안녕하세요. 이번에 데이콘의 VQA 대회에 참가해보게 되었었습니다. 텍스트로 된 QA 문제는 해결해 본 적이 있지만 이미지를 함께 활용하는 VQA는 처음이라 여러가지 자료 조사를 하는데 대부분의 시간을 쓰게 되었습니다... 저처럼 VQA를 처음 접하는데 어디서부터 찾아봐야 할지 잘 모르겠는 분들께 제가 조사했던 자료들이 길을 찾는데 도움이 되길 바라면서, 제가 조사한 여러가지 논문들의 내용을 간략하게 정리해 보고자 합니다.
1. VQA는 어떤 task일까?
2. VQA를 처리하기 위한 다양한 모델 구조
2-1. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
2-2. Unifying Vision-and-Language Tasks via Text Generation (VL-T5)
2-3. GIT: A Generative Image-to-text Transformer for Vision and Language
2-4. BLIP : Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
2-5. Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
3. 질문에 답하기 위해 필요한 추가 정보 활용하기
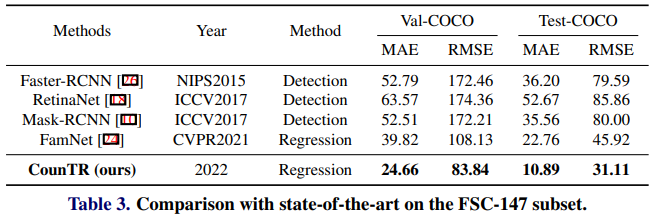
3-1. CounTR: Transformer-based Generalised Visual Counting
3-2. TAP: Text-Aware Pre-training for Text-VQA and Text-caption
4. 마무리
1. VQA는 어떤 task일까?
VQA는 Visual Question Answering의 약자로, 이미지와 관련된 질문에 대해 대답해야 하는 문제입니다. 이미지와 질문 텍스트가 주어졌을 때, 그에 알맞은 답변 텍스트를 생성하는 것이 VQA의 목표입니다.

VQA를 해결하기 위한 모델 구조는 어떻게 하면 좋을까요? 막연히 생각했을 때 이미지를 처리할 모듈과 텍스트를 처리할 모듈이 필요할 것 같고, 답변 텍스트를 생성하기 위한 모듈도 하나 필요할 것 같습니다. 그렇다면 각 모듈은 어떤 구조의 모델을 활용하는 것이 좋을까요?
데이터 측면에서 접근해 보면 어떤 정보가 VQA에 도움이 될까요? VQA에 사용되는 이미지에는 어떤 유형이 있고, VQA의 질문에는 어떤 유형이 있을까요? 이런 유형들마다 추가적으로 필요한 정보가 있을까요?
하나씩 차근차근 살펴 보도록 하겠습니다.
2. VQA를 처리하기 위한 다양한 모델 구조.
2-1. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering (논문 링크)
우선 적절한 모델구조부터 생각해 보겠습니다. 일반적으로 이미지를 처리하는 방법은 ImageNet으로 사전학습된 CNN 모델을 불러와 전이학습을 수행하는 것입니다.

ImageNet 데이터는 천만장의 이미지와 각 이미지에 알맞는 분류 클래스로 라벨링되어 있습니다. 직관적으로 보면 사전학습 과정은 CNN 모델이 이미지 전체를 어떤 식으로 해석해야 하는지를 배우는 것이라고 볼 수 있습니다.

이런 능력은 이미지 해석이 필요한 VQA에서도 유효할 겁니다. 왜냐하면 이미지 분류는 사실상 VQA에서 "이 사진의 물체는 무엇인가요?"와 같은 질문에 대답하는 것을 학습한 것과 같다고 볼 수 있기 때문이죠. 하지만 VQA에는 다른 유형의 질문들도 많습니다. 예를 들면, 같은 이미지라도 "이 사진의 물체는 무엇인가요?", "이 물체의 색은 무엇인가요?", "이 사진에 자동차는 몇 대가 있나요?"와 같이 다양한 질문이 가능하고, 질문에 따라서 이미지에서 해석해내야 할 정보들도 다를 겁니다.

