이제 TTS를 이용한 서비스는 이제 우리에게 꽤나 친숙한것 같습니다. TTS는 어떤 구조의 모델을 사용하고 어떤 데이터를 사용하는지에 대해서 알아보겠습니다. 이번에 알아볼 TTS 모델은 'Tacotron2' 입니다.
1. Introduction
Tacotron 이전에 등장한 모델 중 가장 좋은 TTS 모델은 WaveNet이었습니다. 하지만 WaveNet은 학습을 위해 음성파일로부터 음소의 길이, 주요 주파수 추출 등 전문적인 지식을 요구하는 요소들을 추출해야 합니다. 그렇기 때문에 모델을 학습하기 어렵죠. 반면에 Tacotron2는 음성 정보를 mel-spectrogram 형태로 입력하면 됩니다. Mel-spectrogram은 만드는데 전문적인 지식이 요구되지 않기 때문에 일반 딥러닝 연구자들도 쉽게 만들 수 있습니다.
TTS 같은 경우에는 모델의 성능을 평가하는데 MOS라는 지표를 사용합니다. MOS는 실제 음성과 모델이 합성한 음성을 일반 사람들이 직접 듣고 뭐가 더 진짜 같은지를 직접 평가하는 점수입니다. 아무래도 결과물이 소리다 보니 정확도와 같은 지표들을 적용하기 힘든 부분이 있어서 모델 평가가 힘든 부분이 있습니다. Tacotron2에서 실험한 결과 실제 음성은 4.58점, 모델 합성 음성은 4.53점으로 실제 음성과 차이가 거의 없을 정도로 좋은 퀄리티를 냈다는 것을 보여주고 있습니다.
2. Model Architecture
TTS는 대략 다음과 같은 과정을 거칩니다.

