0. Intro
1. GPT
1.1. GPT 학습
1.2. GPT 모델구조
1.3. GPT 사전학습의 효과
2. GPT로 챗봇 학습해보기
2.1. 데이터 전처리
2.2. 모델 학습
2.3. 결과 확인
0. Intro
앞서 attention 레이어에 대해 자세히 살펴보고 transformer 모델에 대해 간단히 언급하고 넘어갔습니다.
Attention 레이어가 rnn 레이어에 비해 갖는 장점은 아래와 같습니다.
- 순차적으로 계산되던 rnn과 달리 시퀀스를 병렬적으로 처리하여 시간을 줄일 수 있다.
- 문장의 길이가 길어지더라도 기울기 소실 문제가 발생하지 않는다.
이 2개의 장점 중에서도 특히 첫번째 장점이 미치는 영향이 컸습니다. 이 장점으로 인해 대규모의 텍스트 데이터를 사전학습하는 것이 훨씬 수월해졌거든요.
물론 이전에도 전에 봤던 Glove, Word2Vec과 같은 사전학습된 단어 임베딩들을 사용하는 방법이 사용되어 왔습니다. 그럼에도 transformer가 혁신으로 받아들여질 수 있는 이유는 사전학습 벡터가 훨씬 유동적이기 때문입니다.
무슨 말이냐면 Glove 같은 경우 단어마다 고정된 임베딩 벡터 값을 갖습니다. 그렇기 때문에 생길 수 있는 문제는 동음이의어를 제대로 처리하기 힘들다는 것입니다.
'눈' 이라는 단어는 동물이 갖고 있는 신체의 일부를 나타내는 단어이기도 하면서 하늘에서 내리는 눈 2가지 의미를 갖는 동음이의어입니다. 그러나 이를 Glove로 학습한다면 '눈'이라는 임베딩 벡터는 하나의 고정된 값을 갖기 때문에 '하늘에서 내리는 눈'이라는 의미로 쓰였을 때나 '동물의 눈' 이라는 의미로 쓰였을 때나 똑같은 임베딩 벡터 값을 사용하게 됩니다.
이와 같이 기존의 단어 임베딩 벡터는 유동적이지 못합니다. 하지만 딥러닝 모델을 통해 생성하는 임베딩 벡터는 다릅니다. 지금부터 설명하겠지만 GPT, BERT와 같은 딥러닝 기반의 모델들은 문장 전체를 attention 구조를 통해 확인하고 단어들을 벡터화 합니다. 그렇기 때문에 같은 '눈'이라는 단어일지라도, 주변에 쓰인 맥락을 보고 서로 다른 벡터 값을 가질 수 있다는 것입니다.
이런 유동적인 부분 덕분인지 성능 차이도 엄청납니다. 그래서 이제 기본 정석은 BERT, GPT 사전학습 모델을 이용해 미세조정하는 것이죠. 그러니 NLP를 공부하고자 하는 저희도 GPT, BERT에 대해서 알아보지 않을 수가 없습니다. 지금부터 알아보도록 하죠.
1. GPT
GPT와 BERT의 가장 큰 차이는 서로 다른 사전학습 방식을 사용한다는 것입니다. GPT는 유명한 텍스트 생성형 사전학습 모델입니다. 요즘 유행하는 chatGPT 덕분에 일반인들도 그 이름을 널리 알게 되었죠. 지금부터 GPT에 대해서 알아 보겠습니다.
1.1. GPT 학습
Attention 레이어만으로 이루어진 transformer 구조 덕분에 훨씬 많은 데이터를 학습할 수 있게 된 것은 좋습니다. 하지만 그 많은 데이터를 다 라벨링할 수 있을까요? GPT1 모델 학습에 사용된 문장은 대략 7천만 개입니다. 현재 널리 알려진 chatGPT는 몇십억개는 될겁니다. 이 많은 텍스트들을 전부 라벨링하는 것은 무리겠죠? 그래서 라벨링이 필요없는 비지도 학습 방식의 사전학습 방법을 연구하게 됩니다.
GPT에서 사용한 방법은 한 문장에서 앞 글자들을 보고 그 뒤에 올 적합한 단어를 예측하는 겁니다.

