1. 배경 소개
NLP에는 2개의 시퀀스를 서로 비교하고 분석해야하는 종류의 task가 있습니다. 예를 들면 NLI나 ODQA와 같은 task가 있겠습니다. NLI는 두 문장의 관계를 '관계 있음', '관계 없음', '상반됨' 3가지로 분류하는 task이고, QA는 질문이 주어졌을 때, 질문에 대한 답을 추론하는데 도움이 될만한 관련 문서를 찾고, 그 문서로부터 질문에 대한 답을 추출해야 하는 task입니다.
<NLI>
"사형제도는 폐지되어야 합니다." - "사형제도를 지지하는 것은 옳지 않습니다."
분류 : '관계 있음'
<QA>
관련 문서
1. "63빌딩 혹은 63 스퀘어는 대한민국 서울특별시 영등포구 여의도동에 있는 마천루이다. 이전 명칭은 한화 63시티이고 지상높이는 249m(해발 264m)이다."
2. "인종은 제 12대 국왕이다. 성은 이, 휘는 호, 아명은 억명이다. 본관은 전주, 자는 천윤이며 묘호는 인종, 시호는 영정헌문의무장숙흠효대황이다."
질문 : "63빌딩의 이전 명칭은 무엇인가?"
답 : "한화 63시티"
이런 task를 해결하는데 역시 BERT 구조를 활용한 모델들이 SOTA를 달성하고 있습니다. BERT를 활용해 이런 task를 해결하는 방식은 2가지로 나눌 수 있습니다.
1-1. Cross-Encoder
Cross-Encoder는 BERT논문에서 제시된 방식으로, 두 개의 시퀀스를 하나의 인코더에 한번에 입력으로 제공하는 것입니다. 이 방법을 택할 경우 인코더는 두 시퀀스의 정보를 어텐션 구조를 이용해 자연스럽게 하나의 정보로 융합해낼 수 있게 됩니다.

1-2. Bi-Encoder
Bi-Encoder는 두 개의 인코더를 활용해 두 개의 시퀀스를 각각 처리합니다. 그 뒤에 두 인코더가 처리한 feature의 유사도를 활용하여 두 시퀀스의 관계를 분석합니다. 유사도는 cosine similarity나 dot-product와 같은 연산을 통해 계산됩니다.

이 방식의 경우 성능은 Cross-Encoder 방식보다 살짝 떨어지지만 연산이 빠르다는 장점이 있습니다. 두 개의 시퀀스를 각각 처리하는 방식이기 때문에 각 시퀀스들의 임베딩 벡터를 미리 계산해 놓을 수 있기 때문입니다.
즉, Cross-Encoder와 Bi-Encoder 방식은 서로 각자의 장단을 갖는 방식이라고 볼 수 있습니다. 이렇게 장단점이 확실한 두 종류의 모델이 있으면 이 둘의 장점을 합치고 싶어하는 사람들이 생기겠죠? 그래서 나타난 연구가 poly-encoder입니다. Poly-Encoder의 목적은 Cross-Encoder의 두 개의 시퀀스 사이의 attention 연산으로 인한 성능 상의 이점을 살리면서, 벡터를 미리 계산해 둘 수 있다는 Bi-Encoder의 이점도 살리는 것입니다.
2. Poly-Encoder
2-1. Task
Poly-Encoder의 구조에 대해 알아보기 전에 poly-encoder의 실험 대상 task들에 대해 알아보겠습니다. 본 논문에서는 "ConvAI2", "DSTC7", "Ubuntu V2", "Wikipedia Article Search" 총 4가지의 task에 대해서 실험을 진행합니다.
- ConvAI2 : 특정 사람의 성격에 대한 문장이 몇 개 주어집니다. 대화문이 주어졌을 때, 이를 참고하여 해당 인물의 답변으로 적절한 텍스트를 생성해내야 합니다.
- DSTC7, Ubuntu V2 : 우분투의 대화로그 데이터셋으로, 우분투 관련된 기술적 문제에 대한 대화를 참고하여 해결책을 제시해야 하는 task입니다.
- Wikipedia Article Search : 특정 문장이 주어졌을 때, 해당 문장이 어떤 article의 문장인지를 찾는 task입니다.
4가지 모두 여러 개의 시퀀스 가운데 입력 시퀀스와 관련 있는 시퀀스를 찾아야 하는 task입니다. 앞에 개요에서는 NLI와 같은 task도 예시로 들었지만, bi-encoder의 이점은 이와 같이 여러 개의 시퀀스 중에 가장 관련 있는 시퀀스를 찾아내야 하는 task에서 드러나기 때문에 이와 같은 task로 실험을 진행했고, 모델 소개에 앞서 설명하고자 했습니다.
이하의 설명에선 논문을 따라 여러 개의 시퀀스(wiki article)는 context, 입력 문장(검색하고자 하는 문장)은 candidate라고 표현하겠습니다.
2-2. Methods
Poly-Encoder는 어떻게 두 개의 시퀀스를 처리하는지 알아보도록 하겠습니다. 우선 Poly-Encoder 역시 Bi-Encoder와 같이 두 개의 BERT 인코더를 사용합니다. 이를 통해 각 시퀀스는 $y_{cand_i}$와 $y_{ctxt}$로 임베딩 됩니다.(여기까진 Bi-Encoder와 같습니다.) 그러나 일반적으로 context가 candidate 보다 길이가 더 깁니다. 그렇기 때문에 poly-encoder는 이를 하나의 벡터가 아닌 m개의 벡터로 나타냅니다. ($y^1_{ctxt},...,y^m_{ctxt}$) m은 하이퍼파라미터로 어떻게 조정하냐에 따라서 추론 시간에 영향을 미치게 됩니다. context로부터 m개의 임베딩 벡터를 얻기 위해 m개의 context code를 함께 학습합니다.
$$ y^i_{ctxt}=\Sigma_j w^{c_i}_j h_j $$
where $(w^{c_i}_1,...,w^{c_i}_N)=softmax(c_i\cdot h_1,...,c_i\cdot h_N)$
그리고 최종적으로 이 m개의 feature들은 $y_{cand_i}$와의 attention 연산을 통해 두 시퀀스 사이의 유사도를 측정하게 됩니다.

