[NLP-6] Masking을 이용한 언어 사전 학습 모델 BERT
1. BERT 학습방식
2. BERT 모델 구조
3. BERT 사전학습 효과
4. BERT 미세조정
5. BERT 학습해보기
1. BERT 학습 방식
BERT 역시 GPT와 마찬가지로 NLP의 대규모 비지도 사전학습 모델의 일종입니다. 그렇기 때문에 BERT의 등장 배경이나 목적은 GPT와 유사합니다.(참고) BERT도 라벨링을 하지 않은 대규모 텍스트를 학습할 방법에 대해서 연구한 방법이죠.
GPT는 문장이 주어졌을 때, 맨 앞의 단어부터 뒤까지 차례대로 예측하는 것을 학습했었죠. BERT는 masking 기법응ㄹ 이용해 텍스트를 학습합니다.
Masking이란 이름 그대로, 텍스트의 일부를 가리는 것을 말합니다. 문장이 주어졌을 때, 그 문장의 일부 단어를 랜덤하게 가린 뒤, 모델에게 해당 부분에 알맞은 단어를 예측하도록 하는 것이죠. 이 방식을 사용함으로써 GPT의 사전학습 방식과 어떤 차이를 갖게 될까요?
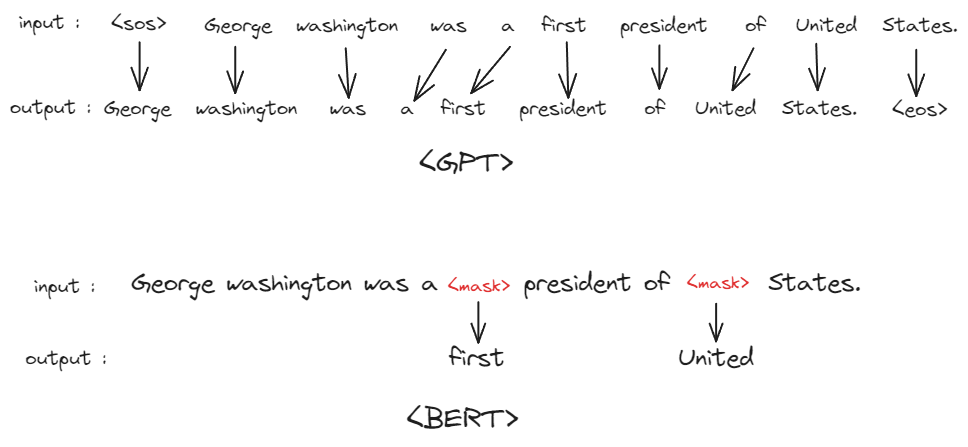
바로 단어를 추측할 때 보는 문장의 범위입니다. GPT의 경우 앞에서부터 차례로 보기 때문에 문장 전체 맥락을 보기 힘들지만, BERT는 문장 전체를 (비록 일부는 가려져 있지만) 볼 수 있기 때문에 전체적인 맥락을 파악하는데 보다 용이하다는 겁니다.
이 사소한 차이는 생각보다 모델 성능에 큰 영향을 미칩니다. 전체 맥락을 볼 수 있냐 없냐의 차이로 인해 텍스트의 맥락 파악이 필요한 텍스트 분류 task 등에서는 동일 스펙일 때, BERT가 GPT보다 더 좋은 성능을 보입니다. 하지만 masking 방식의 학습 방법을 사용하는 이상 텍스트 생성하는 법은 학습하지 못하기 때문에 텍스트 생성에는 GPT 모델을 사용하게 됩니다. 즉, BERT는 텍스트 분류 task에 주로 사용되고 GPT는 텍스트 생성 task에 주로 사용되게 됩니다.
그럼 masking은 어떻게 적용할까요?
우선 주어진 문장에서 15%의 단어를 랜덤으로 선택해 masking 대상으로 선정합니다.
그리고 선정된 15%의 단어들 중, 80%는 <mask>라는 특수 토큰으로 치환하고, 10%는 아예 다른 단어로, 10%는 다른 단어로 바꾸지 않습니다.

