요즘 좀 나간다 하는 기업들은 모두 대규모 언어 모델을 만드는 것에 혈안이 되어 있습니다. 오늘은 그 선두주자인 chatGPT와 가장 큰 기업 구글의 BARD는 어떤 차이가 있을까? 하는 것에 대해서 알아보겠습니다.
우선 차이를 알아보기 위해 chatGPT와 BARD 당사자들에게 서로의 차이를 물어봤습니다.


ChatGPT는 BARD가 openAI의 인공지능이라고 하네요. ChatGPT에 학습된 데이터가 BARD가 등장하기 이전의 텍스트들로 학습되었기 때문에 BARD에 모르기 때문에 그런 것 같습니다. (유료버전은 어떨지 모르겠네요.)
반면에 BARD는 ChatGPT에 대해서 잘 알고 있는 것 같습니다. 큰 차이점으로 '훈련 데이터', '목적', '가격' 3가지를 들었네요. 지금부터 BARD와 ChatGPT에 대해서 알아보면서 맞는지 확인해 보도록 하겠습니다.
1. 논문 소개
2. 훈련 데이터셋
3. 모델 구조
3.1. Bard
3.2. ChatGPT
4. 학습 방식
4.1. Bard
4.1.1. Quality & Safety fine-tuning
4.1.2. Groundedness fine-tuning
4.2. ChatGPT
4.2.1. Supervised fine-tuning (SFT)
4.2.2. Reward modeling (RM)
4.2.3. Reinforcement learning(RL)
5. 마무리
1. 논문 소개
이에 대해 알아보기 위해 ChatGPT와 BARD와 관련된 3개의 논문들을 살펴보았습니다.
Bard의 경우 LaMDA, PaLM 2개의 논문을 살펴보았습니다.
LaMDA는 생성 모델에 관한 논문입니다. 어떻게 하면 생성 모델이 더 안전하고 사실에 기반한 답변을 생성할 수 있는지에 대해서 연구한 논문으로, 이들만의 특별한 방식의 fine-tuning을 사용해 이를 해결하는 내용이 담겨 있습니다.
PaLM의 경우 언어 모델의 크기를 엄청나게 키워 그 성능을 더 성장시켜보고자 하는 것이 주 내용입니다. 모델을 이루는 파라미터의 수가 무려 5400억개에 달하며, 이를 어떻게 효율적으로 훈련시켰는지, 또 모델 크기가 커지면서 성능이 얼마나 좋아졌는지에 대한 기록들이 주로 담겨 있습니다.
ChatGPT는 모델이 사용자의 의도대로 작동하도록 하는 것이 주요 목표입니다. 사용자의 의도란 좀 더 사용자들이 선호하는 대답을 생성하도록 모델을 유도한다는 것입니다. 여기에는 사실에 기반한 답변 생성, 편향적이지 않은 답변 생성, 좀 더 생생한 답변 생성 등 챗봇을 사람처럼 느끼기 위한 다양한 요소들을 모두 포함합니다. ChatGPT는 이를 강화학습을 이용해 해결합니다. 모델이 생성한 여러 개의 답변을 보고 사람들이 직접 가장 선호하는 답변 순으로 랭킹을 메겨 이를 모델에 학습시켜 사람이 가장 좋아할만한 답변을 생성하도록 모델을 유도하는 것입니다.
2. 훈련 데이터셋
Bard는 LaMDA와 PaLM이라는 논문의 모델에 기반한 모델이라고 하여 이 2개의 논문을 보고 정리해 보았습니다.
LaMDA의 경우 사전학습에 다음과 같은 데이터셋들이 사용되었습니다.
- 29.7억개 가량의 문서
- 11.2억개 가량의 대화문
- 133.9억개 가량의 대사
- 확보한 데이터셋의 90% 이상이 영어
PaLM에서는 위 데이터셋에 더해 프로그래밍 코드, 뉴스, SNS 기록 등을 추가로 수집했습니다. 총 7800억 개의 단어 token을 수집했다고 하며, 각 소스들의 비율도 공개되어 있습니다.