텍스트를 입력 받아 스펙트로그램을 생성한 뒤, Vocoder를 이용해 스펙트로그램을 다시 원래 음성 파형으로 복원하는 식으로 진행됩니다. Tacotron2는 텍스트를 스펙트로그램으로 변환하는 역할을 합니다.
2-1. Audio Preprocessing
음성 전처리는 STFT를 사용했으며, frame size = 50(ms), frame hop size = 12.5(ms), Hann Window를 사용했습니다.
그리고 이를 mel-spectrogram으로 변환할 땐 80 channel mel filterbank를 사용했으며, 125Hz~7.6kHz 범위로 조절했습니다.
import librsoa
audio, sr = librosa.load("example.wav")
stft = librosa.stft(
audio,
n_fft=int(sr*0.05),
hop_length=int(sr*0.0125),
window='hann'
)
D = np.abs(stft)**2
S = librosa.feature.melspectrogram(
S=D,
sr=sr,
n_mels=80,
fmin=125,
fmax=7600
)
S = np.log10(S)
plt.imshow(S)2-2. Spectrogram Prediction Network
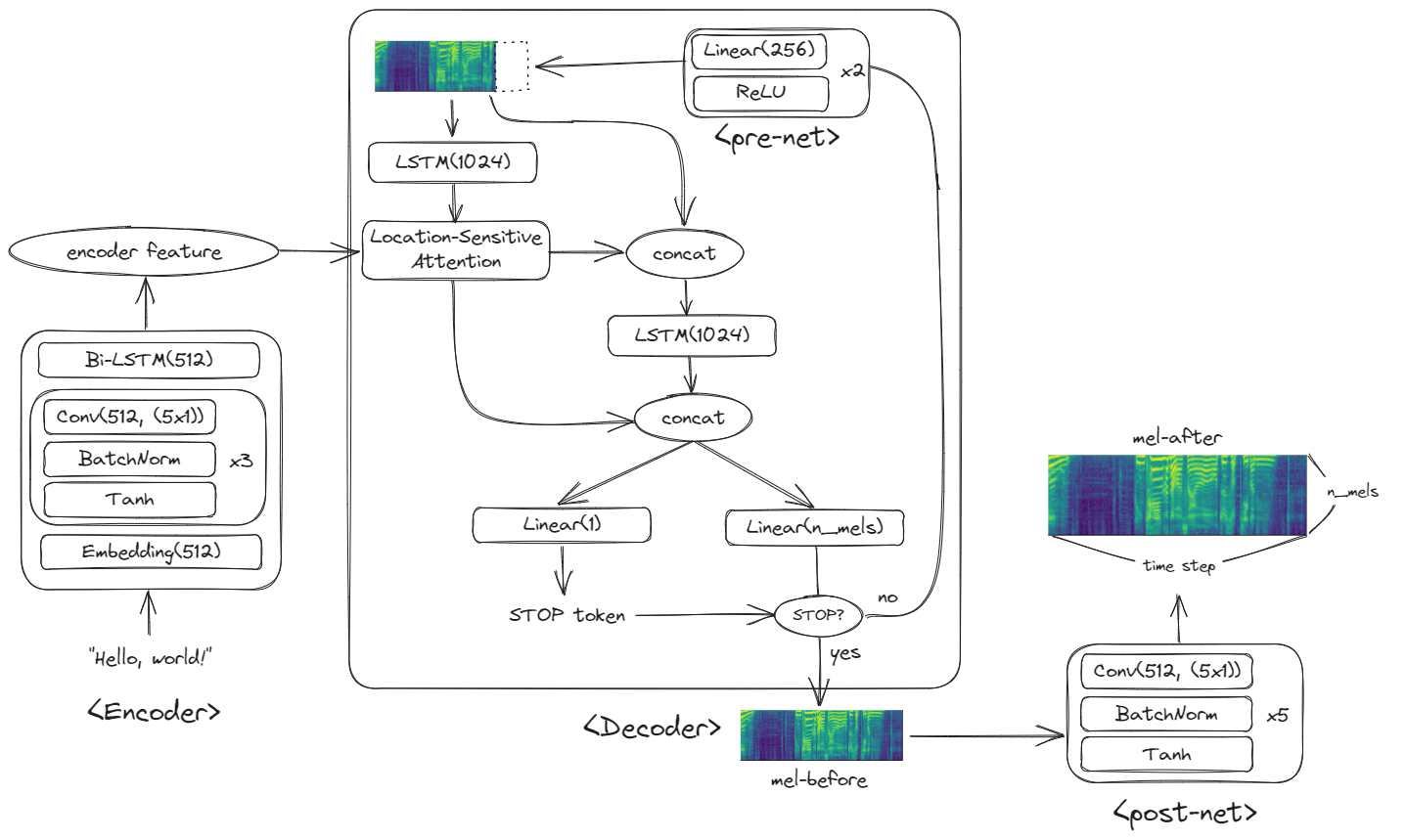
2-2-1. Encoder
인코더의 input은 텍스트입니다. 텍스트는 임베딩 레이어를 통해 벡터화되며, Convolution layer를 거칩니다. (5x1)크기의 커널을 사용한다는 것은 하나의 필터당 5글자씩 보는 것과 같은 의미를 가집니다. 그 뒤에 양방향 LSTM을 거쳐 텍스트 정보를 담은 feature representation을 결과물로 출력하게 됩니다. 이 feature representation은 (시퀀스 길이, 512) 크기를 갖습니다.
2-2-2. Location Aware Attention
디코더는 스펙트로그램을 생성하는 역할을 합니다. TTS는 텍스트에서 음성을 만들어내는 시스템인만큼 스펙트로그램을 생성하는데 텍스트 정보가 필요할 것입니다. Tacotron2는 인코더가 추출한 텍스트 정보를 스펙트로그램 생성에 활용하기 위해 Location Sensitive Attention 메커니즘을 사용합니다.
Location Sensitive Attention은 (인코더의 feature representation, 이전 timestep의 디코더 output, 이전 timestep까지의 attention weights) 3가지를 입력 받습니다. Location Senstive Attention의 역할은 이번 timestep에서 만들어야 할 스펙트로그램이 인코더 feature representation의 어느 부분을 참고해야 할지를 결정하는 것이라고 볼 수 있습니다.