전부 다 <mask> 토큰으로 바꾸지 않는 이유는 너무 쉽기 때문입니다. 전부 <mask> 토큰으로 바꾼다면 모델은 <mask> 단어 토큰이 있는 부분에만 집중하면 되겠죠. 그러면 task가 너무 쉬워지고 모델의 성능도 단순해질 겁니다.
하지만 <mask>가 아닌 다른 단어로 바꾼다면 모델은 <mask> 토큰이 없는 부분에도 집중을 해야 하기 때문에 좀 더 어려운 사고를 해야 합니다.
거기에 일부 단어는 바뀌지 않은 경우가 있다면 모델은 이 단어가 바꿔야 하는 단어인지 아닌지도 판단해야 하고 task가 더 어려워지죠. 이렇게 task를 어렵게 만드는 것은 모델의 성능을 고도화하는데 도움을 줍니다.
이런 masking 기법을 이용한 사전학습 방식을 MLM(Masked Language Modeling)이라고 합니다.
BERT는 여기에 하나의 task를 더 수행시킵니다. 바로 NSP(Next Sentence Prediction)라는 task로, 2개의 문장을 이어 붙여 놓고 2개의 문장이 연결되는 문장인지 아닌지를 판별하도록 하는 것입니다.
이 task는 앞의 MLM과 따로 수행되는 것이 아니고, 함께 학습됩니다. 예를 들면 실제로 BERT가 입력 받는 텍스트와 모델의 출력 결과는 아래와 같은 형태를 띱니다.

보면 2개의 문장을 이어 붙인 뒤, 사이에 <SEP> 토큰을 추가해 2개의 문장을 구분합니다. masking은 2개의 문장에 모두 적용되며, 맨 앞에 <CLS> 토큰이 추가됩니다.
모델은 masking된 위치에 적절한 단어를 예측해 넣어야 하며, <CLS> 토큰 위치에는 2개의 문장이 서로 이어지는지 이어지지 않는지를 판단하는 분류 작업을 수행하게 됩니다.
위 문장의 경우, 앞에는 조지 워싱턴에 대한 설명이고 뒷 문장은 뜬금없이 펜케이크 옆에서 일어난다는 문장이 있으니 '두 문장은 이어지지 않는다' 라고 모델이 판별해야겠죠.
사실 MLM과 달리 NSP task에 대해서는 이게 정말 모델 성능에 큰 영향을 주는지 논란이 있긴 합니다만 최초의 BERT가 이런 식으로 설계되었고, 실제 사전학습 모델들도 이를 그대로 사용한 경우가 많기 때문에 일단 설명을 드렸습니다. 특히 여기서 사용되는 [CLS] 토큰의 경우 BERT를 이용한 미세 조정에 자주 사용됩니다.
이렇게 BERT는 2개의 task를 한번에 수행하면서 사전학습됩니다.
2. BERT 모델 구조
BERT의 모델 구조는 GPT와 크게 다르지 않습니다.

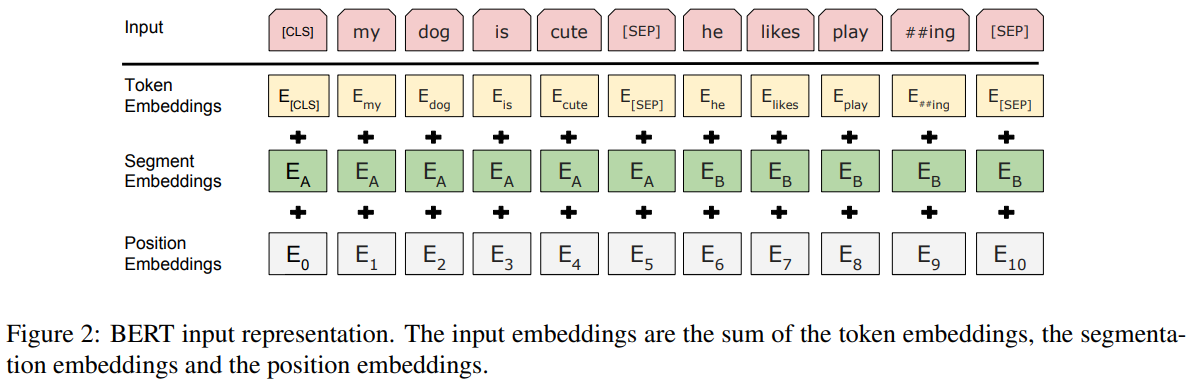
똑같이 임베딩 레이어, N개의 transformer block, 마지막으로 Linear 레이어로 구성되어 있습니다. 마지막 linear 레이어에서의 출력이 조금 다른데, [CLS] 토큰 위치에는 두 문장이 연속되는지 안되는지를 분류하고, masking한 토큰 위치에는 적절한 단어를 출력하게 됩니다.
