저번 DPR 포스트에 이어서 ODQA 해결책으로 제시된 ORQA와 REALM을 살펴보도록 하겠습니다. 둘을 함께 살펴보는 이유는 둘 다 pre-training을 사용해 ODQA문제를 해결하고자 했고, masking과 연관이 있다는 점에서 비슷하다고 느껴졌기 때문입니다.
0. ODQA
ODQA(Open-Domain-Question-Answering) 문제를 다시 소개하자면, 크게 2가지의 임무를 수행해야 합니다.
- 광범위한 Open-domain corpus로부터 질문과 관련 있는 문서 찾기 (Retrieval)
- 관련 문서들로부터 정답 추출하기 (Reader)
Reader의 경우 BERT를 통해 꽤 좋은 효과를 보고 있습니다. Reader는 BERT를 사용해 문서에서 정답 단어의 위치를 찾는 역할을 수행합니다. 이를 위해서 3개의 linear 레이어를 BERT 레이어 뒤에 추가해 정답 단어의 시작 위치(start), 끝 위치(end), 정답 확신도(score) 3가지를 출력합니다.

Reader는 위와 같은 구조의 모델을 각 문서마다 적용한 뒤, 정답 확신도(score)가 가장 높은 문서의 답을 최종 답으로 사용하게 됩니다.
Reader가 딥러닝을 활용한 명확하고 성능 좋은 방법을 갖고 있는 것과 다르게, retrieval에서는 딥러닝 모델이 힘을 잘 쓰지 못하고 있습니다. 이는 retrieval의 딥러닝 학습이 아래와 같은 어려운 점들을 갖고 있기 때문입니다.
- 학습해야 할 Open evidence corpus의 크기가 매우 크다. (일반적으로 사용되는 위키의 경우 몇백만 개에서 몇천만 개의 위키 페이지를 모델에 학습시켜야 합니다.)
- 어떤 문서가 질문과 연관이 있고 연관이 없는지를 결정하기 어렵습니다. 질문에 대한 명확한 답이 존재하는 reader의 목표와 달리, retrieval는 질문과 관련된 문서를 정의하는 것이 불분명하고 어렵습니다.
그렇기 때문에 retrieval에서 딥러닝 모델을 사용하겠다 할 때 해결해야 할 난제는, "모델을 어떻게 학습시킬 것인가?" 하는 것입니다. ORQA와 REALM은 이에 대한 해결 방식을 제시하고, 기존 가장 성능이 좋던 BM25 알고리즘의 성능을 뛰어넘는 성과를 보였습니다. 이제부터 하나씩 알아보겠습니다.
1. ORQA(Open-Retrieval Question Answering)
ORQA의 핵심 아이디어가 어떤 생각에서 비롯되었는가를 먼저 살펴보겠습니다. Retrieval의 목적은, "질문과 관련 있는 문서를 찾는 것"입니다. "관련 있다"라고 하는 것은, 두 텍스트가 같은 주제에 대해서 이야기하고 있다고 볼 수도 있을 것입니다. 즉, retrieval가 서로 "같은 주제"의 텍스트 쌍을 학습할 수 있다면, 이를 해결할 수 있을지도 모릅니다!
1-1. ICT(Inverse-Cloze-Task) Pre-training
같은 주제의 텍스트 쌍을 학습하기 위한 방법으로 Inverse Cloze Task를 제시합니다. 원래 Cloze Task는 문장에서 가려진 부분을 주변 문맥을 사용해서 예측해 내는 task를 말합니다. (마치 BERT의 MLM과 같습니다) Inverse Cloze Task는 그 반대입니다. 가려진 부분의 텍스트를 이용해 그 주변의 텍스트들을 예측해내는 것이 ICT의 목표입니다.