위 문장에 이어질 단어로 적합한 것은 "United States" 겠죠? GPT는 이런 식으로 글자를 앞부터 하나씩 예측하며 텍스트를 생성하는 방법을 학습합니다. "George" 다음엔 "Washington"이 나오고, 그 다음엔 "was"가 나와야하고... 이런 식으로 말이죠.
그러면 라벨링이 되어 있지 않더라도 모델이 학습할 수 있을 겁니다. 데이터셋에 있는 단어들로 단어 사전을 구성한 뒤에, 모델에게 문장을 주고, 그 뒤에 적절한 단어를 단어 사전에서 골라 분류할 수 있도록. 즉, CrossEntropyLoss를 사용해 loss를 계산할 수 있게 됩니다.

GPT 학습의 input은 문장 텍스트입니다. 그리고 output 역시 문장 텍스트가 됩니다.
문장은 <sos> 혹은 <bos> 토큰으로 시작됩니다. 이 토큰은 문장의 시작을 알리는 토큰이며, <eos> 토큰은 문장의 끝을 알리는 토큰입니다.
모델은 맨 앞의 <sos> 토큰부터 차례대로 보면서 그 뒤에 올 단어들을 하나하나 예측해 <eos> 토큰을 만나 문장을 완료할 때까지 이를 반복합니다.
그래서 정확히는 아래와 같은 input과 output을 갖습니다.
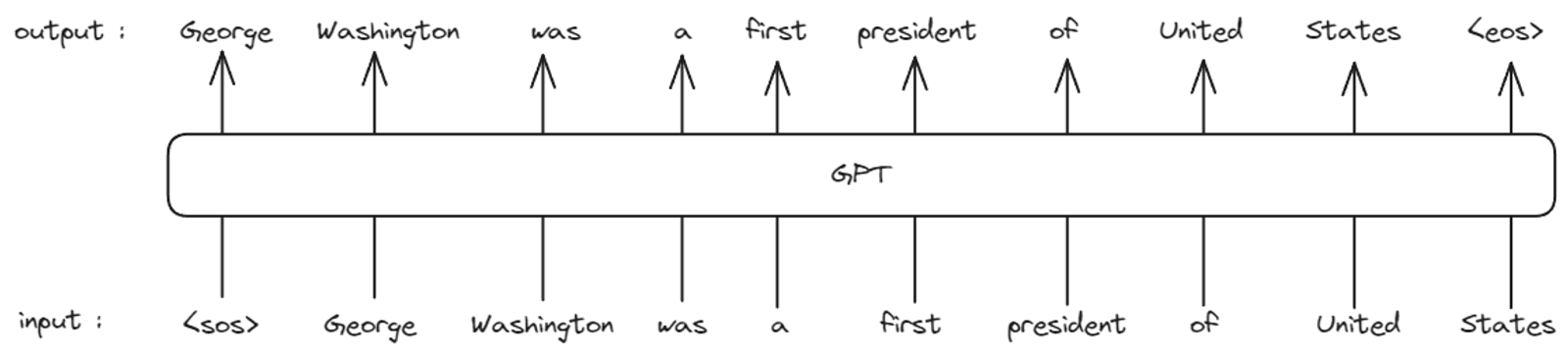
input은 <sos> 토큰을 포함하고 <eos> 토큰을 포함하지 않으며, output은 <sos> 토큰 없이 <eos> 토큰을 포함합니다. 아까 GPT는 앞 글자들을 보고 뒷 글자를 예측한다고 했죠. 그런데 이 절차를 RNN처럼 순차적으로 진행하지 않고 병렬적으로 한번에 진행합니다. 그래서 각 input 토큰의 출력물은 다음 차례 단어 토큰들이 되어 위의 구조처럼 결과물이 출력되게 됩니다. <sos> 자리에는 "George"라는 단어가, "George" 자리에는 "Washington"이라는 단어가 출력되는 것이죠.
그러나 그냥 그대로 병렬적으로 학습을 하면 attention 레이어에서 뒷 글자를 컨닝할 수도 있겠죠? 이를 방지하기 위해서 뒷 글자들을 가리는 마스킹이 추가로 적용됩니다. 그래서 정확하게는 아래와 같이 모델이 텍스트를 생성하게 됩니다.