입력 embedding에도 segment_ids라는게 추가됩니다. segment_ids는 입력된 2개의 문장에 대해 어떤 문장이 앞 문장이고 어떤 문장이 뒷 문장인지 표시하는 역할을 합니다.
3. BERT 사전학습 효과
BERT와 GPT는 모두 텍스트 사전학습 모델로 구조도 같습니다. 두 모델의 차이는 학습 방식에만 있죠. 그렇다면 두 모델의 성능 차이는 어떨까요? BERT 논문에서 다른 모델들과 성능을 비교한 표를 확인해 보도록 하겠습니다.

비교에 사용한 task는 GLUE task들로 문장 관계 분류, 문장 분류 등 분류 task들로 구성되어 있습니다.
위 표에서 "OpenAI GPT"와 "BERT BASE" 2개 모델이 서로 크기가 같은 모델입니다. 보면 같은 모델임에도 불구하고 BERT가 평균적으로 더 높은 점수를 보이는 것을 볼 수 있습니다. 사전학습 방식이 모델 성능의 차이를 야기한다는 것을 확인할 수 있죠.
그리고 BERT LARGE 모델을 보면 BERT BASE보다 성능이 더 향상되는 것을 볼 수 있습니다. 모델의 크기를 키우는 것이 모델 성능 향상에 도움이 된다는 것이죠. 그래서 성능 좋은 언어모델들은 대부분 크기가 굉장히 큽니다...
이것만 보면 무조건 BERT가 GPT보다 좋아보이지만, 앞서 말했듯 GPT는 생성 task에서 강점을 보입니다. BERT로는 챗봇 같은 걸 만들기 어렵죠. 그리고 BERT는 GPT와 달리 zero-shot 성능을 기대할 수 없습니다. GPT 모델은 생성 모델이기 때문에 질문하는 형식으로 모델에 텍스트를 입력하면 다른 task들에 대해서도 답을 내놓을 수 있지만 BERT는 그렇지 못하기 때문이죠.
따라서 BERT 모델은 다른 task들을 수행하기 위해선 미세조정 과정이 필수입니다. 그러면 BERT 모델의 미세조정 과정에 대해 간단히 알아보겠습니다.
4. BERT 미세 조정
BERT 모델을 활용할 수 있는 task는 다양하지만 대부분 분류 task이기 때문에 미세조정 과정은 비슷합니다. 문장의 분류는 모두 [CLS] 토큰에서 이뤄집니다. 텍스트를 BERT 모델에 집어 넣으면 각 단어 토큰 위치마다 feature vector들이 출력되게 될겁니다. 그 중에서 [CLS] 토큰 위치의 feature vector를 이용해 분류 작업을 수행하는 것입니다.

[CLS] 토큰 위치에서 출력된 feature vector에 linear 레이어와 softmax 활성화 함수를 추가로 학습해 task에 필요한 n개의 라벨로 분류하도록 미세조정 과정을 거치면 모델이 완성되는 식입니다. 굉장히 간단하죠?
굳이 [CLS] 토큰을 사용하지 않더라도 feature vector를 출력하는 방법이 더 있습니다.
MeanPooling과 MaxPooling은 BERT가 출력한 각 단어 토큰 위치의 feature vector들의 평균 혹은 최댓값을 feature vector로 활용하는 방법입니다. 이렇게 뽑은 feature vector에 linear 레이어와 softmax 함수를 적용해 학습하더라도 괜찮은 결과가 나옵니다.
