모델을 학습했다면 성능을 확인해야 합니다. 모델의 적용분야나 데이터 특성 등에 따라서 평가지표도 달라질 것입니다. 이번 포스트에서는 다양한 평가지표에 대해서 알아보도록 하겠습니다.
1. 손실도 (Loss)
가장 판단하기 쉬운 척도는 loss일 것입니다. 무엇보다도 모델은 loss를 최소화하는 방식으로 학습 되니까요. 일차적으로는 Loss가 작을수록 학습이 잘된 모델이라고 판단할 수 있을 겁니다. 하지만 loss는 컴퓨터를 위한 지표입니다. 역전파를 수월하게 할 수 있도록 설계한 점수입니다. 모델을 사용하는건 사람이죠. 그렇기 때문에 loss로 판단한 좋은 모델과 사람이 판단한 좋은 모델 간의 차이가 있을 수도 있습니다.
가장 간단한 지표로 정확도와 loss의 차이를 생각해 보겠습니다. Loss가 작아질수록 정확도도 좋아질까요? MNIST 데이터셋을 예제로 들어보겠습니다. MNIST 데이터셋은 입력된 이미지가 0부터 9까지의 숫자중 어느 숫자인지를 맞추는 데이터입니다. 맞추는 방식은 0부터 9까지 숫자들의 확률을 계산한 뒤, 가장 확률이 높은 숫자를 답으로 결정합니다. 따라서 정확도는 정답 숫자의 확률이 몇 퍼센트든 간에 다른 숫자의 확률들보다 높기만 하면 됩니다.
Loss는 어떻게 측정될까요? 클래스 분류 문제에 사용되는 CrossEntropyLoss는 정답 확률 분포와 모델이 예측한 확률 분포 사이의 차이를 계산합니다. 그렇기 때문에 정답 숫자의 확률이 높을수록, 정답이 아닌 숫자들의 확률이 낮을수록 loss가 작아지게 됩니다.
Loss나 정확도나 어쨌든 정답 숫자의 확률이 높으면 좋은 점수를 받으니 둘은 어느정도 비례관계가 있는 것으로 보입니다. 하지만 무조건 loss가 작을수록 정확도가 높아지는 것은 아닙니다. 다음과 같은 경우를 보겠습니다.

위와 같은 경우 모델 A와 모델 B가 모두 정답을 맞췄기 때문에 정확도에서는 둘 다 똑같은 점수를 받을 것입니다. 그러나 loss의 경우에는 모델 B가 더 작아지게 됩니다. 즉, loss는 모델 B가 더 작지만 사실 정확도는 둘이 차이가 없는 것입니다. 이와 같이 loss와 정확도는 무조건 비례하지 않으며 어떤 경우에는 loss가 더 작지만 오히려 정확도가 더 떨어질 수도 있습니다. 그렇기 때문에 loss도 충분히 좋은 지표지만, 상황에 따라서 더 알맞는 다른 지표들이 필요하게 될 수도 있습니다.
2. 정확도 (Accuracy)
정확도는 모델이 예측한 값과 실제 값이 서로 같은지 다른지만 판단하면 되는 가장 적용하기 쉬운 평가지표입니다. 하지만 이 정확도 역시 상황에 따라 목적에 따라 객관적인 평가지표가 되지 못할 수도 있습니다.
극단적인 예시를 들어보겠습니다. 만약 MNIST 평가셋에 숫자 9가 90개, 숫자 8이 10개 있다고 생각해 봅시다. 모델 A는 모든 평가셋을 숫자 9로 판단해서 90/100 (90%)의 정확도를 얻었습니다. 모델 B는 숫자 9의 이미지는 10개 틀렸지만 숫자 8의 이미지는 8개를 맞춰 88/100 (88%)의 정확도를 얻었습니다. 이 경우 모델 A가 모델 B가 좋다고 할 수 있을까요?