Retrieval의 입력 문장을 $x$, 찾아야 할 관련 문서를 $z$라고 하겠습니다. ORQA는 하나의 위키 문서에서 임의의 문장을 추출하여 입력 문장 $x$로 사용합니다. 그리고 추출해 낸 문서를 관련 문서 $z$로 간주하는 것입니다. 만약 원문에서 뽑은 문장을 지우지 않는다면, 뽑은 문장 $x$와 문서 $z$에는 완벽히 겹치는 글자들이 생기게 됩니다. 그렇다면 모델이 글자가 겹치는 것에만 집중해서 학습을 하게 됩니다. 그렇기 때문에 기본적으로 문서 $z$에서 문장 $x$를 추출한 뒤 지웁니다. 그러나 전체 중 10%의 문서는 문장 $x$를 지우지 않습니다. 이는 서로 단어가 겹치는 것 역시, 관련 문서를 찾는데 중요한 단서가 되기 때문에 이에 대한 학습도 병행하기 위해서입니다.
x : They are generally slower than horses, but their great stamina helps them outrun predators.
z :
(90%는 문장을 지우고)
Zebras have four gaits: walk, trot, canter and glaoop. When chased, a zebra will ziazag from side to side...
(10%는 문장을 지우지 않는다.)
Zebras have four gaits: walk, trot, canter and glaoop. They are generally slower than horses, but their great stamina helps them outrun predators. When chased, a zebra will ziazag from side to side...
이렇게 구성한 $z$를 $x$의 긍정 문서($z_{positive}$)로 간주합니다. 그리고 문장 $x$가 추출되지 않은 다른 임의의 문서들을 부정 문서($z_{negative}$)로 간주합니다. 모델은 학습을 통해 $z_{positive}$가 $z_{negative}$들보다 입력 문장 $x$와 더 관련 있다 라는 것을 학습하게 됩니다.

그러면 어떻게 $z_{positive}$와 $z_{negative}$를 구분할까요? 여기서 NLP의 천군만마 BERT를 활용합니다. 우선 사전학습이 되어 있는 BERT를 사용해 입력 문장 $x$와 후보 문서들의 집합 $Z\ni{(z_{positive},z_{negative1},...)}$를 인코딩합니다. (각각 $BERT(x)$, $BERT(z)$로 표기하겠습니다.)
그리고 $BERT(x)$와 $BERT(z_{positive})$의 유사도가 $BERT(z_{negative})$와의 유사도보다 더 크면 되는 겁니다. 유사도 측정에는 dot-product가 사용됩니다. (계산이 간단하고, 수백만 개의 문서 벡터를 미리 계산해 둘 수 있다는 이점을 가짐(참고))

즉, $$ BERT(x)\cdot BERT(z_{positive}) < BERT(x)\cdot BERT(z_{negative}) $$ 가 되어야 합니다. CrossEntropyLoss를 사용해 $BERT(x)\cdot BERT(z_{positive})$의 값이 1에 가깝게, 나머지 $BERT(x)\cdot BERT(z_{negative})$의 값들이 0에 가까워지도록 학습합니다. 아래는 대략적인 psuedo code입니다.
passages = [positive, negative, negative, negative, negative]
labels = [1, 0, 0, 0, 0]
linear = nn.Linear(768, 128)
embedded_X = linear(BERT(input_sentence))
embedded_Z = linear(BERT(passages))
similarity = torch.matmul(embedded_X, embedded_Z.T)
loss = F.cross_entropy(similarity, labels)ORQA에서는 두 개의 BERT를 사용해 입력 문장 $x$와 문서 $Z$를 각각 따로 인코딩 합니다. $BERT(Z)$의 연산시간과 자원 절약을 위해, linear 레이어를 추가해 벡터를 768차원에서 128차원으로 축소합니다.
이런 식으로 ICT를 활용하여, retrieval를 라벨이 없는 텍스트로 사전 학습이 가능합니다!
1-2. Fine-tuning
ICT 사전 학습 과정을 마치고 나면, 수행하고자 하는 QA 데이터셋으로 fine-tuning을 진행합니다. Fine-tuning은 ICT로 사전학습된 retrieval와, reader를 함께 end-to-end로 학습합니다.

여기서 관련 문서를 찾고자 하는 open evidence corpus의 양이 매우 크기 때문에, 이들의 벡터를 매 학습 step마다 갱신하는 것은 매우 시간이 오래 걸립니다. ORQA는 ICT 사전학습을 통해 이 대량의 corpus들을 충분히 벡터 공간에 잘 매핑할 수 있다고 간주하고, corpus encoder(BERT_B)의 레이어는 동결한 채로 학습합니다. 질문 인코더(BERT_Q)는 동결하지 않고 다시 학습합니다. 과정은 다음과 같습니다.
