Matplotlib이란
데이터 분석을 위해선 데이터를 보기 좋게 시각화 하는 작업이 필수입니다. 파이썬의 matplotlib은 다양한 데이터 시각화에 자주 사용되는 라이브러리입니다.
오늘은 matplotlib을 활용해 그릴 수 있는 그래프 몇 가지를 알아보고 어떤 식으로 활용하면 좋을 지에 대해 이야기 해보도록 하겠습니다.
matplotlib 설치는 커맨드 창에 아래와 같은 명령어를 사용해 쉽게 설치 가능합니다.
pip install matplotlib
설치된 matplotlib은 코드에서 아래와 같이 import할 수 있습니다. ('plt'로 불러오는 것이 국룰입니다.)
import matplotlib.pyplot as plt
이번 데이터 시각화에 활용되는 데이터셋은 모두 kaggle에서 다운 받을 수 있습니다.
- Mobiles Dataset : https://www.kaggle.com/datasets/abdulmalik1518/mobiles-dataset-2025?resource=download
(스마트폰의 출시 스펙/가격/일시를 기록한 데이터셋.)
Mobiles Dataset - NVIDIA Stock Volatility (2014-2024) : https://www.kaggle.com/datasets/avinashmynampati/nvidia-stock-volatility-20142024
(2014~2024년의 NVIDIA 주가 변동 수치를 기록한 데이터셋.)
NVIDIA Stock Volatility (2014-2024) - Global Music Streaming Trends & Listener Insights : https://www.kaggle.com/datasets/atharvasoundankar/global-music-streaming-trends-and-listener-insights
(음원 서비스 이용자들의 정보와 들은 음원 관련 정보를 기록한 데이터셋.)
Global Music Streaming Trends & Listener Insights - IRIS Dataset : scikit-learn에서 다운 가능.
(setosa, verginica, versicolor 3 종류의 꽃잎들의 길이를 기록한 데이터셋.)
전체 코드는 아래 링크에서 확인 가능합니다.
https://drive.google.com/file/d/1X-BucFTxz59yGRucsC6GA43g74X-nS8m/view?usp=sharing
matplotlib.ipynb
drive.google.com
1. plot
2. scatter
3. bar plot
4. fill_between
5. stackplot
6. hist
7. boxplot
8. pie
9. 공통적으로 활용되는 코드
1. plot
plot은 1차원 리스트 형태의 데이터를 점/선 그래프 형태로 그려줍니다. 가장 쉽게 활용할 수 있는 형태이기도 합니다.
x축의 변화에 따른 y축의 변화를 보고 싶을 때 사용하면 좋습니다.
여기선 NVIDIA 주식 데이터를 이용해 2014년부터 2024년까지 주가가 어떻게 변화했는지를 그려보겠습니다.
plt.plot(nvidia_df["High"])
plt.xticks(nvidia_df.index[::500], nvidia_df["Date"][::500], rotation=45)
plt.show()
코드도 되게 간단합니다. 'plt.plot()'안에 보고 싶은 데이터를 넣기만 하면 됩니다. x축과 y축의 데이터를 나눠서 넣어줘도 되고, 위와 같이 하나만 넣어도 됩니다.
'plt.xticks()' 명령어는 x축의 이름을 설정하는 코드입니다. 총 2500개의 주가 데이터가 있기 때문에 약 500칸마다 날짜를 표시하고 싶어서 위와 같이 코드를 작성했습니다. 또, 글자가 겹치는 것을 피하기 위해 'rotation=45'를 추가해 글자를 회전시켰습니다.
만약 점선 형태로 보고 싶다면 'plt.plot()' 안에 '-o'를 추가해 주면 됩니다.