사실 논문의 이 설명만으로는 실제로 어떻게 구현했다는건지 이해하기 어려웠습니다. 특히 context code라는 부분이 전혀 이해가 가지 않았는데요, 이럴 땐 구현 코드를 참고하면 좋습니다. 전 star가 가장 많은 polyencoder 구현 repo를 참고했습니다.
https://github.com/sfzhou5678/PolyEncoder
GitHub - sfzhou5678/PolyEncoder: An unofficial implementation of Poly-encoder (Poly-encoders: Transformer Architectures and Pre-
An unofficial implementation of Poly-encoder (Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring) - GitHub - sfzhou5678/PolyEncoder: A...
github.com
이 repo의 encoder.py에서 BertPolyDssmModel 클래스를 보면 구조를 대략 알 수 있습니다. 코드가 길기 때문에 간단하게 psuedo 코드처럼 직접 정리해서 보여드리겠습니다. (제 나름대로 논문 내용과 제 생각을 참고해서 각색해서 작성합니다.)
class BertPolyDssmModel(BertPreTrainedModel):
def __init__(self, config, *inputs, **kwargs):
super().__init__(config, *inputs, **kwargs)
self.bert = kwargs['bert']
self.vec_dim = 64
# 하이퍼 파라미터 m입니다.
self.poly_m = 8
self.poly_code_embeddings = nn.Embedding(self.poly_m + 1, config.hidden_size)
def forward(self, ctxt_inputs, cand_inputs):
# context 인코딩 과정입니다.
ctxt = self.bert(**ctxt_inputs).logits # [batch_size, hidden_size]
# 아래와 같이 code context(poly_codes)는 position embedding과 같이 1부터 m까지의 숫자를
# 임베딩 레이어를 이용해 인코딩하는 방식으로 계산된다는 것을 알 수 있습니다.
poly_code_ids = torch.arange(self.poly_m, dtype=torch.long)
poly_code_ids = poly_code_ids.unsqueeze(0).expand(batch_size, self.poly_m)
# poly_code_ids = ([[0, 1, ... m-1], ...], dtype=torch.LongTensor, size=[batch, m])
poly_codes = self.poly_code_embeddings(poly_code_ids)
# 이 m개의 임베딩 벡터는 context vector와의 attention 연산을 통해 결과에 반영됩니다.
context_vecs = dot_attention(query=poly_codes, key=ctxt, value=ctxt)
# candidate 인코딩 과정입니다.
candidate_vec = self.bert(**cand_inputs).logits # [batch_size, hidden_size]
# context vector에 candidate vector를 attention을 통해 값을 반영합니다.
context_vecs = dot_attention(query=candidate_vec, key=context_vecs, value=context_vecs)
# 최종적으로 context vector와 candidate vecotr의 dot-product를 통해 결과를 출력합니다.
# 학습은 batch 단위로 들어오기 때문에 두 벡터의 행렬곱을 통해 batch 단위의 dot-product
# 를 한번에 수행할 수 있습니다.
output = torch.matmul(candidate_vec, context_vecs.T())
return output위 코드를 보면 context code라는 것은 1부터 m까지의 숫자를 임베딩 레이어를 통해 인코딩하여 attention 연산으로 context vector와 함께 계산하는 식으로 구현됩니다. 이는 BERT의 position embedding과 같이 생각하면 될 것 같습니다. BERT에서 입력 시퀀스의 순서 정보를 모델에 주입하기 위해서 앞에서부터 [0, 1, 2, ..., ] 이런 식으로 position_ids를 입력으로 제공하고 이를 임베딩 레이어를 통해 계산하듯이, context code 역시 단순히 [0, 1, 2, ...m] 숫자를 임베딩하는 것이지만 이를 통해 m개의 임베딩 블럭과 context vector 사이의 attention 연산을 통해 정보를 8개로 나눠서 생각하게 만드는 역할을 한다고 직관적으로 생각해 볼 수 있을 것 같습니다.

