1. Decision Tree
1.1. CART 알고리즘
A. 분류 문제
B. 회귀 문제
2. Pruning
2.1. 소제목
2.2. 소제목
3. Decision Tree의 주요 특징
3.1. Decision Tree의 장점
3.2. Decision Tree의 단점
4. Decision Tree 코드 구현
4.1. scikit-learn에서의 Decision Tree
4.2. scikit-learn 모델 실험
A. 정규화
B. Criterion
C. Pruning
1. Decision Tree
Decision Tree는 트리 구조를 사용해 데이터를 분류, 회귀하는 방법입니다. 학습 파라미터가 필요 없습니다.
1.1. CART 알고리즘
트리를 만드는 데는 다양한 알고리즘이 사용될 수 있지만, scikit-learn에서 사용하는 CART 알고리즘에 대해서만 알아 보도록 하겠습니다.
CART 알고리즘의 주요 특징은 아래와 같습니다.
- 이진 트리 구조를 갖는다.
- 각 노드마다 기준을 정해 데이터를 분류한다.
- 노드의 기준은 퀄리티를 측정하여 높은 퀄리티의 기준을 선정한다.
- 기준의 퀄리티는 불순도(impurity) 측정 또는 손실 함수(loss function)을 통해 계산한다.
Deicision Tree를 만드는 과정은 간단합니다. 루트 노드에서 시작해 노드마다 최적의 기준을 정하고 데이터를 나누는 과정을 더 이상 나눌 수 없을 때까지 반복하면 됩니다.
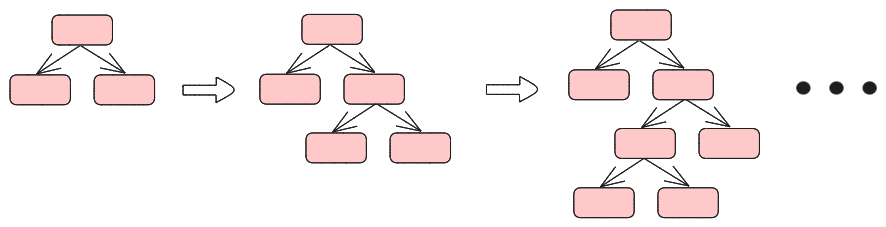
쉽게 이해하기 위해서 임의의 iris 데이터를 가정하고, CART 알고리즘을 이용해 이를 분류하는 것을 직접 해보도록 하겠습니다.
1. 전체 데이터를 담는 루트 노드에서 시작한다.

우선 루트 노드에는 모든 데이터셋이 들어가게 됩니다. 이제 최적의 기준을 찾아 이 데이터를 둘로 나눌 겁니다.
2. 노드 분할을 위해 최적의 threshold를 찾는다.

- 예시로 petal_length<17, petal_width<12, 2개의 기준 중에 더 뛰어난 기준을 선정해 보도록 하겠습니다.
- Gini 불순도 계산을 통해 기준의 퀄리티를 측정해 볼겁니다. Root Node의 Gini 불순도와, 기준으로 인해 분리된 두 노드의 Gini 불순도를 계산해 보도록 하겠습니다.
- Gini 불순도 : 데이터 집합의 불순도를 측정하는 지표.$$G=1-\sum^K_{k=1}P(k|t)^2$$
$P(k|t)$ : 노드 t에서 라벨 k의 비율. - 부모 노드의 Gini 불순도
$$1-\{({50\over150})^2+({50\over150})^2+({50\over150})^2\}=0.666$$ - 각 기준(Case)마다의 Gini 불순도를 계산합니다.
- 왼쪽 노드와 오른쪽 노드의 불순도를 각각 계산.