'-'는 선 그래프를, 'o'는 점 그래프를 나타냅니다.
plt.plot(nvidia_df["High"][2000:2010], '-o') # '-'만 쓰면 선그래프를, 'o'만 쓰면 점그래프를 그려줌.
plt.xticks(range(2000, 2010), nvidia_df["Date"][2000:2010], rotation=45)
plt.show()
2. scatter
scatter()는 산점도 그래프를 그려줍니다. plot()이 x축과 y축의 변화량에 따른 관계를 보고 싶을 때 사용한다면, scatter()는 x축과 y축 데이터의 관계를 확인하고 싶을 때 사용합니다.
- x : 비교할 데이터1 (x축)
- y : 비교할 데이터2 (y축)
scatter()를 이용해 IRIS 데이터셋의 꽃들을 가장 구분하기 좋은 기준을 찾아보겠습니다.
# subplots()를 이용하면 여러 개의 그래프를 그릴 수 있음.
# (1, 4) : 가로로 4개의 그래프를 그림.
# figsize : 전체 그래프(4개를 합친)의 크기를 지정.
fig, ax = plt.subplots(1, 4, figsize=(20, 4))
# sepal length와 sepal width를 기준으로 분류한 그래프
ax[0].scatter(setosa["sepal length (cm)"], setosa["sepal width (cm)"], label="setosa")
ax[0].scatter(versicolor["sepal length (cm)"], versicolor["sepal width (cm)"], label="versicolor")
ax[0].scatter(virginica["sepal length (cm)"], virginica["sepal width (cm)"], label="verginica")
ax[0].set_xlabel("sepal length (cm)")
ax[0].set_ylabel("sepal width (cm)")
ax[0].legend()
# petal length와 petal width를 기준으로 분류
ax[1].scatter(setosa["petal length (cm)"], setosa["petal width (cm)"], label="setosa")
ax[1].scatter(versicolor["petal length (cm)"], versicolor["petal width (cm)"], label="versicolor")
ax[1].scatter(virginica["petal length (cm)"], virginica["petal width (cm)"], label="verginica")
ax[1].set_xlabel("petal length (cm)")
ax[1].set_ylabel("petal width (cm)")
ax[1].legend()
# petal length와 sepal length를 기준으로 분류
ax[2].scatter(setosa["petal length (cm)"], setosa["sepal length (cm)"], label="setosa")
ax[2].scatter(versicolor["petal length (cm)"], versicolor["sepal length (cm)"], label="versicolor")
ax[2].scatter(virginica["petal length (cm)"], virginica["sepal length (cm)"], label="verginica")
ax[2].set_xlabel("petal length (cm)")
ax[2].set_ylabel("sepal length (cm)")
ax[2].legend()
# sepal width와 petal width를 기준으로 분류
ax[3].scatter(setosa["sepal width (cm)"], setosa["petal width (cm)"], label="setosa")
ax[3].scatter(versicolor["sepal width (cm)"], versicolor["petal width (cm)"], label="versicolor")
ax[3].scatter(virginica["sepal width (cm)"], virginica["petal width (cm)"], label="verginica")
ax[3].set_xlabel("sepal width (cm)")
ax[3].set_ylabel("petal width (cm)")
ax[3].legend()
sepal width / sepal length / petal width / petal length 4개의 기준을 2개씩 묶어서 scatter() 그래프를 그려 봤습니다.
가장 첫번째 그래프(sepal width - sepal length)를 보면 이 2가지 기준으론 꽃잎을 분류하기 어려워 보입니다. 대신 2번째 그래프(petal width - petal length)를 보면 3종류의 꽃이 잘 구분되는 것을 확인할 수 있습니다.
이를 통해 petal width와 petal length를 기준으로 하면 3가지 꽃을 분류하기 쉽다는 것을 알 수 있습니다!
3. bar plot

bar plot은 막대 그래프를 그려줍니다. 수치들을 비교하고 싶을 때 사용하면 좋습니다.