즉, 이미지 전체를 해석하는 능력도 필요하지만, 이미지 내의 중요한 물체들의 정보에 대한 정보가 더 중요할 수 있습니다.
그래서 생각한 것이, ImageNet으로 사전학습된 모델보다 '이미지에서 중요 물체들의 위치를 찾는 것을 학습한 모델을 활용한다면 VQA에서 더 좋은 성능을 낼 수 있지 않을까?' 하는 것입니다. 즉, 'Object Detection을 이용해 사전학습한 모델을 사용하면 더 좋지 않을까?' 라는 생각을 하게 된거죠.
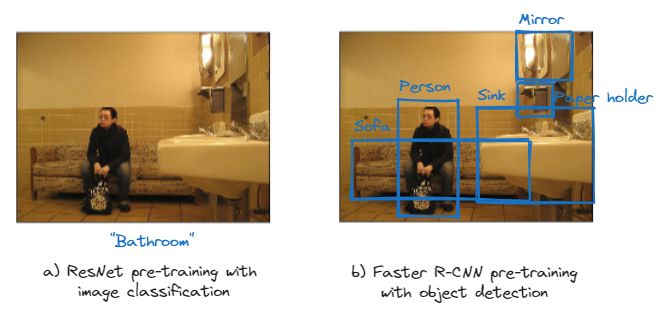
Object detection의 대표적인 사전학습 모델로 Faster R-CNN이 있습니다. 본 논문에선 이 Faster R-CNN을 이용해 물체의 중요 부분들의 정보만을 추린다면 성능을 더 높일 수 있을 것이라고 생각합니다. 논문에서 말하는 Bottom-up attention이란, 이 Faster-RCNN을 활용해 이미지의 주요 물체(object)의 정보를 찾는 것을 말합니다.
텍스트는 Glove 벡터와 LSTM 레이어를 이용해 처리했습니다. Glove 벡터는 다수의 문장들을 이용해 언어들을 벡터 공간에 매핑 시킨 것을 말합니다. 사전학습에서 사용되는 수많은 문장들로부터, 각 문장에서 자주 등장하는 단어의 빈도 수를 토대로 학습한 벡터를 사용하는 것입니다.
일반적으로 이렇게 사전학습된 Glove 벡터를 이용해 텍스트를 전처리하는 것이 더 좋은 성능을 보이고, 여기서도 그대로 사용합니다. 본 논문에서 Top-down attention이라고 부르는 것은 Glove+LSTM 레이어를 이용해 텍스트에서 중요한 정보를 추리는 과정을 말합니다.

핵심은 Bottom-up 모델로 ResNet이 아닌 Faster R-CNN을 사용하는 것입니다. 이 뒤의 논문들에서도 Bottom-up attention이라고 부르는 것은 모두 이 Faster R-CNN을 활용하는 것을 말합니다.
아래 결과를 보면 Faster R-CNN을 사용하는 것이 ResNet을 사용하는 것보다 VQA에서 더 좋은 점수를 받을 수 있다는 것을 알 수 있습니다.

성능 변화를 보면 ResNet을 사용했을 때보다 Faster R-CNN을 사용했을 때(Up-Down) 성능이 4~7%가량 향상되는 것을 확인할 수 있습니다. 특히, 물체의 개수를 물어보는 Number 문제에서 성능이 크게 향상된 것을 확인할 수 있습니다. 이미지에서 물체들의 위치를 특정하는 것이 개수를 세는데 도움을 가장 크게 줬지 않을까 싶습니다.
2-2. Unifying Vision-and-Language Tasks via Text Generation (VL-T5) (논문 링크)
한동안 텍스트를 처리할 땐 LSTM 레이어가 정석적으로 사용되었지만, Attention 레이어로 구성된 Transformer의 등장으로 NLP 분야는 완전히 새로운 시대를 맞이했습니다. Transformer를 시작으로 BERT, GPT, BART, T5 등등의 모델들이 줄줄이 SOTA를 달성하며, '텍스트 처리 = Transformer'가 정석적으로 굳어졌습니다. 그런만큼 VQA에서도 텍스트 처리에 transformer 구조를 사용하지 않을 이유가 없겠죠.
VL-T5는 이중에서도 T5의 특징을 이미지-텍스트 multimodal 영역에서도 활용하고자 제시된 모델입니다. 이전가지의 딥러닝 모델들은 하나의 모델을 사전학습한 뒤에, 각 task에 맞춰서 새로운 linear layer를 추가하는 식으로 모델 구조를 변형하여 fine-tuning 하는 방식으로 사용되었습니다.