LaMDA와의 큰 차이점이라고 하면 외국어의 비율이 더 증가했으며 (총 22%의 외국어, 한국어는 0.195% 포함되었다고 하네요.) 프로그래밍 코드가 추가 되었다는 점입니다. Bard가 한국어를 할 수 있으며 프로그래밍 코드도 짜줄 수 있는 비결은 여기에 있는 것 같습니다.
Fine-tuning에서는 사용자들에게 LaMDA와 직접 소통한 대화기록을 수집하여 사용했습니다. 대략 총 16만 개의 대화문을 수집한 뒤, 필요에 맞춰 라벨링을 수행했습니다.
ChatGPT의 경우 사전학습된 GPT-3 모델을 활용합니다. GPT-3의 사전학습은 CommonCrawl 데이터셋을 필터링해서 사용합니다. CommonCrawl 데이터셋은 인터넷에서 웹페이지를 대규모로 크롤링해주는 api를 이용해 수집하는 데이터입니다. 여기에 WebText, Books 데이터셋, 영어 wiki 데이터셋들을 추가로 사용했습니다.

PaLM과 비교했을 때 데이터셋의 양이 2000억 token 정도가 더 적으며, 대화기록 데이터셋이 사용되지 않았다는 차이점이 있습니다.
Fine-tuning은 OpenAI에서 서비스하고 있던 playground를 이용해 사용자들이 chatGPT의 초기 모델과 대화한 기록들을 수집하여 데이터셋으로 사용했습니다.

특정 사용자에 모델이 편향되는 것을 막기 위해 한 사용자당 최대 200개의 prompt를 넘지 않도록 제한하여 데이터를 수집했다고 합니다.
ChatGPT의 fine-tuning은 3단계에 나눠서 진행되는데, 수집된 데이터들 역시 각 단계의 목적에 맞춰 라벨링을 수행해 따로 사용합니다. 1단계에는 13,000개, 2단계에는 33,000개, 3단계에는 31,000개의 데이터가 사용되었다고 합니다.
Bard의 fine-tuning에 사용된 데이터셋은 서로 대화를 주고 받는 형식인 듯하고, ChatGPT는 모델에게 지시를 내리고 그에 대한 모델의 대답으로 구성된 형식으로 보입니다.
3. 모델 구조
Bard, ChatGPT 둘 다 비슷한 기능을 수행합니다. 그렇다면 과연 두 모델의 모델 구조도 같을까요?
3.1. Bard
Bard와 ChatGPT 모두 동일하게 transformer decoder로 구성된 GPT구조를 갖습니다. 다만 PaLM은 거대 언어 모델을 실험한 만큼 모델의 크기에서 큰 차이가 있는데 LaMDA에 사용된 파라미터수는 1370억개 정도지만 PaLM에 사용된 파라미터 수는 5400억개 정도로 약 4배 정도 차이가 납니다.
그 밖에도 모델 구조에서도 자잘한 차이가 있는데요, PaLM의 경우 모델이 워낙 커 학습의 효율을 높여야 하기 때문에 모델의 구조를 약간 수정합니다.
PaLM이 학습 효율을 높이기 위해 사용한 전략들을 몇가지 간략하게 살펴보고 가겠습니다. 우선 Parallel한 구조입니다. 기존의 transformer decoder는 입력에서 출력까지 일자로 진행되는 구조를 갖고 있습니다. PaLM은 학습속도를 증가시키기 위해 구조를 parallel(병렬)하게 수정해 줍니다.

위와 같이 attention과 feed forward를 병렬적으로 수행했고 이를 통해 학습속도를 15% 향상시킬 수 있었다고 합니다. 성능에도 큰 차이가 없었구요.
두 번째로는 Multi-query attention의 사용입니다. 기존의 multi-head attention에서는 attention 연산을 위해 query, key, value 모두 [k(차원 수)*h(attention head의 수)] 크기의 tensor로 변환합니다.
하지만 multi-query attention에서는 key와 value값을 각 head마다 공유하도록 하여 그 수를 줄입니다. 즉, key와 value는 [1*h] 크기를 갖게됩니다. 이런 간소화는 학습 속도나 모델 성능에는 큰 영향이 없지만 텍스트를 생성하는 과정에서 발생하는 자원의 소모량을 크게 줄일 수 있었다고 합니다.