- x : 표시할 막대 그래프의 수. (x축)
- height : 각 막대 그래프의 수치. (y축)
IRIS 데이터셋의 setosa, versicolor, virginica 꽃들의 평균 꽃잎 길이를 막대 그래프로 그려보겠습니다. 꽃이 3종류 이므로 x축은 'range(3)'으로, y축은 각 꽃의 꽃잎 길이 평균을 표시할 것입니다.
import numpy as np
setosa = iris_df[iris_df["label"]=="setosa"]
versicolor = iris_df[iris_df["label"]=="versicolor"]
virginica = iris_df[iris_df["label"]=="virginica"]
fig, ax = plt.subplots(1, 4, figsize=(20, 4))
for i, feat in enumerate(iris.feature_names):
# 각 꽃의 평균 꽃잎 길이 계산
setosa_avg = sum(setosa[feat])/len(setosa[feat])
versicolor_avg = sum(versicolor[feat])/len(versicolor[feat])
virginica_avg = sum(virginica[feat])/len(virginica[feat])
# 꽃 종류가 3개이므로 x축은 3칸으로, y축은 각 꽃의 평균 값 기록.
x = range(3)
y = [setosa_avg, versicolor_avg, virginica_avg]
# 막대 그래프 그리기
ax[i].bar(x, y, width=0.5, linewidth=0.5)
# x축에 꽃 종류 표시
ax[i].set_xticks(range(3), ["setosa", "versicolor", "virginica"])
# 그래프의 상단부에 여유를 주기 위해 ylim 추가
ax[i].set_ylim(0, max(y)+1)
# 그래프 위에 평균 값 텍스트로 표시하기.
for j, value in enumerate(y):
ax[i].text(j, value+0.1, f"{value:.1f}", ha="center", fontsize=10)
# 각 그래프가 나타내는 꽃잎 길이 제목으로 표시
ax[i].set_title(feat)
막대 그래프로 시각화한 결과, 각 꽃의 평균 꽃잎 길이를 보기 좋게 비교할 수 있게 되었습니다. 4번째 그래프를 보면 petal width가 가장 짧은건 setosa고, 가장 긴 건 virginica인 것을 한 눈에 알 수 있습니다.
4. fill_between
fill_between은 2개의 선형 그래프의 사이를 채워서 그려주는 그래프 형태입니다. 두 그래프 사이의 수치 차이를 강조하고 싶을 때 사용하면 좋습니다.
- x : 비교할 두 데이터의 서로 같은 x값.
- y1 : 첫번째 데이터의 y값.
- y2 : 두번째 데이터의 y값.
2022년의 1년치 NVIDIA 주가와 2023년의 1년치 NVIDIA 주가를 날짜 별로 비교하는 그래프를 그려보겠습니다.
nvidia2022 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2022")]
nvidia2023 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2023")]
length = min(len(nvidia2022), len(nvidia2023))
x = np.arange(0, length)
y1 = np.array(nvidia2022["Close"].iloc[:length])
y2 = np.array(nvidia2023["Close"].iloc[:length])
# alpha : fill_between의 색상 진하기
plt.fill_between(x, y1, y2, alpha=.5)
plt.plot(x, (y1+y2)/2, linewidth=2, label="mean")
plt.plot(y1, label="2022")
plt.plot(y2, label="2023")
# x축에 날짜 표시하기
dates = [date.replace("2022-", "") for date in nvidia2022["Date"].iloc[::50]]
plt.xticks(range(0, length+1, 50), dates)
plt.legend()
plt.show()
그래프를 보면 1분기엔 2022년에 오히려 주가가 더 높았었지만, 2분기부터 2022년과 2023년의 주가 차이가 크게 벌어지는 것을 확인할 수 있습니다.
5. stackplot

stackplot은 x축의 증가에 따른 y축의 누적량을 표시하기 좋은 그래프입니다. 판매량과 같이 누적되는 수치를 보여주기 좋은 그래프입니다.