- Retrieval를 통해 상위 5개의 질문 관련 문서를 탐색합니다.
- Reader를 이용해 각 문서마다 정답을 찾습니다. (start, end, score)
- 가장 score가 높은 정답을 최종 산출하여 실제 정답과 비교합니다.($L_{full}(q,a)$)
여기서 더 빠른 학습을 위해, loss를 하나 더 추가합니다.
- Retrieval를 통해 상위 5000개의 관련 문서를 탐색합니다.
- Reader를 이용해 각 문서마다 정답이 있을 확률만을 출력합니다. (score만)
- 가장 높은 score의 문서에 정답이 실제로 존재하는지를 확인합니다.($L_{early}(q,a)$)
최종 loss는 아래와 같이 됩니다.
$$ L(q,a)=L_{early}(q,a)+L_{full}(q,a) $$
학습하다 보면 retrieval가 정답이 있는 문서를 찾아오지 못하는 경우가 있을 수도 있습니다. 그렇기 때문에 ICT 사전학습된 retrieval를 이용해 정답 단어를 포함한 문서를 찾아오지 못하는 데이터들은 학습에 사용하지 않았다고 합니다. 이 과정에서 많은 데이터가 버려질 수도 있지만, ICT 사전 학습 덕분에 전체 데이터의 10% 정도만 버려질 수 있었다고 합니다.
1-3. Hyperparameters
Pre-training : 배치 크기가 매우 큽니다...
- batch size : 4096
- training step : 100k
- learning rate : $10^{-4}$
Fine-tuning : fine-tuning은 작은 컴퓨팅 자원(GPU)으로도 수행할 수 있도록 하기 위해(사전 학습의 목적이기도 하고) 작은 배치 크기를 사용했습니다. (12GB 용량의 gpu 하나만으로 fine-tuning을 수행했다고 합니다.)
- batch size : 1
- training step : 2 epochs(larger datasets), 20 epochs(smaller datasets)
- learning rate : $10^{-5}$
2. REALM
REALM은 ORQA의 후속 논문으로, ICT가 아닌 다른 방식의 pre-training 방식을 제시합니다. REALM은 BERT의 MLM 학습 방식이 매우 성공적이라는 것에 집중했습니다. 그래서 이 MLM training을 사전 학습 방식에 포함하고자 했습니다. REALM 사전학습은 MLM을 수행하되, MLM에 도움이 될 만한 관련 문서를 찾는 방식으로 수행됩니다.
The [MASK] at the top of the pyramid.
예를 들면, MLM은 위 문장에서 [MASK] 위치에 올바른 단어를 찾아야 합니다. 여기서 [MASK] 위치에 적합한 단어를 찾기 위해 retrieval는 위 문장과 관련된 아래와 같은 문서를 찾아와야 합니다.
The pyramid on top allows for less material higher end up pyramid.
그러면 모델은 관련 문서를 참고하여 [MASK]에 적합한 단어를 더 수월하게 찾을 수 있을 것입니다. 그리고 이 과정을 통해, 입력 문장과 관련된 문서를 찾는 능력도 함께 기를 수 있게 됩니다.
MLM은 knowledge-augmented encoder(Reader)가 수행합니다. 즉, ORQA와 다르게 pre-training 과정에서 retrieval와 reader를 함께 학습합니다. Retrieval를 통해 관련 문서를 탐색하고, top-k개의 관련 문서를 참고하여 reader는 [MASK]에 적합한 단어를 출력합니다. 그 중 가장 probability가 높은 단어를 최종 output으로 선정하여 학습을 진행합니다.

REALM의 ORQA와의 차이점은, ICT 대신 MLM을 사용한다는 점과, pre-training 과정에서 Reader도 같이 사전학습된다는 점입니다. 그 외의 구조는 ORQA와 거의 동일합니다.
ORQA에서는 하나의 배치에 입력 문장 $x$의 $z_{positive}$와 다수의 $z_{negative}$들로 구성하여 학습을 했습니다. 그러나 REALM에서는 전체 $Z$를 이용해 학습을 합니다. 그러나 전체 $Z$를 학습에 사용하려면, 매 학습 step마다 몇백만 개의 $z$들의 임베딩 벡터가 재계산되어야 하는데 이는 시간이 매우 오래 걸립니다.