1.2. GPT 모델구조
GPT 모델은 크게 임베딩 레이어, transformer blocks, output 3가지 부분으로 나눌 수 있습니다.

임베딩 레이어는 입력 받은 텍스트 토큰을 벡터화하는 임베딩 레이어입니다. 그리고 추가로 위치 정보 임베딩도 담당합니다. Attention 레이어의 경우 RNN 레이어와 달리 모든 시퀀스를 한번에 입력받아 처리하기 때문에 위치 정보(시간 정보)를 알기 어렵습니다.
그래서 Transformer 기반 모델들은 위치 정보를 참고하기 위해 position_id를 추가로 입력 받습니다.이 position_id는 어떤 글자가 몇번째 글자인지를 알려주기 위한 추가 input입니다. 정말 단순하게 앞 글자부터 0, 1, 2... 순으로 순서를 알려주는 역할을 합니다. 따라서 GPT 모델의 진짜 input은 아래와 같습니다.
input_ids = [82, 79, 631, 7451, ...]
position_ids = [0, 1, 2, 3, ...]
output = GPT(input_ids, position_ids)저렇게 텍스트들의 위치 정보를 숫자로 임베딩 레이어에 추가로 전달하는 것만으로도 모델의 성능이 크게 올라갑니다. 신기하죠? 그리고 최종적으로 토큰 임베딩 벡터와 위치 정보 임베딩 벡터는 서로 더해져 최종 임베딩 벡터(hidden-states)를 생성합니다.

다음으로는 GPT Block을 N개 거쳐갑니다. 이 Block은 Attention 레이어와 FeedForwardNetwork(FFN) 레이어 2개로 구성됩니다.
Attention 레이어는 앞서 봤던 multi-head attention이 사용됩니다. 그리고 앞의 정보를 잊지 않기 위한 residual 연결과 과적합 방지를 위한 normalization이 추가로 적용됩니다.
FFN 레이어는 attention 레이어에서 처리한 정보를 추가로 가공하는 역할을 합니다. 그냥 linear layer 2개와 활성화 함수, normalization 레이어로 구성되어 있는 간단한 구조입니다.

이렇게 N개의 block들을 거치고 나면 [배치 크기, 시퀀스 길이, 벡터 차원 수] 크기의 tensor를 출력하게 됩니다. 이제 각 시퀀스에 알맞는 단어 토큰(각 단어 토큰의 다음 순서 단어 토큰)을 예측하기 위한 linear layer 하나를 추가하여 최종적으로 output 문장을 출력하게 됩니다.

1.3. GPT 사전학습의 효과
우선 GPT의 사전학습 방식이 정말 효과적인지를 먼저 알아봅시다.

위 그래프는 GPT1 논문에서 제시한 오로지 사전학습만을 수행한 GPT 모델이 다양한 task에서 성능이 어떻게 변화하는지를 나타낸 그래프입니다.
보면 사전학습을 할수록 여러 task들에 대한 성능도 증가한다는 것을 확인할 수 있습니다. 즉, GPT 사전학습 방법은 모델이 언어에 대한 이해도를 갖추는데 도움이 된다는 것을 알 수 있습니다.
그런데 어떻게 task들에 미세조정을 하지 않고도 모델이 해당 task들을 수행하도록 할 수 있을까요? 그래프에 나와있는 sentiment analysis를 예시로 들어보겠습니다. sentiment analysis는 주어진 문장에 적절한 감정을 분류하는 task입니다. 연구자들은 문장이 입력되었을 때, 모델이 출력한 분류되어야 하는 감정 단어 토큰들의 log-probability를 보고 그 중 가장 높은 감정을 선택하는 방식으로 task를 수행시켰습니다.
뭔가 저희가 알고 있는 GPT와는 다르게 좀 원시적인 방법이죠? 저희가 아는 GPT라면 그냥 '이 문장의 감정이 어떤거 같아?' 하고 물어보면 알려줄 것 같은데 말이죠.