2021년부터 2023년까지 NVIDIA 날짜 별 주식 거래량을 stackplot()을 이용해 그려보겠습니다.
nvidia2021 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2021")]
nvidia2022 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2022")]
nvidia2023 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2023")]
length = min(len(nvidia2021), len(nvidia2022), len(nvidia2023))
x = np.arange(0, length)
y1 = np.array(nvidia2021["Volume"][:length])
y2 = np.array(nvidia2022["Volume"][:length])
y3 = np.array(nvidia2023["Volume"][:length])
y = np.vstack([y1, y2, y3])
plt.stackplot(x, y, labels=["2021", "2022", "2023"])
dates = [date.replace("2022-", "") for date in nvidia2022["Date"].iloc[::50]]
plt.xticks(range(0, length+1, 50), dates)
plt.yticks([0.5e9, 1.0e9, 1.5e9, 2.0e9, 2.5e9], ["50M", "100M", "150M", "200M", "250M"])
plt.legend()
plt.show()
대략 2월, 5월, 8월, 11월 즈음에 주문량이 가장 많았던 것을 확인할 수 있으며, 판매량이 계속 누적된 것도 시각적으로 확인하기 좋습니다.
6. hist
hist()는 bar()와 같이 막대 그래프 형태이지만, hist()는 데이터를 구간 별로 나눠서 보여줍니다. 데이터를 특정 구간으로 나눠서 보고 싶을 때 사용하면 좋습니다.
- x : 확인 할 데이터
- bins : 데이터 구간
2024년도에 출시된 스마트폰들의 가격대를 300달러 구간으로 나눠서 확인해 보도록 하겠습니다.
mobile_df2024 = mobile_df[mobile_df["Launched Year"]==2024]
prices = [float(usd.replace("USD ", "").replace(",", "")) for usd in mobile_df2024["Launched Price (USA)"][:-1]]
bins = [0, 300, 600, 900, 1200, 1500, 1800]
# counts : 각 구간에 속한 데이터의 수
# edges : 각 구간의 경계값.
counts, edges, _ = plt.hist(prices, bins=bins, edgecolor="white")
plt.xticks(bins)
plt.xlabel("Price (USD)")
plt.ylabel("Number of phones")
for count, edge in zip(counts, edges[:-1]):
# edge + (edges[1] - edges[0]) : 텍스트의 x축 위치 (막대 그래프의 중앙)
# count : 텍스트의 y축 위치
# ha, va : 텍스트 정렬
plt.text(edge + (edges[1] - edges[0]) / 2, count, f"{int(count)}", ha="center", va="bottom")
plt.show()
그래프를 보면 300~600달러 사이 가격대의 휴대폰이 가장 출시된 것을 알 수 있습니다. 이런 식으로 hist()는 데이터를 특정 구간 별로 나눠서 보기 좋습니다.
7. boxplot

boxplot은 데이터의 분포를 확인하기 좋은 그래프입니다.
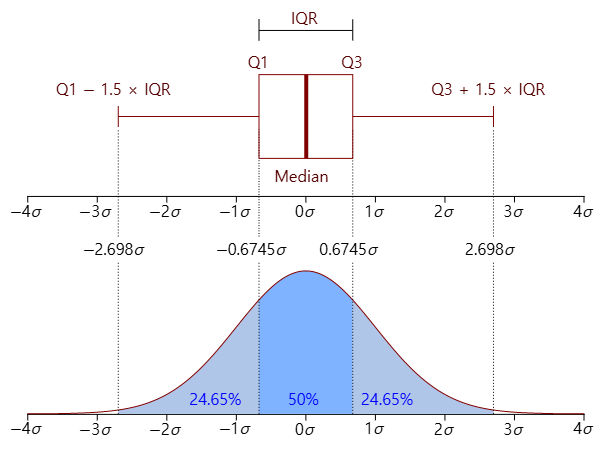
boxplot 그래프의 중앙 선은 전체 데이터의 중앙값(Median)을 나타내며, 박스 영역은 하위 25%(Q1)부터 상위 75%(Q3) 사이의 범위를 나타냅니다.