<Case 1>
Left : $$1-\{({16\over150})^2+({47\over150})^2+({22\over150})^2\}=1-(0.011+0.098+0.021)=0.87$$
Right : $$1-\{({34\over150})^2+({3\over150})^2+({28\over150})^2\}=1-(0.051+0.000+0.034)=0.915$$
<Case 2>
Left : $$1-\{({16\over150})^2+({39\over150})^2+({15\over150})^2\}=1-(0.011+0.067+0.010)=0.912$$
Right : $$1-\{({34\over150})^2+({11\over150})^2+({35\over150})^2\}=1-(0.051+0.005+0.054)=0.89$$ - 각 노드의 데이터 수의 비율을 고려하여 왼쪽 노드와 오른쪽 노드의 불순도를 더한다.
<Case 1>
Total : $${N_{left}\over N}\text{Gini}_{left}+{N_{right}\over N}\text{Gini}_{right}={85\over150}*0.87+{65\over150}*0.915=0.493+0.396=0.889$$
<Case 2>
Total : $${N_{left}\over N}\text{Gini}_{left}+{N_{right}\over N}\text{Gini}_{right}={70\over150}*0.912+{80\over150}*0.89=0.425+0.474=0.899$$ - 부모 노드의 Gini 불순도와 자식 노드의 Gini 불순도의 차이(information gain)를 계산해 더 큰 쪽의 기준을 선택한다.
<Case 1>
$$0.666 - 0.87=-0.204$$
<Case 2>
$$0.666 - 0.899 = -0.233$$
이 경우, <Case 1>의 information gain이 더 크므로 <Case 1>의 기준이 더 적합하다고 볼 수 있다.
- 왼쪽 노드와 오른쪽 노드의 불순도를 각각 계산.
- Gini 불순도 : 데이터 집합의 불순도를 측정하는 지표.$$G=1-\sum^K_{k=1}P(k|t)^2$$

3. 위 과정을 더 이상 나눌 수 없을 때까지, 혹은 미리 지정한 횟수까지 반복한 뒤 종료한다.

위에선 Gini 불순도를 이용해 기준의 퀄리티를 측정하였지만 다른 척도들도 사용이 가능합니다.
A. 분류 문제
분류 문제에서는 CrossEntropy Loss나, Gini impurity를 계산하여 기준의 퀄리티를 측정합니다.
- CrossEntropy
$$H(Q)=-\sum p\text{log}(p)$$ - Gini impurity
$$H(Q)=\sum p (1-p)$$
* $p$ : 노드에서 각 라벨이 존재하는 비율.
라벨은 각 노드에서 가장 많은 수를 갖는 라벨로 결정합니다. 예를 들어 한 노드에 setosa가 6개, verginica가 27개가 있다면 이 노드의 라벨은 verginica가 됩니다.
B. 회귀 문제
회귀 문제에서는 MSE, MAE, Poisson devian 3가지를 사용해 기준의 퀄리티를 측정합니다.
- MSE
$$H(Q)={1\over n}\sum^n_{i=1}(y_i-\bar{y})^2$$ - MAE
$$H(Q)={1\over n}\sum^n_{i=1}|y_i-\bar{y}|$$ - Poisson devian
$$H(Q)={2\over n}\sum^n_{i=1}(y\text{log}{y\over\bar{y}}-y+\bar{y})$$
Poisson devian의 경우 개수나 빈도 수 를 예측할 때(즉 예측값이 정수일 때) 사용하면 좋다고 합니다. 예측값의 경우 각 노드의 출력값의 평균으로 값을 예측하게 됩니다. 예를 들어 [17, 23, 42, 19] 4개의 결과값이 있다면, 예측값은 이들의 평균인 25로 결정됩니다.
2. Pruning
Decision Tree는 과적합 되기 쉽습니다. 그래서 이를 방지하기 위해 pruning 기법이 사용됩니다.
가장 쉬운 방법으로는 트리의 깊이를 제한하거나 노드에 들어갈 수 있는 데 필요한 최소한의 데이터 수를 제한하는 식으로 노드가 지나치게 많아지는 것을 방지할 수 있습니다.
다른 방법으로는 ccp-alpha 수치를 조절하는 방법도 있습니다.