이는 모델의 크기가 커지고, 학습하는 데이터의 양이 많아지면서 가능하게 된 것 중 하나입니다. GPT3에서는 이런 방식으로 모델의 성능을 평가했습니다. GPT1과 GPT3를 단면적으로 비교해보자면,
GPT1의 학습에 사용된 텍스트 데이터셋의 양은 1GB 정도입니다. 그에 반해 GPT3에 사용된 텍스트 데이터셋의 양은 500GB가 넘습니다.
GPT1 모델의 학습 가능한 파라미터 수는 1억개 정도이지만, GPT3의 파라미터 수는 1750억개 가량입니다... 엄청난 차이죠?
물론 지금의 chatGPT가 되기까지는 이런 모델 크기, 데이터셋 양 외에도 발전된 것들이 많습니다.
어쨌거나 GPT의 사전학습 방식이 언어 모델의 성능 향상에 큰 도움을 준다는 것은 확실히 알 수 있는 단서들이었습니다.
1.4. GPT 모델 구현
이제 GPT 모델을 어떻게 사용할 수 있는지 알아보도록 하겠습니다.
다행히, 모델을 저희가 직접 처음부터 구현할 필요가 없습니다. huggingface 라이브러리를 사용하면 쉽게 모델을 구현할 수 있고, 다른 사람들이 사전학습한 모델도 쉽게 불러올 수가 있습니다.
huggingface 라이브러리는 아래 명령어로 설치가 가능합니다.
pip install transformers설치를 했으면 이제 모델을 구현해 보겠습니다.
from transformers import GPT2Model, GPT2Config
config = GPT2Config()
gpt = GPT2Model(config)GPT2Config을 통해서 GPT2 모델의 설정을 불러오고, 그 설정을 적용해 GPT2 모델을 구현한 코드입니다. 정말 간단하죠? GPT2의 config에는 아래와 같은 옵션들이 있습니다. 여기서 여러분이 수정하고 싶은 옵션이 있다면 수정하여 사용하면 됩니다.
GPT2Config {
"activation_function": "gelu_new",
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"reorder_and_upcast_attn": false,
"resid_pdrop": 0.1,
"scale_attn_by_inverse_layer_idx": false,
"scale_attn_weights": true,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"transformers_version": "4.31.0",
"use_cache": true,
"vocab_size": 50257
}지금 저희가 GPT2 사전학습을 실험해 보기에는 무리가 있습니다... 그러니 사전학습된 모델을 불러와 보도록 하겠습니다.
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
model = GPT2Model.from_pretrained("openai-community/gpt2")"openai-community/gpt2"는 openai에서 공개한 GPT2 모델입니다.(링크)

이런 모델들은 huggingface 홈페이지에서 검색할 수 있습니다. 다른 모델을 사용하고 싶다면 다른 모델의 이름을 검색해서 위 코드의 " " 안에 넣으면 됩니다.
위 코드를 실행하면 자동으로 사전학습된 GPT2 모델의 파라미터와 토크나이저를 다운 받습니다. 위 모델을 이용해서 모델에게 텍스트를 생성하도록 시켜보겠습니다.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("George washington was a first", max_length=10, num_return_sequences=5)[{'generated_text': 'George washington was a first-round draft pick'},
{'generated_text': 'George washington was a first woman-to-'},
{'generated_text': 'George washington was a first-year coach,'},
{'generated_text': 'George washington was a first round pick last season'},
{'generated_text': 'George washington was a first-round pick by'}]
그렇게 썩 만족할만한 결과는 아니네요..!