IQR은 Q3-Q1 값을 나타내며, 여기에 1.5(whis)를 곱한 값의 범위까지를 정상적인 데이터 분포로 봅니다. 이 범위는 박스 밖의 직선 그래프로 표시됩니다.
직선 밖의 원으로 표시되는 데이터들은 이상치로, 평균 데이터 분포를 벗어나는 이상치(outliers)라고 볼 수 있습니다.
- x : 분포를 확인하기 위한 데이터
- whis : 이상치 판별 범위를 조절하는 수치(기본=1.5). 작아질수록 이상치로 분류되는 데이터가 많아집니다.
boxplot()을 이용해 2024년과 2023년에 출시된 스마트폰 가격 분포를 시각화 해보겠습니다.
mobile_df2024 = mobile_df[mobile_df["Launched Year"]==2024]
prices2024 = [float(usd.replace("USD ", "").replace(",", "")) for usd in mobile_df2024["Launched Price (USA)"][:-1]]
mobile_df2023 = mobile_df[mobile_df["Launched Year"]==2023]
prices2023 = [float(usd.replace("USD ", "").replace(",", "")) for usd in mobile_df2023["Launched Price (USA)"]]
plt.boxplot((prices2024, prices2023), whis=1.0, patch_artist=True, tick_labels=["2024", "2023"])
plt.yticks([i*300 for i in range(10)])
plt.show()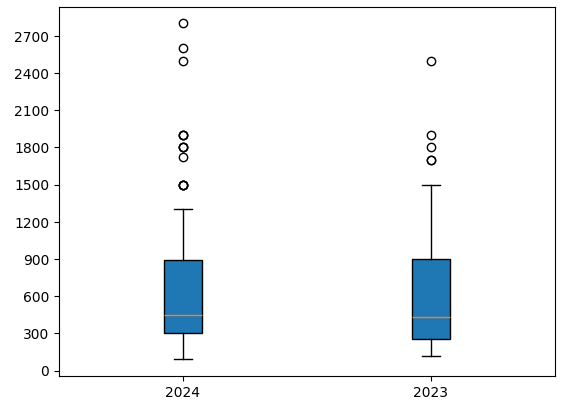
이를 보면 스마트폰의 가격이 보통 300~900달러이며, 1500 달러 이상의 스마트폰들은 예외적으로 비싼 휴대폰들이란 것을 알 수 있습니다.
또, 박스와 직선 그래프를 봤을 때 2023년에 출시된 스마트폰들의 가격이 조금 더 높은 것도 알 수 있습니다.
8. pie
pie()는 원형 그래프를 그려줍니다. 라벨 간의 데이터 수를 비교할 때 사용하기 좋습니다.
Global streaming music 데이터셋에서 사람들이 어떤 장르의 음악을 주로 들었는지 확인해 보겠습니다.
from collections import Counter
# 샘플 데이터
cnt = Counter(music_df["Top Genre"])
genres = list(cnt.keys())
counts = list(cnt.values())우선 Counter를 활용해 각 장르 별로 재생된 횟수를 체크했습니다. genres와 counts 리스트를 활용해 원형 그래프를 그려보겠습니다.
# 원형 그래프 그리기
fig, ax = plt.subplots(figsize=(7, 7))
wedges, texts = ax.pie(counts, radius=3,
wedgeprops={"linewidth": 1, "edgecolor": "white"}, frame=True)
# x축과 y축의 눈금 표시 제거.
ax.set_xticks([])
ax.set_yticks([])
# 원형 그래프 안에 이름, 수치, 퍼센트 표시
for i, wedge in enumerate(wedges):
# 원형 그래프의 각 조각의 중심 좌표를 가져오기
angle = (wedge.theta1 + wedge.theta2) / 2
# 텍스트의 위치(x, y)를 조절.
x = 0.7 * (wedge.r * np.cos(np.radians(angle)))
y = 0.7 * (wedge.r * np.sin(np.radians(angle)))
# 텍스트 배치
percentage = counts[i] / sum(counts) * 100
ax.text(x, y, f"{genres[i]}\n{counts[i]} ({percentage:.1f}%)", ha='center', va='center', color='white')
plt.show()
모든 장르를 비슷한 비율로 들은 것을 확인할 수 있었습니다. 이와 같이 bar()처럼 데이터 간의 수치를 비교하는데 사용하기 좋은 그래프입니다.
