는 2-shot prediction이라고 합니다.
정말 놀라운건 대규모 텍스트로 학습된 언어 모델은 문제의 예시가 하나도 주어지지 않는 zero-shot prediction도 가능하다는 것입니다.
논문에서는 CLIP을 통해 비전 영역에서도 이런 장점들을 취하고 싶은 것입니다.
- 같은 이미지에 대해서도 여러가지 표현이 가능한 언어의 풍부한 표현력을 활용.
- 비전 영역에서의 zero-shot prediction을 통해 모델의 이해도를 입증.
기존 방식대로 비전 모델을 사전학습 한다면, 모델은 개가 그려져 있는 이미지에 대해서 '개'다 라는 정보밖에 얻을 수 없습니다. 그러나 이미지에 대한 언어 표현과 함께 학습을 한다면 이미지에 대해 좀 더 심층적으로 이해를 할 수 있을 것입니다. 언어는 같은 개 이미지에 대해서도 다양한 표현이 가능하니깐요.

그리고 이런 이미지에 대한 심층적인 이해도를 증명하기 위해서 여러가지 task에 실험도 해보고, 무엇보다도 zero-shot prediction을 통해 이를 증명하고자 하는 것이 주요내용입니다.
2. CLIP 모델 구조
CLIP 모델 구조에 대해 알아보겠습니다. 어떻게 이미지와 텍스트 사이의 관계를 잘 학습시킬 수 있을까요?
이를 '분류' 학습하는 것은 어려운 일일 것 같습니다. 같은 이미지에 대해서도 다양한 언어 묘사가 가능하고, 정말 무한대에 가까운 묘사 문장이 존재할 수 있기 때문에 이를 일일이 라벨로 만드는 것도 어렵습니다.
CLIP은 분류 대신에 '적대적 학습'을 사용하기로 합니다. 적대적 학습(Contrastive learning)은 이미지에 알맞은 문장 묘사는 서로 가깝게, 그렇지 않은 문장 묘사는 서로 멀어지도록 학습하는 방법입니다.
이를 통해 모델은 이미지/텍스트가 입력됐을 때, 해당 이미지/텍스트와 관련 있는 텍스트/이미지를 찾을 수 있는 능력을 기르게 됩니다.

좀 더 자세히는, 이미지-텍스트 쌍의 미니 배치를 입력 받았을 때, 이미지와 문장들을 각각 인코딩합니다. 그 뒤 이미지 인코딩 결과와 텍스트 인코딩 결과(representation)끼리 유사도를 비교하여, 알맞은 쌍의 representation끼리는 큰 유사도를, 알맞지 않은 쌍의 representation끼리는 작은 유사도를 갖도록 하는 것입니다. 유사도 계산방식은 dot-product를 사용했습니다. 이미지 인코딩 결과와 텍스트 인코딩 결과 사이의 행렬곱 연산을 통해 유사도 행렬을 결과로 얻고, 서로 대응되는 쌍의 유사도를 담은 행렬의 대각성분을 라벨로 하는 classification을 통해 학습됩니다.
이를 in-batch negative 방식이라고 하는데, 논문에 나온 아래 pseudo 코드를 참고하면 더 이해하기 좋을 것 같습니다.

이미지 인코더는 ResNet과 ViT(Vision Transformer)를 사용했고, 텍스트 인코더는 GPT를 사용했다고 합니다. 모델 구조만 해당 모델들과 같이 사용했고, weight들은 처음부터 학습을 시켰다고 합니다. 그 외 세부사항들이 궁금하다면 논문의 2.3.~2.5. 부분을 직접 참고하시기 바랍니다.
3. 데이터셋
위와 같이 학습을 하기 위해선 결국 대량의 이미지-텍스트 쌍이 필요합니다. 연구진은 인터넷에서 4억개의 데이터를 수집했으며, 최대한 다양한 주제의 이미지를 확보하기 위해 wikipedia에 자주 사용된 단어 50만 개를 키워드로 검색해 수집했다고 합니다.
또, 라벨 균형을 맞추기 위해 각 키워드마다 최소 20,000개의 데이터를 포함하도록 했습니다. 결과적으로 GPT-2 모델 학습에 사용된 WebText 데이터셋과 유사한 양의 단어 데이터를 확보할 수 있었습니다.
4. 실험 결과
4.1. Zero-shot Transfer
CLIP의 zero-shot 성능을 알아봅시다. 이미지에서는 zero-shot prediction을 어떻게 수행할 수 있을까요?
CLIP은 학습 과정에서 텍스트를 사용했기 때문에 텍스트를 이용할 수 있습니다.