3.2. ChatGPT
ChatGPT는 GPT-3모델을 사용합니다. 파라미터는 1750억 개로 LaMDA보단 크지만 PaLM보다는 3배 정도 작습니다. ChatGPT는 생성 모델 외에도 Reward Model을 추가로 사용하는데 Reward Model도 GPT구조를 사용하지만 파라미터는 60억 개만 사용한다고 합니다. Reward Model은 텍스트를 생성하는 대신 점수를 측정하는 projection layer를 추가하여 사용합니다.
4. 학습 방식
챗봇의 가장 큰 산은 사실이 아닌 것을 사실처럼 말하는 hallucination문제, 특정 집단에 편향되는 언행이나 편견 (bias, toxic) 등을 최대한 줄이는 것입니다. 당연히 ChatGPT나 Bard의 설계에서도 이 부분에 대한 고민이 가장 크게 드러나 있고, 각자 서로 다른 방식을 통해 이를 해결하려고 합니다.
4.1. Bard
PaLM 모델의 경우 거대 모델을 효율적으로 학습하기 위한 방법 위주로 설명되어 있기 때문에 여기선 챗봇 모델의 학습방법과 관련 있는 LaMDA 논문의 학습방식만 살펴보도록 하겠습니다.
4.1.1. Quality & safety fine-tuning
Quality는 SSI라는 지표를 이용해 평가하며 SSI는 3개의 평가 점수의 평균으로 계산됩니다.
- Sensibleness : 모델이 생성한 문장이 얼마나 말이되는가를 평가합니다.
- Speicificty : Sensibleness만으로 평가할 경우 모델이 포괄적이고 짧은 문장 위주로 생성하게 되는 문제가 발생하게 됩니다. 따라서 모델이 더 길고 구체적인 답변을 할 수 있도록 하기 위해 추가한 이를 평가하는 지표입니다.
- Interestingness : Specificity에서 좀 더 심화된 평가기준으로 더 상대의 관심을 불러 일으키면서 얼마나 재치있고 통찰력 있는 답변을 만드는지를 평가하는 지표입니다. 예시를 들면 다음과 같습니다.
Q : "How do I throw a ball?"
A : "You can throw a ball by first picking it up and then throwing it"
위 답변의 경우 Sensibleness와 Specificity를 만족하지만 뭔가 밋밋한 느낌이 없잖아 있습니다.
A : " One way to toss a ball is to hold it firmly in both hands and then swing your arm down and up again, extending your elbow and then releasing the ball upwards.”
위 답변이 더 자세하고 흥미가 생기죠. 이런 경우 interestingness가 높다고 평가할 수 있습니다.
그리고 Safety는 모델이 편향적인 언행이나 욕설을 생성하는지를 평가하기 위한 지표입니다.
모델이 위 평가지표들에 맞춰서 학습하기 위해서 우선 데이터셋이 필요합니다.
SSI 점수를 개선하기 위해 사용자들이 LaMDA를 사용한 6,400개의 대화록과 121,000개의 대화문을 수집했다고 합니다. 각 대화기록들은 모두 최소 14턴에서 30턴의 대화를 주고 받은 기록을 담고 있습니다.
각 대화기록들은 Sensible, Speicificity, Interestingness 3가지 지표를 각각 "yes", "no", "maybe" 셋 중 하나로 평가하도록 지시했다고 합니다. 각 대화마다 5명의 서로 다른 사람이 평가를 한 뒤, 과반수에 따라 해당 문장의 라벨을 설정하였습니다.
Safety의 경우 연구진들이 자체적으로 결정한 기준에 따라 사용자들이 라벨링을 하도록 하였습니다. 기준은 크게 보면 아래와 같은 3가지 기준이 있습니다.
- 의도치 않은 공격적 언행이나 위험발언을 하지 않도록 한다.
- 특정 집단에 대한 부정한 말을 하지 않도록 한다.
- 위험을 불러일으키는 잘못된 정보나 의견을 생성하지 않도록 한다.
세부적인 기준들이 굉장히 많지만 크게 보면 위와 같이 정리할 수 있겠습니다.
이렇게 수집된 데이터셋들을 이용해 fine-tuning을 수행합니다. Fine-tuning은 위 평가지표들의 점수를 모델이 '생성'하는 방식으로 수행됩니다. 아래와 같은 방식으로 말이죠.