9. 공통적으로 활용되는 코드
지금까지 다양한 그래프들에 대해 알아 봤습니다. 여기서 공통적으로 사용된, 보기 좋은 그래프를 그리는데 필요한 코드들을 정리해 보겠습니다.
fig, ax = plt.subplots(nrows, ncols)
여러 개의 그래프를 한 번에 그리고 싶을 때 사용하는 코드입니다. subplots() 안에 그래프의 가로, 세로 숫자와 그래프의 크기 등을 조절할 수 있습니다.
각 그래프에는 인덱싱을 이용해 접근할 수 있습니다.
fig, ax = plt.subplots(2, 2, figsize=(10, 10))
ax[0][0].plot(data_a)
ax[0][0].set_title("plot")
ax[0][1].hist(data_b, bins=[5, 10, 15, 20])
ax[0][1].set_title("hist")
ax[1][0].boxplot(data_a)
ax[1][0].set_title("boxplot_A")
ax[1][1].boxplot(data_b)
ax[1][1].set_title("boxplot_B")또, 이렇게 그래프를 그릴 경우엔 xlabel(), xticks() 등의 명령어들을 쓸 때 앞에 'set_'을 붙여줘야 합니다. 예를 들면, 원래는 plt.xlabel()과 같이 썼었다면, 위와 같이 쓸 경우엔 ax[0].set_xlabel()로 바꿔 써야 합니다.
xlabel(), ylabel()
그래프의 x축, y축 이름을 설정하는 명령어 입니다.
plt.plot(nvidia_df["High"])
plt.xlabel("Date")
plt.ylabel("Price")
plt.show()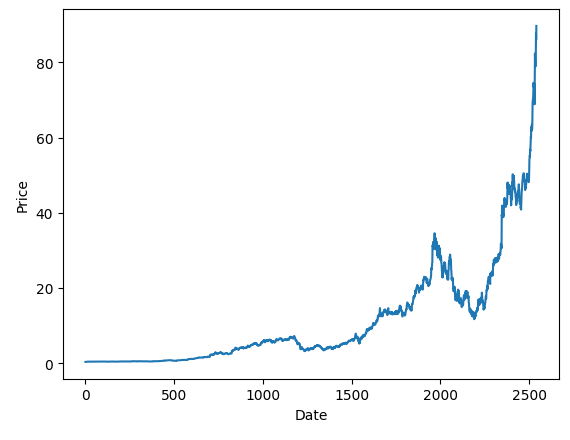
xticks(), yticks(), xlim(), ylim()
- xticks(), yticks() : x축과 y축의 눈금을 설정하는 코드입니다.
- xlim(), ylim() : x축과 y축의 값을 제한하는 코드입니다.
plt.plot(nvidia_df["High"])
plt.xticks([i*500 for i in range(6)])
plt.yticks([i*10 for i in range(11)])
plt.ylim(5, 80)
plt.show()
legend(), title()
- legend() : 각 그래프의 라벨을 표시해주는 코드입니다. 라벨은 각 그래프를 그리는 코드에 'label'이라는 이름으로 부여할 수 있습니다.