2. GPT로 챗봇 학습해보기
이번엔 사전 학습된 GPT 모델을 불러와서 간단한 챗봇 모델을 직접 만들어 보겠습니다. 전체 코드는 아래 링크에서 직접 확인하고 실행해 볼 수 있습니다.
https://colab.research.google.com/drive/1KdptFB_nkVIXOFMt8QuF0-uMDKSpuJBY?usp=sharing
GPT.ipynb
Colab notebook
colab.research.google.com
GPT 모델 학습을 위해 한국어 GPT 모델을 불러와 사용해 보겠습니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("skt/kogpt2-base-v2")
kogpt = AutoModelForCausalLM.from_pretrained("skt/kogpt2-base-v2")이 GPT 모델이 잘 학습되어 있는지 먼저 확인해 보겠습니다.
from transformers import pipeline
generator = pipeline('text-generation', model=kogpt, tokenizer=tokenizer)
generator("요즘 많이 외롭다.", max_length=20, num_return_sequences=5)
# [{'generated_text': '요즘 많이 외롭다. 내년에 꼭 꼭 한번 만나자"고 했다. 지난 주말, 서울 강서'}]문장을 잘 만들어내기는 하지만 입력 텍스트와는 큰 관련이 없어 보이는 듯 합니다.
2.1. 데이터 전처리
오늘 만들어 볼 챗봇은 간단한 상담용 챗봇 데이터셋을 이용해 학습을 수행해 볼 것입니다.
https://github.com/songys/Chatbot_data
GitHub - songys/Chatbot_data: Chatbot_data_for_Korean
Chatbot_data_for_Korean. Contribute to songys/Chatbot_data development by creating an account on GitHub.
github.com
!git clone https://github.com/songys/Chatbot_data.git위 명령어를 통해 데이터를 다운 받을 수 있습니다.
우선 데이터 전처리를 먼저 수행해 보겠습니다. 데이터셋은 csv 파일에 담겨 있습니다. 위 코드를 실행하면 다음과 같은 경로에 데이터가 담겨 있는 것을 확인할 수 있을 겁니다.

저기 있는 ChatbotData.csv를 불러와 전처리를 수행하도록 하겠습니다. 우선 질문(questions)과 대답(answers) 텍스트들을 불러오고, GPT 학습을 위해 둘을 합치는 작업을 수행할 겁니다.
import pandas as pd
csv = pd.read_csv("Chatbot_data/ChatbotData.csv")
questions = csv["Q"]
answers = csv["A"]
sentences = [q + " " + a for q, a in zip(questions, answers)]
print(sentences[0])
print(len(sentences))
sentences에는 "질문 답변" 과 같이 텍스트가 담기게 되겠죠. 이제 이를 토크나이저를 이용해 토큰화 할겁니다.
토큰화에는 당연히 사전학습에 사용된 토크나이저가 똑같이 사용되어야 합니다. 하지만 만약 여러분이 추가하고 싶은 토큰이 있다면 추가하는 것도 가능합니다. 이번엔 추가하진 않고 기존의 토크나이저를 그대로 사용할 겁니다.
def tokenize_sentences(sentences):
input_ids = []
for sentence in sentences:
data = tokenizer(sentence)
input_ids += data["input_ids"]
return input_ids
input_ids = tokenize_sentences(sentences)실제 GPT와 같이 학습하기 위해 질문과 답변 데이터들을 적정 길이에 맞춰주는 작업을 할겁니다. 적정 길이란 여러분의 컴퓨터가 버틸 수 있는 크기의 텍스트 길이를 말합니다. 저는 128로 설정했습니다. 그러면 문장들을 길이가 128이 될 때까지 합쳐서 모델이 학습을 하게 됩니다.
def split_sentences(tokens, block_size=128):
total_length = len(tokens)
n_blocks = total_length // block_size
batch = [tokens[n*block_size:(n+1)*block_size] for n in range(n_blocks)]
return batch
input_ids = split_sentences(input_ids)input_ids는 총 1311개의 텍스트 집합으로 구성되었으며, 각 텍스트 집합은 128의 길이를 갖습니다.
이렇게 만든 'input_ids'를 이용해 pytorch 데이터셋을 만들어 줄겁니다!
from torch.utils.data import Dataset
import torch
class lm_datasets(Dataset):
def __init__(self, input_ids):
super().__init__()
self.input_ids = input_ids
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
ids = torch.LongTensor(input_ids[idx])
return {"input_ids": ids, "labels": ids}
train_datasets = lm_datasets(input_ids[:1200])
test_datasets = lm_datasets(input_ids[1200:])1200개의 텍스트 집합을 훈련셋으로, 나머지를 테스트셋으로 설정하였습니다.