"What's up? <RESPONSE> not much. <SENSIBLE> 1 <INTERSTING> 0 <UNSAFE> 0"
모델이 사전학습 시에 다음 token을 예측하는 방식으로 학습되었기 때문에 classification이나 regression을 사용하는 것보단 이 방식이 더 모델이 익숙한 방법일 겁니다.
이렇게 모델을 어느정도 학습한 뒤, pre-training에 사용된 데이터셋 중 250만개의 대화문을 추출하여 이들을 라벨링한 뒤 다시 fine-tuning에 사용하는 식으로 하여 모델의 학습을 했다고 합니다.
4.1.2. Groundedness fine-tuning
Groundedness는 모델이 거짓 정보를 생성하지 않도록 하기 위한 지표입니다. 즉, 모델이 사실에 기반하여 답변을 생성하였는지를 평가합니다.
역시 fine-tuning을 위해 추가 데이터셋을 수집하는데, 사용자들에게 LaMDA와 소통하도록 부탁하여 총 40,000개의 대화문장으로 이뤄진 4,000개의 대화문을 수집하고 이들을 라벨링 합니다.
각 문장들은 우선 "생성된 문장이 외부 지식과 관련하여 생성되었는지"를 평가한 뒤, 해당 주장이 사실인지를 평가합니다. 만약 라벨링에 참여하는 서로 다른 3명의 참가자가 모두 해당 주장을 '사실'로 알고 있다면 해당 주장은 기본 지식으로 취급하지만 아닐 경우, 해당 답변과 관련되어 조사를 하되, 조사에 사용된 키워드를 모두 기록하도록 합니다.
마지막으로 모델이 생성한 답변을 직접 조사한 정보를 이용해 수정하고, 특정 웹페이지의 정보를 참고했다면 해당 페이지의 url링크를 끝에 삽입하도록 하였습니다.
이렇게 수집된 데이터셋을 이용해 fine-tuning을 수행해야 합니다. 이 fine-tuning 역시 텍스트 생성 방식으로 이뤄집니다. 과정은 예시를 통해 알아보도록 하겠습니다.
1. 질문 입력
LaMDA 모델에 질문이 입력됩니다. 그러면 모델은 이를 보고 질문과 관련된 검색 키워드를 생성해내게 됩니다.
input : "How old is Rafael Nadal?<EOS>"
output : "TS, Rafael Nadal's age"
2. TS를 이용해 관련 정보들을 탐색 후 출력
모델이 생성한 검색 키워드 앞의 "TS"라는 글자는 특수 토큰으로 TS(Tool Set)을 이용해 관련 정보들을 찾으라는 의미를 가집니다. 여기서 TS란 calculator, Information Retrieval, Translator 3가지로 구성된 시스템을 말합니다. 입력된 키워드에 따라 3가지 구성요소들이 관련된 정보들을 찾아서 출력해주는 것입니다.
위 예시의 경우 "Rafael Nadal's age"가 키워드이므로 calculator와 translator는 할 일이 없을 거고, Information Retrieval만 Rafael Nadal의 나이 정보와 관련된 문서를 찾아 결과를 아래와 같이 리스트 형태로 출력하게 됩니다.
TS input : "Rafael Nadal's age"
TS output : ["Rafael Nadal", "Age", "35"]
3. 다시 LaMDA를 이용해 답변을 생성하거나 추가 조사를 수행.
TS의 출력결과는 다시 LaMDA에 입력되어 질문에 알맞은 답변을 생성하거나 추가 조사를 수행합니다. 이는 모델이 USER 토큰을 생성했느냐 TS 토큰을 생성했느냐에 따라서 결과가 달라지게 됩니다.
예를 들면 모델이 아래와 같이 USER 토큰과 함께 답변 텍스트를 출력했다면 그대로 사용자에게 답변으로 내보내게 됩니다.
input : "How old is Rafael Nadal?<EOS>TS, Rafael Nadal's age<EOS>Rafael Nadal, Age, 35<EOS>"
output : "USER, He is 31 year's old right now."