무조건 모델 A가 더 좋다고 하기는 조금 애매한 것 같습니다. 왜냐하면 모델 A는 숫자 8을 8이라고 읽을 수 있는 능력이 거의 없을 수도 있으니까요. 차라리 정확도를 조금 포기하더라도 숫자 8을 8이라고 읽을 수 있는 모델 B가 더 낫다고 볼 수도 있을 것 같습니다.
이처럼 정확도가 높은 것이 무조건 좋은 모델이라고 판단하기엔 어려운 경우가 존재합니다. 특히 라벨 별로 데이터 수가 불균형한 경우에 더 그렇습니다. 그렇다면 이런 경우엔 어떤 평가지표를 이용해 보완할 수 있을까요?
3-1. F1 score
F1 점수는 정확도의 문제점을 보완해줄 수 있는 평가지표라고 볼 수 있겠습니다. 쉽게 이해하기 위해 더 간단한 분류 문제를 생각해 보겠습니다. 입력받은 숫자 이미지에 적힌 숫자가 홀수인지 짝수인지 이진분류를 하는 더 간단한 모델을 생각해 볼게요. 모델이 예측한 답과 실제 정답이 가질 수 있는 경우의 수는 다음과 같이 총 4가지 입니다.
(홀수-홀수), (홀수-짝수), (짝수-홀수), (짝수-짝수)
정답과 예측값의 일치 여부만 판단하는 정확도보다 위의 4가지 경우를 모두 고려하는 것이 더 객관적인 지표가 될 수 있겠다라고 생각할 수 있습니다.
예시를 들어 생각해 보겠습니다. 극단적으로 테스트셋이 홀수 이미지 10개, 짝수 이미지 90개로 이뤄져 있다고 해봅시다. 이때 모델 A와 모델 B가 각각 다음과 같이 답을 예측했다고 생각해 보겠습니다.

위와 같이 정확도의 경우, 모델 A가 모델 B보다 높게 나타날 것입니다. 하지만 저희는 테스트셋에 홀수의 데이터 수가 짝수보다 훨씬 적다는 것을 알고 있습니다. 그렇기 때문에 짝수를 짝수라고 옳게 예측한 것보다, 홀수를 홀수라고 옳게 예측한 것에 더 집중할 필요가 있습니다.
F1 score를 계산하기 위해선 precision과 recall에 대해서 알아야 하는데, 편의를 위해서 더 강조해야 하는 대상 '홀수'를 '양성(Positive)'이라고 하고, '짝수'를 '음성(Negative)'이라고 하겠습니다. 이 때, 위에서 본 4가지 경우 (양성-양성), (양성-음성), (음성-음성), (음성-양성)은 다음과 같이 표현할 수 있습니다.

여기서 저희가 확인하고 싶은 것은 '양성(홀수)'를 모델이 실제로 '양성(홀수)'로 잘 예측하고 있느냐 하는 것입니다. 그렇다면 True Positive의 수가 가장 중요하겠죠.
여기서 모델이 '양성(홀수)'로 예측한 데이터들(True Positive + False Negative) 중 True Positive 데이터의 비율을 Recall이라고 합니다.
혹은 실제로 '양성(홀수)'인 데이터들(True Positive + False Positive) 중 True Positive 데이터의 비율을 Precision이라고 합니다.
Precision과 Recall은 True Positive의 비율을 계산하기 위한 타겟의 차이가 있지만 둘 다 True Positive의 비율을 보기 위한 지표라는 것은 동일합니다.
다시 홀수, 짝수 예시로 돌아와서 보자면 모델 A와 모델 B의 precision과 recall은 다음과 같이 계산할 수 있습니다.