Poly-encoder는 이런 구조를 사용함으로써 다음과 같은 이점을 얻을 수 있습니다.
- 2개의 BERT 인코더를 활용하기 때문에 Context와 Candidate의 벡터를 미리 계산할 수 있습니다.
- 미리 계산된 벡터끼리 attention 연산을 사용하기 때문에 Cross-Encoder 방식보다 빠르면서도, fully-attention 연산 방식의 이점을 가질 수 있습니다. 물론 이 attention 연산 때문에 bi-Encoder 방식보다는 느리게 됩니다.
3. 실험 결과
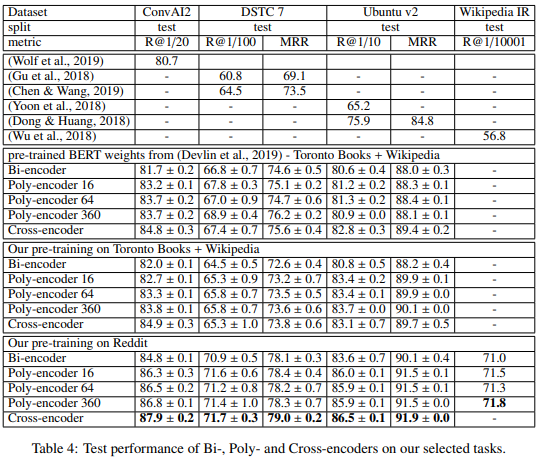
Bi-encoder, Cross-encoder, Poly-encoder m의 성능을 먼저 비교해 보겠습니다. 결과는 위 표와 같으며 대부분 Bi-encoder < Poly-encoder < Cross-encoder 순으로 나타났습니다.
논문에서는 Pre-training에 사용된 데이터셋에 따른 결과도 분석하고 있습니다. Toronto Books+Wikipedia로 학습된 모델보다 Reddit의 텍스트로 학습된 모델의 성능이 더 좋은 것을 확인할 수 있는데 이는 Reddit의 텍스트가 fine-tuning에 사용된 task의 텍스트들과 유사하게 구어체로 구성되어 있기 때문인 것으로 보입니다.

추론 시간의 경우 위 표와 같이 나타났습니다. 보면 Cross-Encoder의 추론시간이 압도적으로 오래 걸리는 것을 확인할 수 있습니다. 반면 Poly-encoder는 Bi-encoder보다 느리긴 하지만 큰 차이는 보이지 않았고, m이 커질수록 추론 시간이 오래 걸리는 것을 확인할 수 있습니다. 성능 표에서도 m이 커진다해서 성능이 크게 향상되지 않는 것을 보면 m은 작게 설정하는게 좋을 것 같습니다.
4. 결론
이렇게 간단하게 poly-encoder에 대해서 알아봤습니다. 미리 계산된 벡터에 attention을 적용하는 방식으로 cross-encoder와 bi-encoder의 장점을 모두 취하는 간단한 아이디어지만 충분히 볼만한 논문이었던 것 같습니다. 개인적으로는 context code와 같은 임베딩 방법에 대해서도 다시 공부할 수 있는 계기가 되었던 논문이었습니다.