반면에 모델이 아래와 같이 TS 토큰을 생성한다면 다시 관련하여 추가 정보를 조사하게 됩니다.
input : "How old is Rafael Nadal?<EOS>TS, Rafael Nadal's age<EOS>Rafael Nadal, Age, 35<EOS>"
output : "TS, Rafael Nadal's favorite song"
이 경우 다시 "Rafael Nadal's favorite song"이라는 키워드가 TS에 입력되게 되고 TS는 다시 관련 정보들을 찾아서 출력합니다. 그리고 LaMDA가 다시 추가 조사가 필요한지 바로 답변을 생성할지를 결정하게 됩니다. 즉, 2번과 3번 과정을 계속해서 반복할 수 있습니다.
이 루프에는 당연히 횟수 제한이 존재하며 최종적으로 생성된 USER 토큰 뒤의 답변을 사용자에게 답변으로 내놓게 됩니다.
4.2. ChatGPT
ChatGPT는 사전학습된 GPT-3 모델을 전이학습에 사용합니다. 이 사전학습된 GPT-3 모델을 3단계에 걸쳐 fine-tuning을 수행해 ChatGPT를 완성하게 됩니다.
4.2.1. Supervised fine-tuning (SFT)
우선 GPT-3 모델을 playground API에서 수집한 대화 내용 데이터들을 이용한 텍스트 생성을 이용해 fine-tuning을 수행합니다. 학습은 16에포크를 수행한 뒤, 가장 성능이 좋은 모델을 최종적으로 사용하게 됩니다. 성능의 평가는 뒤에서 나올 Reward Model을 이용한 RM score를 사용합니다. 학습 Loss를 확인하면 1에포크 이후로 과적합되는 것으로 보이지만 RM score는 점점 증가하는 경향을 확인할 수 있었다고 합니다.
4.2.2. Reward modeling (RM)
Reward model(이하 RM)은 모델의 답변이 적절한지 평가하는 역할을 합니다. 사용자의 질문과 그에 대해 모델이 생성한 답변을 입력받아 점수를 출력합니다. 모델은 SFT 모델보다 작은 크기의 GPT-6B를 사용하는데 컴퓨터 자원을 절약할 수 있다는 이유도 있지만, SFT와 같은 175B 크기의 GPT를 사용하면 학습이 안정적이지 못하다는 문제도 있었다고 합니다.
우선 학습을 위한 데이터를 준비해야 합니다. 각 질문마다 서로 다른 모델들의 답변을 최소 4개에서 9개까지 라벨러에게 제시해 줍니다. 그러면 라벨러는 해당 답변들을 좋은 순서대로 등수를 매깁니다.
RM은 2개의 답변을 비교해 어떤 답변이 더 좋은 지를 판별하는 식으로 학습됩니다. 만약 하나의 batch가 4개의 답변으로 구성되어 있다면, 2개씩 총 6번의 비교를 할 수 있게 되는 것입니다.

4.2.3. Reinforcement learning (RL)
최종적으로 앞서 학습된 SFT 모델과 RM 모델을 이용해 강화학습을 수행하게 됩니다. SFT 모델이 답변을 만들어내면, RM 모델이 해당 답변에 대한 점수를 판정하고, 그 점수가 높을수록 모델이 해당 답변을 생성하도록 장려하고(reward를 주고) 점수가 낮을수록 모델이 다른 답변을 생성하도록 유도하는 것입니다. Reward를 주는 방법은 loss가 작아지도록 하면 되겠죠?
그러면 모델이 reward에 따라서 스스로 더 좋은 답변을 생성하는 강화학습을 수행하게 됩니다. 하지만 그대로 강화학습을 수행하다보면 모델이 수렴하지 못하고 갈팡질팡하게 되는 문제가 발생할 수도 있습니다.
학습의 안정성을 높이기 위해서 PPO 알고리즘을 이용해 학습을 안정화합니다. 이 PPO 알고리즘은 간단히 설명하자면, 모델이 gradient descent를 수행하는 과정에서 이상한 방향으로 튀지 않도록 값을 제한하는 알고리즘입니다.
이 강화학습을 수행하다보면 SFT 모델이 사람과의 대화에 집중하여 학습을 하면서 기존에 GPT-3가 갖고 있던 여러 가지 task를 해결하는 능력을 잃게 되는 문제가 발생할 수 있습니다. 그렇기 때문에 이 강화학습을 수행하면서 GPT-3 사전학습에 하던 task를 함께 학습하여 이를 방지합니다.