그러나 VL-T5에서는 간편하게 다양한 task들을 하나의 모델만으로 처리하고자 합니다. 마치 ChatGPT처럼 모든 task(Image captioning, VQA 등)를 질문과 답변 형식으로 처리하고자 하는 것이 VL-T5의 주요 골자입니다.

위 예시와 같이 하나의 이미지에 대해서 질문을 다르게 함으로써(Input text 앞의 "span prediction:", "vqa:" 등의 prompt를 학습 시키는 것) 원하는 task의 답을 얻을 수 있게 됩니다.
이런 방식의 장점은 앞서 말했듯 다양한 task를 하나의 모델만으로도 처리가 가능할 뿐만 아니라, 더 다양한 task의 더 많은 데이터를 함께 학습시키면서 모델 성능의 고도화를 꾀할 수도 있다는 것입니다.

모델 구조는 위와 같습니다. T5 모델의 경우 더이상 Glove 벡터를 사용하지 않고 텍스트를 토큰화("Man = 132", "Tree = 2438"과 같이 단어들을 숫자로 바꾸는 작업)한 뒤, 임베딩 레이어를 함께 학습하여 처리합니다. VL-T5는 여기에 이미지 임베딩 레이어를 추가합니다. 이미지가 마치 일종의 텍스트 토큰인것 마냥 취급하는 겁니다.
이미지 임베딩은 Faster R-CNN을 이용해 구성합니다. Faster R-CNN을 이용해 주요 물체들의 feature map(ROI features), RoI 좌표(Box coordinates), Image ids(여러 장의 이미지가 입력될 경우 서로 다른 이미지에서 나온 RoI임을 구분하기 위함), Region ids(각 RoI들을 구분하기 위함) 총 4가지 요소를 추출한 뒤, 각각을 임베딩합니다.
이 이후의 구조는 텍스트를 처리하는 T5 모델과 동일합니다. 이미지와 텍스트 임베딩 값은 attention 모듈로 구성된 multimodal encoder를 통해 인코딩되며, Text Decoder는 이 인코더 정보를 활용해 정답을 생성하는 역할을 합니다. 이를 통해 T5 모델과 유사한 구조를 갖지만 이미지와 텍스트를 함께 처리할 수 있게 됩니다.
2-3. GIT: A Generative Image-to-text Transformer for Vision and Language (논문 링크)
지금까지 VQA에서는 이미지 처리를 위해 Faster R-CNN을 사용하였습니다. 그러나 Faster R-CNN을 활용하는 방식은 사전학습된 Faster R-CNN을 이용해 RoI feature를 미리 추출하고 이를 그대로 사용하는 방식인데, 이렇게 하면 이미지를 처리하는 이미지 인코더가 텍스트 인코더와 함께 학습되지 않기 때문에 이미지와 텍스트 사이의 관계를 모델이 학습하기에 어려운 한계를 갖게 됩니다.

이를 해결하기 위해선 이미지 인코더도 학습 가능한 모듈로 구성하는 것이 좋을 겁니다. 마침 NLP 분야에서 Transformer가 크게 성공하자 비전 분야에서도 이 Transformer 구조를 도입하기 위한 연구가 진행되었고, Vision Transformer(ViT)가 등장하게 되었습니다. ViT의 특징은, 데이터가 많아질수록 ResNet과 같은 CNN 기반의 모델에 비해 그 성능이 훨씬 크게 증가한다는 것입니다. 이를 통해 비전 분야에서 SoTA를 달성하게 되었고, 비전 영역에서도 transformer 구조가 크게 활용되기 시작했습니다.
GIT 역시도 이미지 인코더로 ViT와 같은 구조를 가진 Florence 모델을 사용합니다. 다만 Florence는 ViT와 학습 방식이 다릅니다. 이미지 분류 학습을 수행하는 ViT와 달리, Florence는 이미지-텍스트 쌍을 이용한 contrastive learning을 통해 사전학습됩니다. Contrastive learning이란 서로 유사한 것들은 서로 유사한 벡터값을, 서로 다른 것들은 서로 다른 벡터값을 갖도록 하는 학습법을 말합니다.
Florence는 이미지와 텍스트를 각각 벡터화 한 뒤, 적절한 이미지의 설명 텍스트와는 서로 유사한 벡터값을, 그렇지 않은 텍스트와는 서로 다른 벡터값을 갖도록 학습합니다.