CLIP은 "A photo of a {dog/cat/car...}"과 같이 문장들과 이미지를 입력한 뒤에, 이미지 representation과 가장 유사도가 높은 문장 representation을 라벨로 분류할 수 있습니다. 좀 더 성능을 높이고 싶다면 문장에 "A type of pet."과 같이 부연설명을 추가해주는 것도 도움이 됩니다.
4.2. Zero-shot CLIP performance

Zero-shot CLIP의 성능을 27개의 데이터셋에 대해 ResNet-50 모델과 비교해봤습니다. 어떤 데이터셋은 CLIP이 훨씬 좋았고, 어떤 데이터셋은 ResNet이 더 좋은 모습을 보였습니다. 그 이유는 ResNet-50 학습에 사용된 데이터에 각 데이터셋들에 존재하는 데이터들과 얼마나 겹치는가에 따라 달라지는 것으로 보인다고 합니다.
그 밖에도, CLIP과 ResNet은 아래와 같은 차이를 보입니다.
- 일반적인 task들에서는 CLIP이 더 좋은 성능을 보임. (ImageNet, CIFAR10/100, STL10, PascalVOC2007) 반대로 좀 더 전문적이거나 추상적인 라벨 데이터들(위성 이미지 분류(EuroSAT, RESISC56), 림프 종양 탐색(PatchCamelyon), 물건 숫자 세기(CLEVRCounts) 등)에 대해서는 CLIP이 더 약점을 보였습니다.
- 영상의 행동 인식 데이터셋(Kinetics700, UCF101)에서는 CLIP이 더 강점을 보입니다. 이는 pre-training 과정에서 CLIP은 이런 동작들에 대한 언어 묘사를 함께 학습한 것이 도움된 것으로 보입니다.
일반적으로 딥러닝 모델들은 크기를 키울수록 성능이 더 높아지는 효과를 봅니다. CLIP도 그런지 확인하기 위해 모델의 크기를 늘려 보았습니다.

위 그래프를 보면, 39개의 데이터셋에 대한 평균 error(진한 선)는 모델의 크기를 늘릴수록 줄어드는 것을 확인할 수 있지만, 실제로 각 데이터셋 별로 error 수치(연한 선)들은 많이 들쭉날쭉한 모습을 보입니다. CLIP 모델의 크기를 키울수록 무조건 zero-shot 성능이 좋아진다라고 보기는 살짝 무리가 있는 것 같습니다.
4.3. Few-shot CLIP performance

Few-shot은 각 데이터셋의 라벨 별로 이미지를 n장씩 분류 학습을 진행한 뒤에 결과를 측정하는 방식으로 실험을 했습니다. 예시가 주어지지 않는 zero-shot보단 예시가 주어지는 few-shot의 성능이 더 좋을 것이란 기대는 당연한 것 같습니다. 하지만 실험 결과 1,2,3-shot은 오히려 zero-shot보다 성능이 떨어졌습니다. 이는 이미지에 대한 묘사가 부족한 텍스트로 추가 학습을 진행했기 때문에, 오히려 zero-shot CLIP의 표현력을 해치면서 모델 성능을 감소시킨 것으로 추측하고 있습니다.

기존 zero-shot CLIP의 성능을 따라잡기 위해선 평균적으로 최소 4-shot은 필요했으며, 16-shot까지 가면 성능이 더 향상되는 것을 확인할 수 있었습니다. 물론 이는 평균수치이고, 실제로는 데이터셋 별로 zero-shot 성능에 도달하기 위한 few-shot의 수가 천차만별이었습니다.

4.4. Representation Learning
본 문단에선 Zero-shot 성능에 대해선 알아봤고, 'CLIP이 사전학습 모델로서 얼마나 가치있느냐'를 알아보기 위해 실험을 진행합니다.
CLIP의 이미지 인코더를 활용해 ResNet과 같이 각 task 별로 fine-tuning을 한 뒤, 그 성능을 비교해 봤습니다.