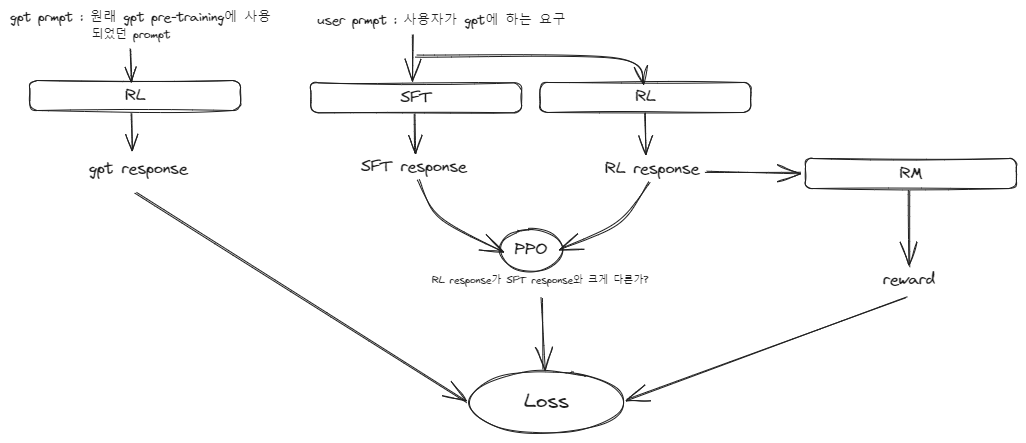
RL의 objective function은 아래와 같이 쓸 수 있습니다.

수식의 윗 항은 강화학습의 loss를 나타냅니다.
$\pi^{RL}_\phi(y|x)$는 RL 모델의 결과, $\pi^{SFT}(y|x)$는 SFT 모델의 결과를 나타냅니다.
즉, $-\beta log( \pi^{RL}_\phi(y|x)/ \pi^{SFT}(y|x)$는 RL 모델의 결과와 SFT 모델 결과가 서로 얼마나 다른지를 나타내는 비율이 됩니다. RL의 결과와 SFT의 결과 차이가 클수록 이 값이 커지게 되고, 음수이기 때문에 결과적으로 objective function을 작아지게 만듭니다. 앞의 $\beta$는 그 비율을 조절하는 하이퍼 파라미터고요.
$r_\theta(x,y)$는 reward로 클수록 objective function이 커지게 되죠.
아래 항은 GPT-3 pretraining의 objective function을 나타냅니다. 앞의 $\tau$는 그 비율을 조절하는 하이퍼 파라미터이고요.
5. 마무리
이렇게 Bard와 ChatGPT 모델의 차이에 대해서 간단하게 알아봤습니다. 두 모델 모두 비슷한 용도를 가지며 해결하고자 하는 문제가 비슷했지만 둘의 방식은 완전히 달랐습니다.
Bard는 텍스트 생성을 이용해 SSI와 Safety 점수를 메김과 동시에 적절한 외부 정보를 인용하여 답변을 생성하는 방식을 배웠으며, ChatGPT는 사용자의 선호도를 이용한 강화학습을 통해 같은 문제를 해결했죠.
이렇게 비슷해 보이는 모델이라도 학습 방법이 완전히 다르다는 것이 신기합니다. Bard와 ChatGPT의 비교는 이 정도로 정리해 보도록 하겠습니다. 감사합니다.
<참고 자료>
GPT-3 : https://arxiv.org/pdf/2005.14165.pdf
ChatGPT : https://openai.com/research/instruction-following
InstructGPT : https://arxiv.org/pdf/2203.02155.pdf
LaMDA : https://arxiv.org/pdf/2201.08239.pdf
PaLM : https://arxiv.org/pdf/2204.02311.pdf
'딥러닝 논문리뷰' 카테고리의 다른 글
| [EEVE] Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models (1) | 2024.05.02 |
|---|---|
| Textbooks are all you need (phi-1) (1) | 2024.01.17 |
| FASTSPEECH 2: FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH (1) | 2023.10.29 |
| (Tacotron2) NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS (1) | 2023.10.23 |
| VQA의 A to X (1) | 2023.09.25 |