GIT은 이미지 인코더로 사전학습된 Florence와 텍스트 디코더로 사전학습되지 않은 Transformer 구조의 GPT 모델을 이용합니다. 즉, GIT은 이미지-텍스트 쌍 처리 모듈로 Florence를 사전학습하여 사용하고, 정답 텍스트를 생성하기 위한 모델로 GPT 구조를 사용하는 것입니다. 다만 여기서 GPT를 사전학습된 모델을 사용하지 않고 새로 학습하는 이유는, 사전학습 모델이 주는 이점이 전혀 없었기 때문입니다. (GPT 사전학습에 사용되지 않았던 새로운 이미지 토큰이 input으로 사용된다는 차이점이 GPT의 사전학습이 힘을 못 쓰게 하는 것으로 보입니다.)

GIT의 사전학습은 위 그림과 같이 이뤄집니다. 앞서 본 VL-T5와 같이 사전학습된 Image Encoder를 사용해 이미지 토큰 임베딩을 생성하고, 텍스트 토큰 임베딩과 concat됩니다. 이를 바탕으로 Text Deocder(GPT)는 질문에 알맞은 정답 텍스트를 생성하게 됩니다.
앞선 VL-T5와 유사하지만, VL-T5는 사전학습된 Faster R-CNN을 이용해 고정된 임베딩 벡터를 사용했지만, GIT은 사전학습된 Florence로 학습 가능한 벡터를 사용한다는 큰 차이점이 존재합니다.

이 차이 하나만으로도, 기존 VQA v2.0의 test-std데이터셋에서 70.3%의 정확도를 달성했던 VL-T5에 비해 GIT은 78.81%의 정확도를 달성, 무려 8%의 정확도가 향상된 것을 확인할 수 있습니다.
2-4. BLIP : Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (논문 링크)
BLIP은 Image-Text 쌍을 이용한 사전학습 모델 중에서 자주 언급되는 편인것 같아 간단하게 살펴봤습니다.

앞서 본 GIT보다 더 복잡해 보이지만, GIT은 텍스트와 이미지를 하나의 인코더에서 함께 처리하고, BLIP은 이미지와 텍스트를 서로 다른 인코더에서 처리한다 정도의 차이입니다. 또한 BLIP은 GIT과 다르게 학습에 사용되는 object도 3가지나 존재합니다.
BLIP의 3가지 object는 ITC, ITM, LM 3가지로 다음과 같습니다.
- ITC(Image-Text Contrastive loss) : 사전학습된 Text Encoder (BERT)와 Image Encoder (ViT)가 생성한 feature를 비교하여 서로 관련 있는 feature끼리 유사한 벡터를 갖도록 하는 Image Encoder 학습 loss.
- ITM(Image-Text Matching loss) : Image-Text 쌍이 서로 관련 있을 경우 Positive, 아닐 경우 Negative로 이진 분류를 수행하는 Image-grounded Text encoder 학습 loss.
- LM(Language Modeling loss) : Image-grounded Text decoder가 생성한 텍스트가 라벨 텍스트와 일치하는지를 비교하는 loss.
복잡한 것에 비해서 VQA v2.0의 test-std데이터셋에서 정확도는 78.32%로 GIT보다는 0.5% 정도 살짝 아쉬운 모습을 보이기는 했습니다.
2-5. Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks (BEIT-3)
BEIT 역시 SoTA 모델로 텍스트-이미지 쌍 학습에 자주 사용되는 모델이어서 간단히 조사해 봤습니다.

BEIT-3의 전략은 모든 이미지와 텍스트를 하나의 모델과 하나의 object만으로 함께 pretraining하는 것입니다. 이 하나의 object는 BERT에서 사용되는 masking 방식이 사용됩니다. Masking 방식은 input의 일부를 가린 뒤에, 가려진 부분을 모델로 하여금 예측하도록 하는 학습 방식입니다.