총 39개 데이터셋에 대해 성능을 비교해봤으며, CLIP의 성능(빨간 별)이 대체로 다른 모델들에 비해 좋은 것을 확인할 수 있으며, 이미지 인코더로 ResNet보다 ViT를 쓰는 것이 더 좋은 것을 확인할 수 있습니다. 그리고 zero-shot과 다르게 여기선 모델의 크기를 키우는 것(그래프의 x축)이 확실히 효과가 있었습니다. 특히 ViT의 경우, ResNet보다 연산량이 더 적었고, 그렇기 때문에 ResNet보다 모델의 크기를 훨씬 키울 수도 있었습니다.
CLIP과 다른 모델들과의 성능 차이는 왼쪽 그래프보다 오른쪽 그래프에서 더 크게 나타납니다. 왼쪽 그래프에 사용된 데이터셋들은 일반적인 분류 문제들 위주로 이루어져 있지만, 오른쪽 그래프에 사용된 데이터셋들에는 geo-localization(지역 맞추기), optical character recognition(캐릭터 인식), facial emotion recognition, action recognition과 같은 task들이 포함되어 있기 때문입니다. 즉, 사전학습 모델로써 CLIP은 이미지에 대한 좀 더 자세한 이해가 필요한 task들에 특히 강한 모습을 보인다는 것을 알 수 있습니다.
PatchCamelyon(림프 상태 판별 데이터셋), CLEVRCounts(객체 숫자 세기)와 같은 데이터셋들에 대해서는 ResNet도, CLIP도 매우 낮은 정확도를 보였습니다. CLIP도 너무 추상적이거나, 너무 전문적인 이미지들에 대해서는 약점을 그대로 보이는 것 같습니다.
4.5. Robustness to Natural Distribution Shift
정말 세상의 모든 이미지들을 학습하고 싶지만, 매우 힘든 일이겠죠. 그렇다 보니 학습에 사용되는 데이터셋들도 특정 분야와 관련된 데이터(distribution)로 구성되는 경우가 많습니다.
그리고 딥러닝 모델은 통계에 기반하기 때문에, 학습된 데이터에 존재하지 않는 새로운 유형의 데이터가 들어오면 이를 올바르게 처리하는 것이 어렵습니다.
이런 문제는 진정한 인공지능을 개발하기 위해 넘어야 할 산 중 하나입니다. 왜냐하면 인간은 학습을 하지 않더라도, 직관을 이용해 처음 보는 사진도 어느정도 인식하고 구분할 수 있기 때문입니다.
이렇게 학습에 사용되지 않은 데이터들 (다른 distribution)에 대해서 어느정도의 성능을 낼 수 있는가를 나타내는 지표를 robustness라고 합니다.
이런 일은 기존의 VGGNet, ResNet과 같은 모델로는 어렵습니다. 그러나 CLIP은, 이미지를 텍스트와 함께 학습함으로써 이미지에 대해 좀 더 직관적인 이해를 갖출 수 있을 것으로 기대할 수 있습니다. 그리고 이는 zero-shot prediction을 통해 어느정도 입증했습니다. 그러니 이런 문제에 대해서 좀 더 좋은 성능을 기대할 수 있지 않을까요?

실험을 위해 ImageNet에 대한 성능을 측정하고, ImageNet과 다른 distribution을 갖는 데이터셋들에 대한 성능을 측정했습니다. 위 그래프와 같이, 모든 모델이 ImageNet에 대한 성능이 높을수록 다른 데이터셋에 대한 성능도 높은 경향을 보입니다. 하지만 그 중에서도 CLIP은 특히 다른 데이터셋에 대한 점수가 높은 것을 확인할 수 있습니다.
물론, ImageNet으로 훈련된 다른 모델들과 다르게 CLIP은 직접 인터넷에서 수집한 데이터로 학습됐기 때문에 이런 차이가 생겼을 수도 있습니다. 그래서 학습된 CLIP의 이미지 인코더를 ImageNet 데이터로 fine-tuning 하면서 ImageNet과 다른 데이터셋들에 대한 성능이 어떻게 변화하는지를 지켜봤습니다.