2.1. ccp-alpha
정말 간단하게 설명하자면, ccp-alpha 수치가 높아질수록 트리의 깊이나 노드의 수가 작아집니다. 즉, ccp-alpha 수치를 높일수록 과적합을 방지할 수 있지만 너무 높이면 underfitting될 위험도 높아집니다.
ccp-alpha가 pruning하는 노드들의 특징은 아래와 같습니다.
- 노드의 데이터가 너무 잘 분류되어 있어 더 이상 분할해도 의미가 없는 경우
- 노드에 포함되어 있는 데이터의 수가 너무 적은 경우
- 리프노드(노드 아래에 있는 자식노드가 없는 맨 아래의 노드)의 수가 많은 경우
요약해서 말하자면, ccp-alpha는 분류에 큰 기여를 하지 못하는 노드들부터 줄여나가도록 해주는 파라미터라고 볼 수 있습니다.
3. Decision Tree 주요 특징
이렇듯, Decision Tree는 KNN과 마찬가지로 파라미터를 사용하지 않고 학습이 가능한 머신러닝 기법입니다. 다만 데이터를 분류하는 기준을 결정해야 하기 때문에 KNN과 달리 학습은 필요합니다. 이로 인해 발생하는 Decision Tree의 장점과 단점에 대해 알아보겠습니다.
3.1. Decision Tree의 장점
- 트리를 시각화할 수 있으며, 분류 기준의 이해와 해석이 쉽습니다.
- 기준을 feature 하나씩 선정하기 때문에 정규화와 같은 데이터 전처리의 영향이 크지 않습니다.
- 비선형 데이터도 처리할 수 있습니다.
3.2. Decision Tree의 단점
- 트리가 지나치게 깊어져 과적합 되기 쉽습니다.
- 작은 예외 데이터에도 영향을 크게 받을 수 있습니다.
- optimal한 decision tree를 만드는 것이 쉽지 않습니다.
위와 같은 단점들로 인해 복잡한 데이터셋일수록 Decision Tree의 성능은 급격히 떨어집니다. 그래서 이를 극복하기 위해 앙상블 기법을 사용합니다. 다음에 살펴 볼 Random Forest가 Decision Tree들의 앙상블을 이용해 분류/회귀를 수행하는 머신러닝 기법입니다. 이는 다음 글에서 자세히 안내하도록 하겠습니다.
4. Decision Tree 코드 구현
4.1. scikit-learn에서의 Decision Tree
https://scikit-learn.org/dev/modules/generated/sklearn.tree.DecisionTreeClassifier.html
DecisionTreeClassifier
Gallery examples: Release Highlights for scikit-learn 1.3 Classifier comparison Plot the decision surface of decision trees trained on the iris dataset Post pruning decision trees with cost complex...
scikit-learn.org
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(
criterion='gini', #{"gini", "entropy", "log_loss"}
max_depth=None, # integer
min_samples_split=2,
min_samples_leaf=1,
max_features=None
)
clf.fit(x_train, y_train)- criterion : 불순도 측정에 사용할 지표를 지정합니다.
- max_depth : 생성될 이진 트리의 최대 깊이를 제한합니다.
- min_samples_split : 노드로 분할되기 위해 필요한 최소한의 데이터 샘플 수를 지정합니다.
- min_samples_leaf : 리프 노드가되기 위해 필요한 최소한의 데이터 샘플 수를 지정합니다.
- max_features : 노드의 분할 기준을 정할 때 고려할 입력 특성(feature)의 수를 지정합니다.
4.2. Decision Tree 모델 실험
이번에도 breast cancer 데이터셋을 이용해 Decision Tree의 성능을 테스트해 보도록 하겠습니다.
https://colab.research.google.com/drive/1gHKkQuPxGi-h2QDOWb44ZPRZsZ9vNfKv?usp=sharing
Decision Tree.ipynb
Colab notebook
colab.research.google.com
A. 정규화
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
clf = DecisionTreeClassifier(
criterion='gini',
min_samples_split=2,
ccp_alpha=0
)
clf.fit(train_x, train_y)
print("정규화 하기 전 : ", clf.score(test_x, test_y))
pipeline = Pipeline(
[('scaler', StandardScaler()), ('model', clf)]
)
pipeline.fit(train_x, train_y)
print("정규화 한 후 : ", pipeline.score(test_x, test_y))
'''
정규화 하기 전 : 0.9035087719298246
정규화 한 후 : 0.9298245614035088
'''K-NN만큼은 아니지만 정규화에 의해 성능이 달라지는 것을 확실히 확인할 수 있습니다.