[CLS] 토큰과 MeanPooling, MaxPooling 3가지 방법 중 뭐가 제일 좋냐에는 정해진 답은 없습니다. task에 따라 데이터에 따라 결과가 달라지기 때문에 직접 실험해 보고 판단하는 방법이 최고입니다. (그런데 경험 상 MaxPooling은 결과가 좋았던 적이 없던 것 같습니다.) huggingface에서는 [CLS] 토큰을 사용하는 방법을 기본 방식으로 채택하고 있습니다.
만약 2개의 문장을 입력 받아야 하는 task인 경우에도 BERT는 문제없이 처리할 수 있습니다. 애초에 사전학습 과정에서 2개의 문장이 연속되는지를 판별하는 task를 수행했었기 때문에 각 문장을 [SEP] 토큰을 통해 구분하여 입력하기만 하면 그만이기 때문이죠.
예를 들어 2개의 문장의 연관성을 분류하는 NLI task의 경우, 문장1과 문장2를 각각 [SEP] 토큰을 통해 구분하여 모델에 입력한 뒤, [CLS] 토큰의 feature vector를 이용해 '상반됨/관계없음/일치함' 3개의 라벨 중 하나로 구분하면 됩니다.

참고할 본문(passage)과 질문(question)이 주어지고, 본문에서 정답의 위치를 찾아내야 하는 QA task의 경우, passage와 question을 [SEP] 토큰으로 구분하여 모델에 입력한 뒤, [CLS] 토큰에서 질문에 알맞은 답의 위치 인덱스를 출력하게 됩니다.

5. BERT 학습해보기
이번엔 코딩을 통해 직접 BERT 모델을 불러와보고, 사전학습과 미세조정을 수행해 보도록 하겠습니다.
https://colab.research.google.com/drive/1v3csKcsMU--H_8xuFJRNjTuIbmlR_Pay?usp=sharing
BERT.ipynb
Colab notebook
colab.research.google.com
5.1. 데이터 전처리
데이터셋은 아래 github의 챗봇 데이터를 사용합니다.
!git clone https://github.com/songys/Chatbot_data.git데이터는 csv 형식으로 담겨 있습니다.

질문(Q)와 대답(A)으로 구성되어 있으며, label은 대화의 주제를 나타냅니다. (0-일상, 1-이별, 2-사랑)
편의를 위해 이들을 리스트 형태로 따로 저장한 뒤, 훈련셋과 테스트셋으로 먼저 나누겠습니다.
questions = list(csv["Q"])
answers = list(csv["A"])
labels = list(csv["label"])from collections import Counter
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
train_idx, test_idx = train_test_split(range(len(questions)), train_size=0.8)
train_q = [questions[idx] for idx in train_idx]
test_q = [questions[idx] for idx in test_idx]
train_a = [answers[idx] for idx in train_idx]
test_a = [answers[idx] for idx in test_idx]
train_l = [labels[idx] for idx in train_idx]
test_l = [labels[idx] for idx in test_idx]
이를 이용해서 BERT 사전학습과 미세조정을 시행해 보겠습니다.
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")
bert = AutoModelForMaskedLM.from_pretrained("klue/bert-base")모델과 토크나이저는 "klue/bert-base"를 사용할겁니다. 나무위키, 뉴스 등의 텍스트들로 학습한 모델입니다. 표준 한국어 모델 같은 느낌이라 사용하기로 했습니다.
토크나이저를 프린트 해보면 토크나이저 정보를 알 수 있습니다.
BertTokenizerFast(name_or_path='klue/bert-base', vocab_size=32000, model_max_length=512, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
1: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
2: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
3: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
4: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True), }
보면 GPT에 있던 [SOS]나 [EOS] 토큰은 존재하지 않고, [CLS] 토큰과 [SEP], [MASK] 토큰이 추가되어 있는걸 볼 수 있습니다.
5.2. BERT 사전학습 (MLM과 NSP)
BERT 사전학습부터 시작해 보겠습니다. 우선 데이터셋을 만들어 보겠습니다.
questions = list(csv["Q"])
answers = list(csv["A"])
class DatasetForPretraining(Dataset):
def __init__(self, questions, answers, tokenizer):
super().__init__()
self.questions = questions
self.answers = answers
self.tokenizer = tokenizer
def __len__(self):
return len(self.questions)csv의 'Q' 행과 'A' 행을 리스트 형태로 변환해준 뒤, Dataset에 토크나이저와 함께 입력해 줍니다.