BEIT-3의 경우, 이미지와 텍스트를 하나의 인코더로 함께 학습합니다. 그렇기 때문에 이미지-텍스트 쌍을 필요로 하는 downstream task는 물론, 이미지나 텍스트만을 필요로 하는 downstream task에도 적용이 가능하다는 장점을 가집니다. 또한 Masking 방식 하나만으로 학습하기 때문에 데이터가 늘어나던 모델의 크기가 증가하던 상관없이 쉽게 훈련 가능하다는 장점도 존재합니다.
BEIT-3의 학습은 1500만개의 이미지와 2100만개의 이미지-텍스트 쌍을 이용해 이뤄졌으며, 파라미터의 수도 총 19억개로 굉장히 많습니다. 이미지와 텍스트를 하나의 모듈로 처리할 수 있는 원동력은 거대한 데이터와 모델 크기에서 온다고 볼 수도 있을 것 같습니다. 그렇기 때문에 SOTA 모델이지만 일반 컴퓨터에서는 이 모델을 활용하기가 조금 어렵습니다. 저도 활용은 못하고 쳐다보기만 했네요. (3니까 BEIT-2라도 이용해보자 했지만 BEIT-2는 이미지 모델이었습니다.)

이전의 SOTA 모델과 비교했을 때 성능 차이가 비교적 확연하게 나타나며, 앞서 보았던 BLIP이나 GIT과 비교해도 BEIT-3의 정확도가 4% 가량 더 높은 것을 확인할 수 있습니다.
3. 질문에 답하기 위해 필요한 추가 정보 활용하기
지금까지는 모델 구조를 중점적으로 살펴봤습니다. 좋은 backbone 모델을 선택하는 것도 중요하지만, '성능 향상을 위해서 모델에 어떤 정보를 추가로 제공할 수 있을까?'를 고민하는 것도 필요한 부분입니다. 아래의 예시들을 보고 더 다양한 방식들을 고민해 볼 수 있으면 좋을 것 같습니다.
3-1. CounTR: Transformer-based Generalised Visual Counting (논문 링크)
이미지에 있는 물체의 개수를 물어보는 질문에 잘 대답하기 위해선 어떤 정보가 필요할까요?

위 사진에서 딸기의 개수가 몇 개인지를 물어봤다고 합시다. 그런데 인공지능 입장에선 딸기가 뭔지를 알 수가 있을까요? 너무 당연하게도, 딸기의 개수를 세려면 딸기가 무엇인지부터 알아야 합니다. 보통 사람이라면 당연히 딸기가 뭔지 알겠지만, 인공지능한테는 당연하지 않을 수 있습니다.
CounTR은 모델에게 어떤 물체의 개수를 세야하는 지를 알려주기 위해, 찾고자 하는 물체의 사진을 추가 input으로 모델에 제공합니다.

모델 구조는 위와 같습니다. 질문의 대상인 Query Image와, 개수를 세고자 하는 대상의 사진 example들을 input으로 받아, 최종적으로 물체들의 위치를 점으로 찍는 Density Map을 최종 결과로 출력합니다. 결과적으로 density map을 보고 물체의 개수가 몇 개인지를 셀 수 있게 됩니다.
CounTR 모델에는 텍스트가 input으로 주어지지 않습니다. 하지만 갯수를 묻는 질문이라는 것이 파악된다면 CounTR 모델을 활용하는 방식으로 VQA에서도 충분히 활용할 수도 있습니다. 예를 들어, 질문에 "How many"라는 글자가 존재한다면 갯수 문제로 간주하고, 이런 경우엔 CounTR 모델을 활용하도록 프로그램을 짤 수도 있을 것입니다.
3-2. TAP: Text-Aware Pre-training for Text-VQA and Text-caption (논문 링크)

위 질문에 대답하기 위해선 전광판에 쓰여 있는 글자들을 읽을 수 있어야 합니다. 우선 가장 가운데에 있는 "Coors LIGHT"를 읽을 수 있어야 그 왼쪽에 있는 로고가 무엇인지 알 수 있으며, 그 로고에 적힌 "SAFEWAY"라는 글자까지 읽어야 제대로 된 정답을 낼 수 있기 때문입니다.
이렇게 사진에 있는 글자를 읽는 task를 OCR(Optical Charactor Recognition)이라고 합니다. 그러나 모든 VQA 데이터셋의 이미지에 글자가 존재하는 것은 아니기 때문에 VQA 데이터셋만으로 이런 부분까지 학습하기는 어려울 수 있습니다. 그렇기 때문에 OCR 데이터셋을 기반으로 학습한 모델의 도움을 받는 것도 좋을 수 있습니다.