B. Criterion
criterions = ['gini', 'entropy', 'log_loss']
for criterion in criterions:
clf = DecisionTreeClassifier(
criterion=criterion,
min_samples_split=2,
max_features=None,
ccp_alpha=0
)
pipeline = Pipeline(
[('scaler', StandardScaler()), ('model', clf)]
)
pipeline.fit(train_x, train_y)
print(f"{criterion} : {pipeline.score(test_x, test_y)}")
'''
gini : 0.9210526315789473
entropy : 0.9473684210526315
log_loss : 0.9385964912280702
'''실행할 때마다 달라지긴 하지만 대체로 'entropy loss'가 제일 높은 정확도가 나왔습니다. 이런 식으로 3가지 criterion을 바꿔가면서 실험해보고 최적의 결과를 선택할 수 있습니다.
C. Pruning
<min_samples_split>
2 : 0.9385964912280702
5 : 0.9210526315789473
10 : 0.9210526315789473
20 : 0.9473684210526315
<max_features>
2 : 0.9298245614035088
5 : 0.9298245614035088
10 : 0.956140350877193
20 : 0.9210526315789473
30 : 0.9298245614035088
<ccp_alpha>
0 : 0.9473684210526315
0.01 : 0.9385964912280702
0.1 : 0.9035087719298246
0.5 : 0.9035087719298246
1.0 : 0.6666666666666666
트리 pruning과 관련된 옵션들을 건드려 본 결과, min_samples=20일 때 성능이 제일 좋게 나왔고, ccp_alpha는 0으로 하는 것이 제일 좋게 나왔습니다.
max_features의 경우 랜덤으로 특성 feature들을 선택하는 특성 상 실행할 때마다 성능이 크게 달라지는 것을 알 수 있었습니다.
이렇듯 Decision Tree는 파라미터는 없지만 학습 과정 자체에는 랜덤성이 존재합니다. 예를 들면 불순도를 계산했을 때 동점인 상황이 발생하거나, max_features와 같은 옵션을 설정했을 때와 같이 말이죠. 따라서 다양하게 실험해보고 최적의 모델을 선택하는 것이 중요합니다.
만약 이런 랜덤성을 통제하고 싶다면 random_state 옵션을 설정할 수도 있습니다.
Decision Tree의 이런 불안정한 실험 결과가 마음에 들지 않는다면 Random Forest를 사용해 이를 줄일 수 있습니다.https://all-the-meaning.tistory.com/70
[머신러닝] 3. Random Forest
1. Random Forest 1.1. Random Forest의 알고리즘2. Random Forest의 특징 2.1. 장점 2.2. 단점3. Random Forest 코드 구현 3.1. scikit-learn에서의 Random Forest 3.2. Random Forest 모델 실험
all-the-meaning.tistory.com
1. KNN : https://all-the-meaning.tistory.com/65
3. Random Forest : https://all-the-meaning.tistory.com/70
4. Linear/Logistic Regression : https://all-the-meaning.tistory.com/71
5. SVM : https://all-the-meaning.tistory.com/72
6. 머신러닝 총정리 : https://all-the-meaning.tistory.com/73
'머신러닝 알아보기' 카테고리의 다른 글
| [머신러닝] 5. SVM (Support Vector Machine) (1) | 2024.12.04 |
|---|---|
| [머신러닝] 4. Linear Regression과 Logistic Regression (1) | 2024.12.03 |
| [머신러닝] 3. Random Forest (0) | 2024.11.27 |
| [머신러닝] 1. KNN (K-Nearest Neighbors) (0) | 2024.11.26 |
| [머신러닝] 0. 머신러닝 공부에 들어가기 앞서 (0) | 2024.11.26 |