__getitem__()을 구현하기 전에 뭐가 필요한지 먼저 생각해 봅시다. BERT의 사전학습은 MLM과 NSP 2개의 task로 이뤄집니다.
MLM을 수행하기 위해선 텍스트의 일부를 masking하는 작업이 필요합니다. masking은 [MASK] 토큰으로 교체하거나 다른 토큰으로 교체하거나 교체하지 않는 작업이 필요합니다. 이는 masking() 함수를 만들어서 여기서 해결할 겁니다.
NSP를 수행하기 위해선 2개의 문장이 필요하고, 이 2개의 문장이 서로 연결되는지 안되는지를 판별해야 합니다. 챗봇 데이터셋에는 각 Q마다 A가 하나씩 할당되어 있으므로 이를 긍정으로, 서로 다른 쌍의 A를 부정으로 분류하면 될겁니다.
def __getitem__(self, idx):
question = self.questions[idx]
prob = random.random()
if prob > 0.5:
answer = self.answers[idx]
label = 1
else:
answer = self.answers[random.randint(0, len(self.answers)-1)]
label = 2
sentence = ("[SEP]").join([question, answer])
inputs = self.tokenizer(
sentence,
padding="max_length",
max_length=90,
truncation=True,
return_tensors="pt"
)
input_ids, label_ids = masking(inputs)
label_ids[0][0] = label
return {
"input_ids": input_ids,
"attention_mask": inputs["attention_mask"],
"label_ids": label_ids,
}random 모듈을 활용해 50%의 확률로 Q에 알맞는 A를 쓰거나 다른 Q의 A를 쓰는 식으로 구현했습니다. 이렇게 선정된 Q와 A는 [SEP] 토큰을 사이에 두고 서로 연결됩니다.
라벨은 서로 맞는 쌍의 Q,A 인 경우 1로, 아닌 경우엔 2로 분류하도록 했습니다. 0과 1을 쓰지 않은 이유는 이따 사용할 crossentropyloss에서 pad 토큰 id는 무시하도록 구현할건데, 여기서 0을 사용하면 pad 토큰으로 취급되어 loss 계산할 때 이 부분이 무시될 수 있기 때문입니다.
이렇게 연결된 문장은 tokenizer를 통해 토큰id로 변경됩니다. Padding을 "max_length"로 설정했기 때문에 [PAD] 토큰을 추가해 최대 길이인 90에 길이를 맞춥니다. 토크나이저로 나온 inputs는 'input_ids'와 'attention_mask'로 구성됩니다.
'input_ids'에는 토큰 id가 담겨 있으며, attention_mask에는 모델이 봐야하는 부분은 1, 무시해야 하는 부분([PAD] 토큰)은 0으로 표시한 mask가 담겨 있습니다.
다음으로 masking 작업이 필요합니다. masking 함수는 다음과 같이 구현했습니다.
def masking(inputs):
length = torch.sum(inputs["attention_mask"])
new_ids = [tokenizer.cls_token_id]
labels = [tokenizer.cls_token_id]
input_ids = inputs["input_ids"].squeeze()
for id_ in input_ids[1:length]:
prob = random.random()
if prob < 0.15:
prob = random.random()
if prob < 0.8:
new_ids.append(tokenizer.mask_token_id)
elif prob < 0.9:
new_ids.append(random.randint(5, 32000))
else:
new_ids.append(int(id_))
labels.append(id_)
else:
new_ids.append(int(id_))
labels.append(0)
new_ids += [0 for _ in range(length, input_ids.size(0))]
labels += [0 for _ in range(length, input_ids.size(0))]
return torch.LongTensor(new_ids).unsqueeze(0), torch.LongTensor(labels).unsqueeze(0)new_ids에는 masking을 적용한 토큰 id를 담을 겁니다.
labels에는 masking을 적용한 위치에 원래 들어가야 하는 단어 토큰 id를 담아 라벨로 사용하려고 합니다.