다행히 벡터의 유사도를 비교하는데 inner product(내적) 연산을 사용하고 있고, 이 연산은 문서들의 벡터가 사전에 계산되어 있어도 전혀 상관이 없습니다. MIPS(Maximum Inner Product Search)는 내적 연산을 이용한 벡터 간의 유사도 탐색을 효율적으로 할 수 있는 알고리즘입니다. REALM에서는 MIPS를 활용해 입력 문장 $x$와 관련 있는 상위 k개의 $z$를 빠르게 탐색합니다.
그러나 MIPS를 활용하려면 모든 문서의 벡터가 사전 계산이 되어 있어야 합니다.(BERT로 임베딩하는 과정을 미리 거쳐놔야 합니다.) 그렇기 때문에 매 훈련 step마다 이 벡터 값들을 갱신하지 않고, 500 step마다 갱신합니다. 문서집합 $Z$는 500step동안 갱신되지 않고 이전에 연산되었던 벡터를 그대로 사용해 학습에 사용되는 겁니다. 물론 매 step마다 갱신하는 것이 더 좋겠지만 현실적으로 너무 오래 걸리기 때문에 어느 정도 타협을 본 것입니다. 또 끊임 없는 학습을 위해 수백만개의 문서 벡터를 계산하는 과정은 학습과 동시에 병렬적으로 이루어집니다.
Fine-tuning 과정에선 ORQA와 동일하게 문서 인코더(BERT_B)는 학습하지 않고 동결하여 위와 같은 번거러운 과정을 거치지 않습니다.
이번에는 REALM의 디테일들을 알아보겠습니다.
2-1. Salient span masking
REALM은 마스킹 단어 선정도 좀 더 고심해서 선택했습니다. 마스킹 대상은 주로 고유명사나 날짜 위주로 했습니다. 아무 단어를 고르는 것보다 좀 더 그 내용을 나타내는 단어들이기도 하고, QA 데이터셋의 질문의 답의 유형이 주로 고유명사나 날짜이기 때문입니다. 즉, QA task에서 더 중요한 단어를 masking함으로써 모델의 성능 향상을 꾀한 것입니다. Salient span masking 방식은 결과적으로 최종적으로 랜덤 마스킹보다 6점의 더 높은 EM 점수를 받게 해주었습니다.
2-2. Null document
어떤 질문들은 굳이 다른 문서를 참고하지 않더라도 대답할 수 있는 간단한 질문도 존재합니다. 이럴 때는 모델이 굳이 다른 문서를 함께 볼 필요가 없기 때문에 이런 경우에 대비해서 상위 k개의 문서에 'null document(빈 문서)'를 추가합니다.
예를 들면, 3+5는 무엇인가? 에 대한 질문을 답변하는데 관련 문서를 찾을 필요는 없습니다. 이런 경우 retrieval의 결과는 아래와 같습니다.
"[CLS]3+5는 무엇인가?[SEP][SEP]"
2-3. Prohibiting trivial retrievals
MLM을 수행할 문장은 위키 문서들에서 추출됩니다. 그렇기 때문에 retrieval의 결과가 MLM을 수행하고자 하는 문장이 포함된 문서를 가져올 수도 있습니다. 이럴 경우, 모델이 그 문서의 문장을 그대로 베끼는 방식으로 학습할 수 있고, 이는 모델이 단어의 유사성에 심각하게 의존하게 되는 문제가 발생합니다. 그렇기 때문에 pre-training 과정에서 이런 문서들은 제외하고 학습을 했다고 합니다.
2-4. Initialization
REALM은 MLM과 retrieval를 함께 pre-training하지만, retrieval만의 목적 함수가 따로 존재하지 않습니다. (MLM을 수행하는 과정에서 자연스럽게 함께 학습되는 것이죠.) 그러나 그렇기 때문에 retrieval 모델의 파라미터 초기화가 제대로 이루어지지 못한다면 학습 초기에 retrieval는 입력 문장과 관련 없는 문서들만 찾아올 것이고, reader는 올바른 정답을 맞추기 위해 retrieval의 탐색 결과를 무시하는 방식으로 학습될 수 있습니다.