여기서 구현되지 않은 것은 마스킹과 input_ids를 왼쪽으로 한 칸씩 밀어서 labels를 구성하지 않은 것입니다. 이들을 구현하지 않은 이유는 transformers에서 이런 것들을 자동으로 구현해 주기 때문입니다.
from transformers import DataCollatorForLanguageModeling
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)위와 같이 DataCollator를 불러와 사용하는 것만으로 복잡한 기능들을 모두 사용할 수 있습니다.
2.2. 모델 학습
모델 학습 전과 후의 비교를 위해 모델을 하나 더 불러온 뒤에 학습을 수행할 겁니다.
chatbot = AutoModelForCausalLM.from_pretrained("skt/kogpt2-base-v2")그 뒤에 transformers의 Trainer를 사용하면 여러분이 train loop를 직접 구현하지 않아도 학습을 쉽고 빠르게 할 수 있습니다. (더 구체적인 기능들은 Trainer, TraningArguments에서 확인)
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="logs",
eval_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
)
trainer = Trainer(
model=chatbot,
args=training_args,
train_dataset=train_datasets,
eval_dataset=test_datasets,
data_collator=data_collator,
)
trainer.train()이런 언어모델의 성능 평가 지표로는 perplexity를 많이 사용합니다. perplexity는 모델이 다음 단어를 생각할 때 얼마나 많은 단어를 후보에 두고 계산했는가를 나타내는 지표입니다. 모델이 다음 단어로 적절한 단어 후보를 적게 생각할수록 문장에 대해 명확히 이해했다고 판단합니다. 즉, perplexity는 작을수록 좋습니다.
perplexity의 계산은 간단합니다.
$$\text{perplexity} = log_e{(\text{CrossEntropyLoss})}$$
import math
eval_results = trainer.evaluate()
print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
# Perplexity: 11.26랜덤 시드를 고정하지 않아 약간 차이는 있을 수 있습니다만, 11.26이라는 수치는 나쁘지 않은 수치입니다.
2.3. 결과 확인
그러면 모델이 잘 학습됐는지 직접 텍스트 생성을 다시 시켜보도록 하겠습니다! 학습 시키기 전과 비교해서 텍스트 생성 결과가 어떻게 변화했나요?
from transformers import pipeline
prompt = "요즘 많이 외롭다."
gpt_gen = pipeline('text-generation', model=kogpt, tokenizer=tokenizer)
print("before : ", gpt_gen(prompt, max_length=20, num_return_sequences=1))
chatbot_gen = pipeline("text-generation", model=chatbot, tokenizer=tokenizer)
print("after : ", chatbot_gen(prompt, max_length=20, num_return_sequences=1))
'''
before : [{'generated_text': '요즘 많이 외롭다. 고민의 순간에 그 마음이 다시 나를 따뜻하게 했다 이 말인데, 내가'}]
after : [{'generated_text': '요즘 많이 외롭다. 조금만 더 힘내주세요. 너무 힘드네. 좀이라도 덜'}]
'''어떻게 느끼실 지는 모르겠지만, 저는 더 자연스럽게 꽤 잘 학습됐다고 생각합니다. 좀 더 질문에 잘 대답을 하는 것처럼 보이지 않나요?
이렇게 간단히 사전학습된 GPT 모델을 이용해 챗봇 학습까지 해보았습니다. 내용에 비해 구현과 학습은 transformers 라이브러리가 있어서 훨씬 쉽게 느껴지지 않나요?
이 다음에는 다른 유형의 사전학습 모델인 BERT에 대해서도 알아보도록 하겠습니다!
'NLP 기초' 카테고리의 다른 글
| [NLP-6] Masking을 이용한 언어 사전 학습 모델 BERT (0) | 2024.07.30 |
|---|---|
| [NLP-4] Attention is all you need, Transformer의 등장 (0) | 2024.04.24 |
| [NLP-3] 언어 임베딩 : word2vec과 glove (3) | 2024.03.19 |
| [NLP-2] 텍스트 전처리하기 - 토크나이저 (4) | 2024.02.28 |
| [NLP-1] 인공지능이 텍스트를 처리하는 방법 (1) | 2024.02.14 |