맨 앞 토큰부터 차례로 보면서 masking을 적용할지 안할지를 결정합니다. random 모듈을 사용해 15%의 확률로 masking을 적용하고, masking을 적용한다면 또 확률을 이용해 [MASK] 토큰을 씌울 지, 다른 토큰으로 교체할지 말지를 결정합니다. 만약 masking이 적용되지 않았다면 labels에는 [PAD] 토큰 id를 추가해 나중에 CrossEntropyLoss를 계산할 때 무시할 수 있도록 합니다.
masking을 마쳤다면 그 뒤에 [PAD] 토큰으로 나머지를 다시 채워준 뒤에 결과를 출력해 줍니다.
데이터를 배치 단위로 구성하기 위한 collate_fn()을 구현해준 뒤에 dataloader까지 만들어 줍니다.
def collate_fn(batch):
batchs = [[], [], []]
for b in batch:
for i, (k, v) in enumerate(b.items()):
batchs[i].append(b[k])
input_ids = torch.cat(batchs[0], dim=0)
attention_masks = torch.cat(batchs[1], dim=0)
label_ids = torch.cat(batchs[2], dim=0)
return {
"input_ids": input_ids,
"attention_mask": attention_masks,
"label_ids": label_ids,
}
train_dataset = DatasetForPretraining(train_q, train_a, tokenizer)
test_dataset = DatasetForPretraining(test_q, test_a, tokenizer)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False, collate_fn=collate_fn)다음으로 학습에 필요한 것들을 설정해 줍니다.
from torch.optim import AdamW
import torch.nn as nn
loss_fn = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_token_id)
optim = AdamW(bert.parameters(), lr=1e-3)
epochs = 3
device = "cuda" if torch.cuda.is_available() else "cpu"CrossEntropyLoss를 사용하는데, [PAD] 토큰이 사용된 부분은 무시하도록 ignore_index를 설정해 줍니다. 이러면 label_ids에 [PAD] 토큰이 담겨 있는 위치의 값들은 무시하고 손실 함수를 계산하게 됩니다. 즉, masking이 적용된 부분의 토큰들의 손실만 계산하게 됩니다.
이제 학습 코드만 작성하면 됩니다.
PyTorch에선 CrossEntropyLoss를 계산할 때 라벨을 one-hot vector(1->[0, 1, 0, 0]과 같은 형식)로 바꿔줄 필요가 없습니다. BERT의 output은 [batch_size, seq_length, n_words] shape를 갖고, 라벨은 [batch_size, seq_length] shape를 갖고 있습니다.
이 둘의 CrossEntropyLoss를 계산하기 위해선 output의 seq_length 축과 n_words 축을 바꿔줘야 합니다. 그래서 .transpose(1, 2) 코드를 이용해 shape를 바꿔준 뒤 loss를 계산하게 됩니다.
from tqdm import tqdm
bert.to(device)
for epoch in range(epochs):
print("epoch :", epoch)
bert.train()
train_losses = 0
for data in tqdm(train_loader):
data = {k: v.to(device) for k, v in data.items()}
preds = bert(data["input_ids"], data["attention_mask"]).logits
loss = loss_fn(preds.transpose(1, 2), data["label_ids"])
optim.zero_grad()
loss.backward()
optim.step()
train_losses += loss.detach().cpu().item()
print("train loss :", train_losses/len(train_loader))
bert.eval()
eval_losses = 0
for data in tqdm(test_loader):
data = {k: v.to(device) for k, v in data.items()}
with torch.no_grad():
preds = bert(data["input_ids"], data["attention_mask"]).logits
loss = loss_fn(preds.transpose(1, 2), data["label_ids"])
eval_losses += loss.cpu().item()
print("test loss :", eval_losses/len(test_loader))5.3. BERT 모델로 분류하기 (미세조정)
미세 조정을 위한 데이터셋을 먼저 구현하겠습니다.