TAP은 이런 OCR을 필요로 하는 문제들을 해결하기 위해 설계된 모델입니다. 모델의 input부터 기존의 모델들과는 다르게, object detector와 OCR model의 도움을 받습니다. Object detector를 이용해 사진에서 중요 object들의 위치와 종류를 찾으며(obj), OCR model을 이용해 사진에 존재하는 글자와 글자 위치(ocr)를 찾아 input에 활용합니다.
TAP의 input 역시 이미지와 텍스트로 구성됩니다. 텍스트는 '질문 쿼리'+'object detector가 찾은 주요 물체들의 이름($w^{obj}$)'+'OCR 모델이 찾은 글자($w^{ocr}$)'로 이뤄지며, 이미지는 'object detector가 찾은 주요 물체 이미지($v^{obj}$)'와 'ocr model이 찾은 글자 이미지'로 구성됩니다.
텍스트와 이미지는 각각 임베딩 레이어를 통해 벡터화되어 Multi-modal transformer layer를 통해 함께 처리됩니다. TAP은 3가지 object로 학습됩니다.
- MLM(Masked Language Modeling) : 텍스트 학습에는 masking이 사용되었습니다.
- ITM(Image-Text Matcing) : 캡션이 이미지에 적절한지를 판별합니다. 이를 위해 학습 데이터의 50%는 이미지와 맞지 않는 캡션을 무작위로 선정하여 모델 학습에 사용합니다.
- RPP(Relative Position Prediction) : 주요 물체와 사진의 글자들의 위치를 갖고 서로의 상대적인 위치를 예측합니다. 위치는 on, cover, overlap, 8-ways, orientation, unrelated 총 13개로 분류합니다.
TAP의 효능을 검증하기 위해 TAP을 적용하지 않은 모델부터 TAP의 요소를 하나하나 추가하면서 성능을 측정해 보았습니다.

위와 같이 TAP의 object를 하나씩 추가할 때마다 정확도가 조금씩 증가하며, 최종적으로 TAP의 모든 object를 적용한 모델과 적용하지 않은 모델 사이엔 5% 정도의 정확도 차이가 발생하게 됩니다.
이런 식으로 다른 모델을 이용해서 VQA 모델의 성능을 높이는 식으로도 활용이 가능합니다.
4. 마무리
이렇게 VQA와 관련된 딥러닝 연구들에 대해서 대략적으로 알아봤습니다. 모델 구조를 봤을 때, 이전에는 Faster R-CNN과 같은 object detector의 도움을 받는 방식을 주로 활용했으나, 최근에는 Transformer 구조를 이용해 이미지와 텍스트를 함께 학습하는 모델들이 SOTA로 활용되고 있습니다.
또한 물체의 개수를 세는 문제에는 찾고자 하는 물체의 예시 사진을 추가로 입력하거나, 사진의 텍스트를 읽기 위해 OCR 모델의 힘을 빌리는 등의 방식들도 고려해보면 하나의 모델만이 아닌 여러 개의 모델을 활용해 VQA에 대한 성능을 더 높여볼 수도 있을 것 같습니다.
이 외에도 다양한 모델과 방법들이 존재할 거고, VQA에 있어서 정말 중요한 논문인데 제가 정리하지 않은 것도 있을 것입니다. (그래서 A to Z가 아니라 A to X) 다만 저 역시도 VQA에 대해서 처음 조사하는 입장이었기에 이번 포스팅은 처음 VQA를 접하는 분들께 도움이 되었으면 좋겠고, 기회가 되면 BEIT나 ViT 같은 논문들은 다시 자세하게 리뷰를 해보도록 하겠습니다. 감사합니다.
'딥러닝 논문리뷰' 카테고리의 다른 글
| FASTSPEECH 2: FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH (1) | 2023.10.29 |
|---|---|
| (Tacotron2) NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS (1) | 2023.10.23 |
| 사전 학습 모델에 대한 공격 - RIPPLe (0) | 2023.07.09 |
| Meena : SSA 평가지표를 제시한 사람 같은 챗봇 (0) | 2023.07.04 |
| Learning Transferable Visual Models From Natural Language Supervision (0) | 2023.06.08 |