그렇기 때문에 ORQA의 ICT pre-training 방식을 사용해 retrieval를 어느 정도 사전학습을 한 뒤에 REALM pre-training을 수행함으로써, retrieval가 어느정도 관련 문서를 찾아오도록 유도한다고 합니다.
2-5. Hyperparameters
Pre-training : ORQA보다 배치 크기가 많이 작아졌습니다.
- batch size : 512
- training step : 200k
- learning rate : 3e-5
Fine-tuning : BERT 논문과의 비교를 위해 똑같은 파라미터를 사용했다고 합니다.
- batch size : 48
- training step : 2epochs
- learning rate : 48
3. 결과
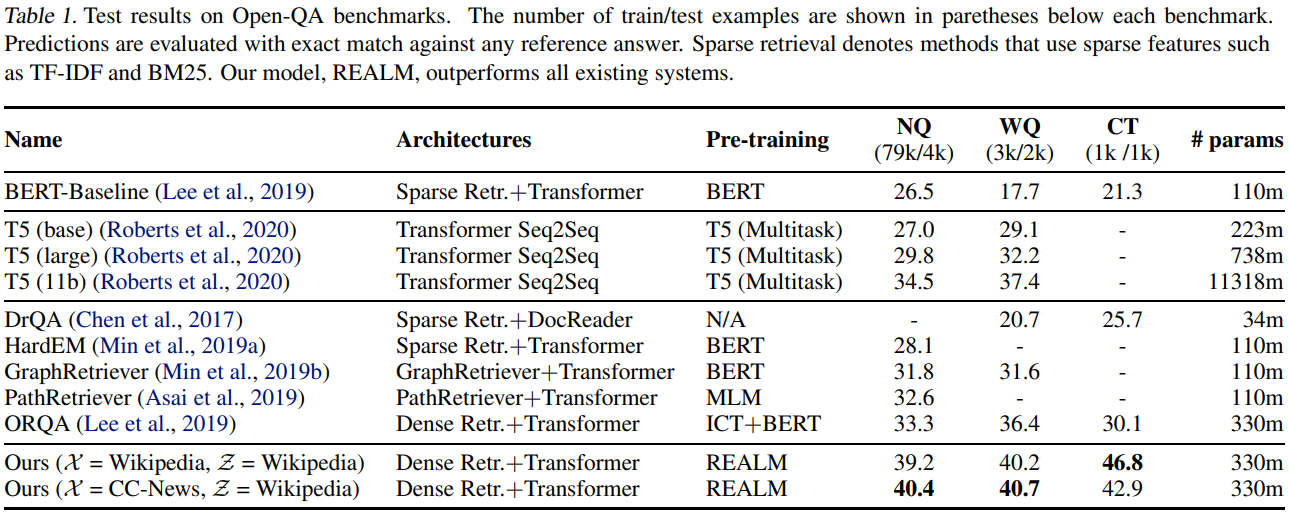
결과는 위와 같습니다. REALM이 SOTA를 달성했습니다. ORQA와 REALM은 같은 데이터와 모델로 학습되었습니다. 둘의 차이점은 사전 학습 방식에만 있습니다. (ICT vs. REALM) 즉, 사전학습 방식의 개선만으로도 위 결과와 같은 점수 차이를 낸 것입니다. 학습 방식이 얼마나 중요한 지를 알 수 있는 대목입니다.
REALM의 retrieval가 reader의 MLM 학습에 실제로 도움을 주고 있는가도 확인해 보았습니다.

4. 정리
이렇게 ORQA와 REALM에 대해서 알아보았습니다. DPR과 같은 ODQA task를 수행하지만, 결은 많이 다른 것 같습니다. DPR은 학습이 간단하고 성능이 더 좋지만, ODQA 데이터셋을 직접 활용해야 합니다. REALM, ORQA는 성능이 조금 떨어지지만, 대규모의 라벨이 없는 텍스트로 사전 학습이 가능하다는 장점을 갖습니다. 특히 ORQA와 REALM은 ODQA task에 맞춰서 새로운 사전 학습 방식을 제시한 것도 인상적이었습니다. ORQA와 REALM 리뷰를 통해 사전 학습 방식에 대한 더 확장된 시각을 가질 수 있었습니다.
ORQA : https://arxiv.org/pdf/1906.00300.pdf
REALM : https://arxiv.org/pdf/2002.08909.pdf