class DatasetforFinetuning(Dataset):
def __init__(self, questions, answers, labels, tokenizer):
super().__init__()
self.sentences = [(" ").join([q, a]) for q, a in zip(questions, answers)]
self.labels = labels
self.tokenizer = tokenizer
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
inputs = self.tokenizer(
self.sentences[idx],
padding="max_length",
max_length=90,
truncation=True,
return_tensors="pt"
)
return {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"labels": self.labels[idx]
}MLM이나 NSP를 위한 준비가 필요 없기 때문에 간단히 질문과 답변을 이어 주면 끝이고, 라벨도 원래 데이터셋의 라벨을 사용하면 됩니다.
def collate_fn(batch):
batchs = [[], [], []]
for b in batch:
for i, (k, v) in enumerate(b.items()):
batchs[i].append(v)
input_ids = torch.cat(batchs[0], dim=0)
attention_mask = torch.cat(batchs[1], dim=0)
return {
"input_ids": input_ids,
"attention_mask": attention_mask.float(),
"labels": torch.LongTensor(batchs[2])
}
train_dataset = DatasetforFinetuning(train_q, train_a, train_l, tokenizer)
test_dataset = DatasetforFinetuning(test_q, test_a, test_l, tokenizer)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False, collate_fn=collate_fn)
다음으로 미세 조정을 위한 모델을 구현할 겁니다.
설명했듯, BERT의 분류 task는 [CLS] 토큰의 output을 사용합니다. 이를 얻기 위해서 BERT output의 0번째 인덱스의 값만 사용합니다.
emb = self.bert.embeddings(input_ids)
feat = self.bert.encoder(emb, attention_mask[:, None, None, :]).last_hidden_state
cls_output = feat[:, 0, :]huggingface의 cls pooler와 똑같이 구현하겠습니다. 여기에 pooler(linear) 레이어와 tanh 활성화 함수를 적용해 pooled_output을 얻습니다.
pooled_output = self.pooler(cls_output)
out = self.tanh(pooled_output)
여기에 마지막으로 classifier(linear)를 적용해 3개의 분류 라벨로 분류하도록 모델을 구현하면 끝입니다.
class bert_for_finetuning(nn.Module):
def __init__(self, bert):
super().__init__()
self.config = bert.config
self.bert = bert.bert
self.pooler = nn.Linear(self.config.hidden_size, self.config.hidden_size)
self.tanh = nn.Tanh()
self.classifier = nn.Linear(self.config.hidden_size, 3)
def forward(self, input_ids, attention_mask):
emb = self.bert.embeddings(input_ids)
feat = self.bert.encoder(emb, attention_mask[:, None, None, :]).last_hidden_state
cls_output = feat[:, 0, :]
pooled_output = self.pooler(cls_output)
out = self.tanh(pooled_output)
out = self.classifier(out)
return out
bert_finetune = bert_for_finetuning(bert)이는 transformers의 AutoModelForSequenceClassifier를 사용한 것과 같습니다.
from transformers import AutoModelForSequenceClassification
bert_finetune = AutoModelForSequenceClassification.from_pretrained("klue/bert-base", num_labels=3)마지막으로 학습을 위한 설정을 하고 학습을 수행하면 됩니다.
loss_fn = nn.CrossEntropyLoss()
optim = AdamW(bert_finetune.parameters(), lr=1e-3)
epochs = 3
device = "cuda" if torch.cuda.is_available() else "cpu"from tqdm import tqdm
bert_finetune.to(device)
for epoch in range(epochs):
print("epoch :", epoch)
bert_finetune.train()
train_losses = 0
for data in tqdm(train_loader):
data = {k: v.to(device) for k, v in data.items()}
preds = bert_finetune(data["input_ids"], data["attention_mask"])
loss = loss_fn(preds, data["labels"])
optim.zero_grad()
loss.backward()
optim.step()
train_losses += loss.detach().cpu().item()
print("train loss :", train_losses/len(train_loader))
bert_finetune.eval()
eval_losses = 0
for data in tqdm(test_loader):
data = {k: v.to(device) for k, v in data.items()}
with torch.no_grad():
preds = bert_finetune(data["input_ids"], data["attention_mask"])
loss = loss_fn(preds, data["labels"])
eval_losses += loss.cpu().item()
print("test loss :", eval_losses/len(test_loader))
코드가 도움이 되셨길 바라며 BERT 마치도록 하겠습니다.