만약 위 그림과 같이 "Hello, world!"가 입력되었고, 디코더가 만든 스펙트로그램이 "Hello,"까지 만들었다면, Location Sensitive Attention은 이를 보고 '다음 스펙트로그램은 'W'에 해당하는 음성을 만들어야겠구나' 라고 학습하게 되는 것입니다. 즉, attention의 역할은 디코더가 텍스트에 맞게 스펙트로그램을 잘 만들고 있는지 관리감독하는 역할이라고 볼 수 있습니다.

2-2-3. Decoder
디코더는 스펙트로그램을 만드는 역할을 합니다. 스펙트로그램은 한번에 그리는 것이 아니라, 시간 순으로 한줄씩 차례대로 생성합니다. 즉, 스펙트로그램이 모두 생성될 때까지 디코더가 반복적으로 작동하는 것입니다.
다시 Attention 부터 살펴보겠습니다. 인코더의 feature와 이전 timestep에서 생성한 디코더의 결과(만약 첫번째 시퀀스라면 0, prev_seq라고 표현하겠습니다.)와 이전 attention 기록(없다면 0, attention_weights라고 표현하겠습니다.)을 보고 결과물(context라고 표현하겠습니다.)과 새로운 attention_weights를 출력하게 됩니다.

이 context는 prev_seq와 다시 결합(concatenate)된 뒤에 LSTM 레이어를 거쳐 rnn_feature를 생성합니다. 이 rnn_feature는 다시 context와 결합한 뒤에 2개의 linear layer에 활용되게 됩니다.

하나는 mel-spectrogram을 생성하기 위한 linear layer입니다. Linear layer를 통해 mel-spectrogram의 채널 수를 맞추는 겁니다. 이렇게 출력된 것을 seq라고 하겠습니다.
또 하나는 stop token을 예측하기 위한 linear layer입니다. Sigmoid 활성화 함수를 이용해 결과값이 0.5가 넘는다면 디코더의 생성을 멈추고, 그렇지 않다면 다시 다음 step의 스펙트로그램을 생성하게 됩니다.

만약 stop token이 0.5이하라면 seq는 pre-net을 거치게 됩니다. 256차원의 Linear 함수 2개로 이뤄진 pre-net은 seq를 처리한 뒤 다시 attention에 prev-seq로써 입력을 제공하게 됩니다.