결과를 보면 모델 A의 precision과 recall 점수는 0, 모델 B의 경우 precision과 recall의 점수가 0.8로 정확도와 반대로 모델 B의 precision, recall 점수가 더 높은 것을 확인할 수 있습니다.
Precision과 recall이 좋은 지표지만 모델 성능을 2개의 점수를 내서 살펴보는 것은 번거롭습니다. 그렇기 때문에 precision과 recall을 하나로 묶어서 볼 수 있는 F1 점수를 많이 사용합니다. F1 점수는 precision과 recall의 조화평균을 계산하는 지표입니다.
$$\text{F1 Score}={2*{{\text{precision}*\text{recall}}\over{ \text{precision}+\text{recall} }}}$$
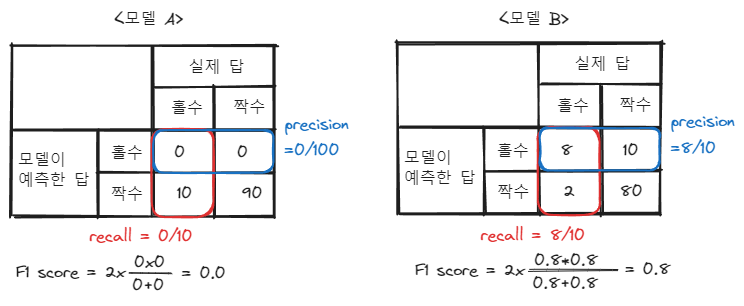
앞서 본 모델 A와 모델 B의 f1 점수를 계산하면 모델 A는 0, 모델 B는 0.8로 모델 B의 f1 score가 더 높다는 것을 확인할 수 있습니다.
익숙해지기 위해 하나만 더 계산해 보겠습니다. 모델 C는 다음과 같이 10개의 홀수 중 7개를 맞췄고, 90개의 짝수 중 84개를 맞췄습니다. 이 모델의 정확도와 f1 점수는 어떻게 될까요?

계산을 해보면 f1 점수는 0.61로, 역시 모델 B보다 정확도는 높을 지언정, f1 점수는 낮게 나타나는 것을 확인할 수 있습니다. True Positive의 수가 적기 때문이죠.
3-2. 다중 분류 문제에서의 F1 score (Macro와 Micro)
앞서 본 경우는 '홀수'와 '짝수' 2개의 라벨만 존재하는 경우의 f1 점수입니다. 라벨이 여러개인 경우에도 f1 점수를 계산할 수 있습니다. 이 경우엔 2가지 방법으로 f1 점수를 계산할 수 있는데 이 2가지 방법을 각각 macro, micro 방식이라고 합니다.
이번에 볼 예시는 이미지를 '개', '고양이', '쥐', '말' 4개의 동물로 분류하는 모델입니다. 모델 학습 결과 테스트셋에 대해 아래와 같은 결과가 나왔다고 할 때, micro-f1 점수와 macro-f1 점수를 각각 계산해 보겠습니다.

Macro-f1 점수의 경우, 각 class마다 f1 score를 계산한 뒤, 그 f1 score의 평균을 계산합니다. 각 class마다 평균을 낸다는 것은, 각 클래스를 양성으로 했을 때의 f1 점수를 말합니다.

클래스 별 f1 점수는 위와 같이 계산할 수 있습니다. 이 f1 점수들의 평균을 내면 macro-f1 점수가 계산됩니다.
$${0.71+0.82+1.0+0.78\over 4}=0.83$$
Micro-f1 점수의 경우, 모든 클래스의 True Positive, False Positive, False Negative를 합쳐 계산하게 됩니다.