보면 ImageNet으로 학습함에 따라 ImageNet에 대한 정확도가 9.2%나 향상된 것을 확인할 수 있습니다. 그런 것에 반해 다른 distribution의 데이터셋들에 대해서도 정확도가 크게 감소되지 않았고(최대 4.7%감소), 심지어 오른 경우도 있었습니다. 이로 미루어 보아 사전학습에 사용된 데이터의 차이도 영향은 있었던 것 같지만, CLIP의 다른 요소들(텍스트와 함께 학습, contrastive learning을 사용)도 분명 영향을 준 것으로 보입니다.
게다가, Zero-shot CLIP은 구조적으로도 다른 라벨들에 더 잘 적용될 수 밖에 없습니다. 기존 방식대로 학습된 모델들은, 만약 학습되지 않은 라벨을 예측하려면 새롭게 dense layer를 추가 학습하거나, 원래 있던 라벨 중 비슷한 라벨로 분류할 수 밖에 없습니다. 하지만 Zero-shot CLIP은 그냥 문장만 바꿔주면 되죠.
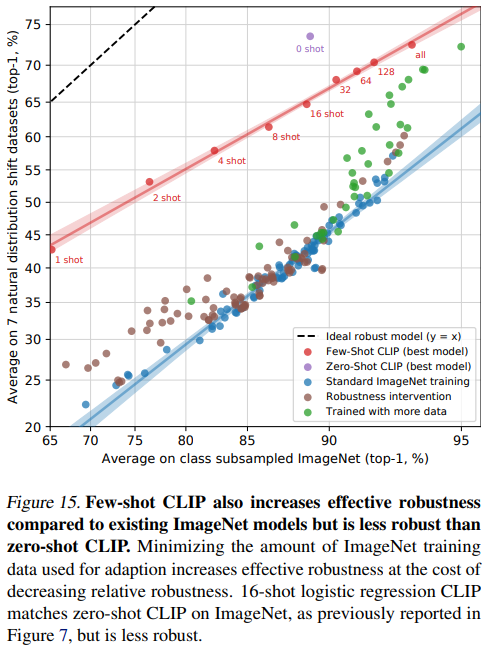
CLIP의 이미지 인코더를 representation으로 활용해 ImageNet에 훈련시키는 방식은 높은 robustness를 가졌지만, CLIP 전체에 ImageNet을 few-shot으로 학습시키는 방식은 robustness가 상대적으로 떨어지는 모습을 보였습니다.
CLIP에 ImageNet의 few-shot 수를 늘려가며 성능을 다시 측정해 본 결과, ImageNet에 대해 성능이 올라가는 폭에 비해 다른 데이터셋들에 대한 성능 향상 폭은 작아지는 것을 확인할 수 있었습니다.
여러 모로 CLIP의 few-shot learning과 representation learning 방식의 결과가 다르게 나타나는 것 같습니다.
5. 정리
이쯤에서 내용을 정리해보겠습니다.
CLIP은 비전 영역에서 언어의 다양한 표현력과 언어 모델의 고차원적인 이해도를 활용하고 싶다는 아이디어에서 출발한 연구입니다. 기존의 pre-training 방식은 이미지들을 특정 라벨로 분류하는 식으로 이뤄진 반면에, 이미지에 대한 언어 묘사를 학습에 활용하면, 해당 이미지에 대해 더 다양한 정보들을 모델이 학습할 수 있다고 믿었기 때문입니다.
이를 효율적으로 학습하기 위해 CLIP은 이미지 인코더와 텍스트 인코더를 contrastive learning을 통해 학습 시키는 방식을 사용했습니다.
그 결과, 신기하게도, 다양한 이미지 분류 task들에 대해서 추가 학습 없이 Zero-shot CLIP만으로도 높은 정확도를 달성했습니다. 게다가 CLIP은 pre-training 모델로써 다른 task들에 대한 fine-tuning 성능도 SOTA 성능을 달성했으며, 학습에 사용되지 않은 다양한 이미지들에 대한 성능(robustness)도 강한 모습을 보였습니다.
제가 이 논문에 흥미가 생겼던 이유는 이미지 학습에 언어의 다양한 표현력을 활용하고자 하는 아이디어가 재밌었기 때문입니다. 비전 영역에서 zero-shot 성능을 확인한다는 개념도 신기했습니다만, few-shot이나 여러가지 실험 결과 분석에서는 뭔가 아쉬운 부분도 있었던 것 같습니다. 아무래도 처음 시도하는 개념이다보니 여러가지 개선점이나 한계점도 많이 있어서 그런것 같습니다.
'딥러닝 논문리뷰' 카테고리의 다른 글
| 사전 학습 모델에 대한 공격 - RIPPLe (0) | 2023.07.09 |
|---|---|
| Meena : SSA 평가지표를 제시한 사람 같은 챗봇 (0) | 2023.07.04 |
| Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2023.05.13 |
| Approximate nearest neighbor Negative Contrastive Learning for Dense Text Retrieval (0) | 2023.05.05 |
| ColBERT: Efficient and effective passage search via contextualized late interaction over BERT (2) | 2023.04.27 |