위의 과정들이 stop token이 stop이 될 때까지 계속 반복되게 됩니다. 만약 stop으로 판정되어 스펙트로그램이 완성된다면 마지막으로 post-net을 통해 스펙트로그램의 품질을 보완합니다.
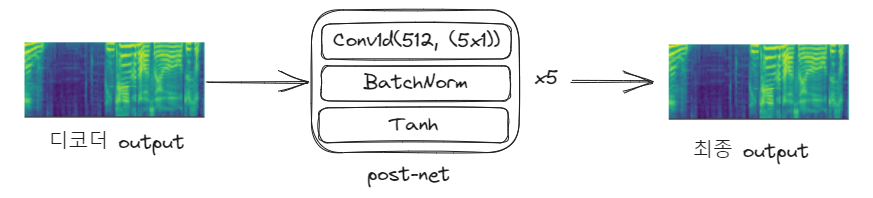
이렇게 post-net까지 거친 스펙트로그램 결과가 최종 Tacotron2의 결과물이 됩니다.
과정이 복잡하게 느껴질 수 있습니다. 그럴 때 코드를 함께 본다면 도움이 많이 됩니다. 아래 링크에서 구현 코드를 확인할 수 있습니다.
https://github.com/NVIDIA/tacotron2/blob/master/model.py
3. Experiments & results
3-1. Training Setup
Tacotron2의 훈련은 teacher-forcing을 사용합니다. 앞서 본 모델구조에 따르면 tacotron2가 생성한 이전 time-step의 스펙트로그램을 보고 다음 time-step의 스펙트로그램을 생성하는 식으로 작동됩니다. 하지만 모델의 학습이 덜 되었다면 스펙트로그램을 제대로 그려낼 수 없겠죠. 그러면 다음 time-step의 스펙트로그램을 그릴 때도 제대로 그려지지 않은 이상한 모양의 이전 time-step 스펙트로그램을 보고 그리게 될 것입니다. 그러면 학습이 제대로 되지 않겠죠. 그렇기 때문에 학습 과정에서는 모델이 예측한 스펙트로그램이 아니라 실제 음성의 스펙트로그램을 보고 다음 time-step의 스펙트로그램을 그릴 수 있도록 하는 teacher-forcing을 사용합니다.
batch_size = 64
optimizer = Adam($\beta_1=0.9,\beta_2=0.999,\epsilon=10^{-6}$)
learning_rate = $10^{-3}$(~50,000step), 그 후에 $10^{-5}$까지 서서히 감소.
L2 regularization(weight=$10^{-6}$)
학습 데이터는 US English dataset을 사용했습니다. 이 데이터셋에는 전문 여자 성우의 24.6시간 분량의 음성 데이터가 포함되어 있습니다. 이 데이터셋에 있는 영어 외의 문자(숫자 등)들은 모두 발음에 맞춰 영어로 변경되었습니다. (16->"sixteen")
3-2. Evaluation & Ablation Studies
Inference에는 teacher-forcing을 사용하지 않습니다. (못 사용합니다.)
평가를 위해 테스트셋에서 100개의 문장을 랜덤으로 선택해서 사람들에게 평가를 부탁했습니다. 점수는 1점부터 5점까지 0.5점 간격으로 부여할 수 있습니다. 그 결과 4.53 MOS 점수를 얻을 수 있었습니다.
합성이 잘 되지 않은 문장들을 분석한 결과, 6개의 문장은 잘못 발음되었으며, 1개의 문장은 스킵된 단어가 존재했고, 23개의 문장에는 부자연스럽게 특정 단어를 강조하거나 부자연스러운 소리를 낸 것으로 확인되었습니다. 또 테스트셋중 가장 긴 길이의 문장에는 모델이 문장을 끝낼 위치를 제대로 찾지 못한 경우가 있었다고 합니다.
또한 평가단들에게 tacotron2의 결과에 대한 소감을 물어봤을 때, tacotron2가 자연스럽게 음성을 만들어내기는 하지만 사람 이름 등 특정 발음들을 어려워하는 것 같다고 했습니다.
또 다른 실험으로 mel-spectrogram을 쓴 것과 linear spectrogram을 쓴 것을 비교해봤는데, 둘 사이에 큰 성능 차이가 없었다고 합니다. 하지만 mel-spectrogram이 linear spectrogram보다 크기가 더 작기 때문에 더 효율적인 선택이 될 것 같다고 했습니다.
스펙트로그램을 한번 더 개선하는 post-net의 효능에 대해서도 실험해 본 결과, 사용했을 때와 사용하지 않았을 때의 MOS 차이가 0.1점 가량 나는 것을 확인할 수 있었다고 합니다.
4. 마무리
이렇게 tacotron2에 대해 알아봤습니다. Tacotron2는 스펙트로그램을 음성으로 변환시켜주는 보코더로 waveNet의 보코더를 사용했다고 하는데, 여기서는 다루지 않았습니다. 이에 대해서는 나중에 보코더 관련한 논문을 따로 다루도록 하겠습니다.
'딥러닝 논문리뷰' 카테고리의 다른 글
| 구글의 BARD와 openAI의 ChatGPT는 어떻게 다를까? (1) | 2023.12.20 |
|---|---|
| FASTSPEECH 2: FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH (1) | 2023.10.29 |
| VQA의 A to X (1) | 2023.09.25 |
| 사전 학습 모델에 대한 공격 - RIPPLe (0) | 2023.07.09 |
| Meena : SSA 평가지표를 제시한 사람 같은 챗봇 (0) | 2023.07.04 |