결과를 보면, macro-f1 점수는 0.83, micro-f1 점수는 0.91로 두 점수의 차이가 꽤 큰 것을 확인할 수 있습니다. 왜 이런 차이가 발생하게 되는 걸까요?
이유는 라벨의 비율에 있습니다. macro-f1 점수는 각 라벨 별로 f1 점수를 계산합니다. 그렇기 때문에 각 라벨의 수가 어떻든간에 모두 공평하게 최종 f1 점수 계산에 들어가게 됩니다. 하지만 micro-f1 점수의 경우 라벨에 관계없이 모든 라벨의 True Positive, False Negative, False Positive를 사용해 계산합니다. 즉, 수가 많은 라벨에 더 큰 영향을 받게 되는 것입니다. 위의 경우 40개로 수가 많은 '쥐' 라벨에 대한 정확도가 상대적으로 수가 적은 '개' 라벨에 대한 정확도보다 큰 영향을 주게 되는 것입니다. 따라서 수가 가장 많은 '쥐' 라벨에 대한 정확도가 높을수록 micro-f1 점수도 높아지게 됩니다.
따라서 라벨의 비율을 고려하여 모든 라벨의 f1 점수를 공정하게 보고 싶을 경우 macro-f1 점수를, 라벨의 비율과 관계없이 전체적인 점수를 확인하고 싶을 경우 micro-f1 점수를 쓰는 것이 합당하다고 볼 수 있겠습니다.
4. Threshold
다시 이진 분류 모델로 돌아와 보겠습니다. 이진 분류의 경우 모델의 출력층에 sigmoid 활성화 함수를 사용해 0에서 1사이의 확률값을 내놓는 식으로 합니다. Loss는 실제 라벨과 모델이 계산한 확률값 사이의 차이를 계산하면 되지만, 정확도의 경우 어떻게 계산해야 할까요? 바꿔 말하면, 0부터 1사이의 값 중 어느 값을 기준으로 해야할까요? 이 기준값을 threshold라고 합니다. 보통은 0.5를 기준으로 0.5보다 작으면 0, 크면 1로 하여 정확도를 계산합니다.
모델의 목표에 따라 이 threshold에 대해서도 생각해 볼 필요가 있습니다. 예를 들어 욕설 필터링 서비스를 만든다고 생각해 봅시다. 입력된 문장이 욕설이라고 판단될 경우 1, 아닌 경우 0으로 분류하도록 모델을 학습할 겁니다. 이 때 정확도를 측정하기 위해서 임계값을 설정할건데 어떤 경우에 어떤 threshold를 사용하는 것이 좋을까요?
만약 threshold가 높아지게 된다면 모델은 대부분의 문장을 욕설이 아닌 것으로 분류하게 될 것입니다. 이 경우, 욕설 필터링 서비스는 최소한의 필터링을 통해 표현의 자유를 최대한 인정하는 인터넷 커뮤니티 등에 어울릴 것입니다.
반대로 threshold를 낮게 설정한다면 모델은 조금만 이상한 부분이 있어도 욕설로 분류하게 됩니다. 이 경우, 욕설 필터링 서비스의 목표는 나쁜 말은 일절 허용하지 않는 공공 서비스 등에 어울리게 됩니다.
Threshold에 따라 모델의 성능도 달라질 수 있습니다. 기본 threshold는 0.5지만 threshold를 0.6이나 0.3과 같이 높이거나 낮추는 것이 모델의 정확도가 더 높아질 수도 있겠죠. 따라서 분류 문제에서는 threshold도 파라미터로서 모델 성능에 영향을 줄 수 있는 요소입니다.
5. 마무리
이렇게 분류 모델의 평가지표들에 대해서 알아봤습니다. 분류 문제에서 알면 좋을 precision, recall 개념과 f1 점수를 위주로 글을 작성하게 되었습니다. 분류는 상대적으로 평가 점수를 내기 쉬운 문제에 속합니다. 어쨌거나 모델은 정답을 맞추거나, 못 맞추거나 둘 중 하나니깐요. 하지만 생성 모델 등의 모델들은 이렇게 확실한 기준을 잡기가 어려운 경우가 많고, 더 다양한 평가지표를 사용하기도 합니다.
어떤 평가지표를 선택하느냐에 따라서 같은 모델이라도 다른 성능을 보여줄 수 있습니다. micro-f1과 macro-f1 점수처럼요. 따라서 문제를 해결하고자 할 때 데이터와 모델 설정도 중요하지만, 이 모델의 성능을 판단할 평가지표도 굉장히 중요한 요소라고 할 수 있습니다. 새로운 문제를 풀게 될 때는 평가 지표에 대한 공부와 고민도 해보면 좋겠습니다.
'처음부터 하는 딥러닝' 카테고리의 다른 글
| PyTorch와 TensorFlow (PyTorchLightning과 Keras) (1) | 2024.01.07 |
|---|---|
| [딥러닝 기초] 데이터셋에 대한 고찰 (0) | 2023.12.11 |
| [딥러닝 기초] 본인 컴퓨터에서 직접 딥러닝 코드를 작성하고 실행해보자 (0) | 2023.10.01 |
| [딥러닝 기초] 전이 학습 (Transfer learning) (0) | 2023.06.19 |
| [딥러닝 기초] Overfitting과 모델 규제(regularization) (1) | 2023.06.14 |