- title() : 그래프의 제목을 설정합니다.
nvidia2022 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2022")]
nvidia2023 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2023")]
nvidia2024 = nvidia_df[nvidia_df['Date'].astype(str).str.contains("2024")]
plt.plot(range(len(nvidia2022)), nvidia2022["High"], label="2022")
plt.plot(range(len(nvidia2023)), nvidia2023["High"], label="2023")
plt.plot(range(len(nvidia2024)), nvidia2024["High"], label="2024")
plt.legend()
plt.title("NVIDIA stock prices (year)")
plt.show()
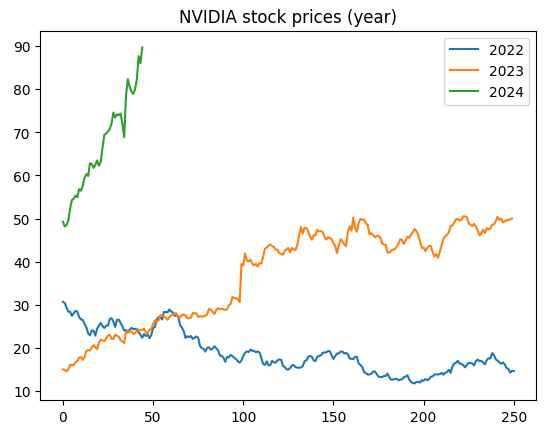
text(x, y, s, ha, fontsize)
그래프에 텍스트를 추가합니다.
- x, y : 텍스트의 x, y축 위치
- s : 표시할 텍스트
- ha : 텍스트 정렬
- fontsize : 텍스트 크기
datas = list(nvidia_df["High"][2000:2010])
plt.plot(datas, '-o')
plt.xticks(range(len(datas)), nvidia_df["Date"][2000:2010], rotation=45)
plt.ylim(20, 32)
for i, data in enumerate(datas):
# i : x축 눈금에 맞춰서
# data+0.6 : y축 눈금보다 조금 크게 하여 그래프와 겹치지 않게 텍스트 표시.
# ha="center", fontsize=10 : 글자를 중앙 정렬하고 크기는 10으로 설정.
plt.text(i, data+0.6, f"{data:.1f}", ha="center", fontsize=10)
plt.show()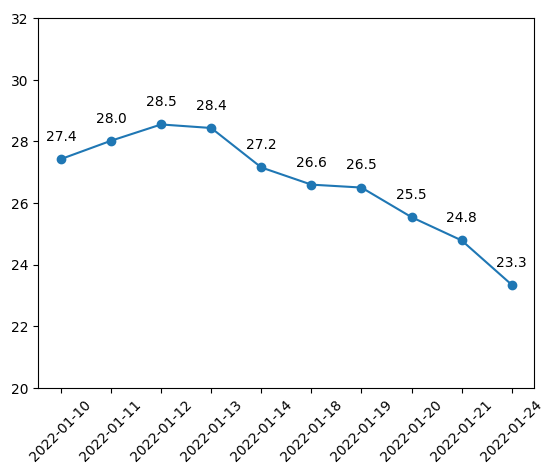
10. 마무리
이렇게 matplotlib의 다양한 그래프 종류와 활용법을 살펴봤습니다. 각 그래프가 어떤 데이터에 적한한지 알아보고, 직접 활용한 코드 에제도 함께 살펴보았는데요. 코드를 외우기보단 제공된 코드를 복사하여, 자신의 데이터에 맞게 편집하여 활용하면 더욱 유용할 것입니다.
이 외에도 matplotlib에서는 다양한 그래프 형태를 지원합니다. 더 다양한 그래프의 유형과 사용법을 확인하고 싶다면 아래 matplotlib 공식 문서에서 확인할 수 있습니다.
https://matplotlib.org/stable/plot_types/index.html
Plot types — Matplotlib 3.10.1 documentation
Plot types Overview of many common plotting commands provided by Matplotlib. See the gallery for more examples and the tutorials page for longer examples. Pairwise data Plots of pairwise \((x, y)\), tabular \((var\_0, \cdots, var\_n)\), and functional \(f(
matplotlib.org