지금까지 대부분의 코드를 PyTorch로 작성해왔었는데 이번 시간엔 TensorFlow에 대해서도 알아보도록 하겠습니다. PyTorch와 TensorFlow의 코드를 비교해보면서 어떤 차이가 있는지 알아보면서 TensorFlow로도 코드를 능숙하게 작성하도록 해봅시다.
1. PyTorch와 TensorFlow 비교
1-1. 랜덤 시드 설정하기
1-2. MNIST 데이터 받기
1-3. 모델 만들기
1-4. 학습하기
2. PyTorch Lightning과 Keras
1. PyTorch와 TensorFlow 비교
TensorFlow 코드 (v.2.15.0) :
https://colab.research.google.com/drive/1AaF2TowXRcSoPyKRY_mFIG5DqcBtEv8S?usp=sharing
PyTorch 코드 (v2.1.0+cu121) :
https://colab.research.google.com/drive/1tUx20mQ5RKBivpUpAGEBc1BhE-2FbFPa?usp=sharing
전체 코드는 위에서 확인할 수 있습니다.
1-1. 랜덤 시드 설정하기
# TensorFlow
import tensorflow as tf
import numpy as np
import random
'''
it contains
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
'''
tf.keras.utils.set_random_seed(16)TensorFlow는 위와 같이 3개의 랜덤 시드를 설정할 수 있는데 tf.keras.utils.set_random_seed() 한 줄로 한번에 설정이 가능합니다.
# PyTorch
import random
import torch
import torch.nn as nn
def set_seed(random_seed):
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
random.seed(random_seed)
set_seed(16)
1-2. MNIST 데이터 받기
MNIST 분류 학습 코드를 Tensorflow와 PyTorch로 작성해보고 코드를 비교해 보도록 하겠습니다.
# TensorFlow
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
x_train = tf.expand_dims(x_train, -1)
x_test = tf.expand_dims(x_test, -1)
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)# PyTorch
from torchvision.datasets import MNIST
import torchvision.transforms as transforms
mnist_train = MNIST("./", train=True, transform=transforms.ToTensor(), download=True)
mnist_test = MNIST("./", train=False, transform=transforms.ToTensor(), download=True)
print(len(mnist_train), len(mnist_test))눈여겨 볼 점은 tensorflow 코드 전처리에서 '.to_categorical()'을 수행하는 겁니다. 이는 [3, 4, 7, 1]과 같이 되어 있는 라벨을 확률 분포 형태 ([[0, 0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]])로 바꿔주는 것입니다.
원래대로라면 PyTorch에서도 이런 과정을 수행해야 합니다만, PyTorch는 nn.CrossEntropyLoss() 함수가 자동으로 확률분포 형태로 바꿔주기 때문에 굳이 하지 않아도 상관이 없습니다.
1-3. 모델 만들기
# TensorFlow
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, kernel_size=(3, 3), strides=1, padding='same'
)
self.conv2 = tf.keras.layers.Conv2D(
filters=32, kernel_size=(3, 3), strides=1, padding='same'
)
self.pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)
self.conv3 = tf.keras.layers.Conv2D(
filters=16, kernel_size=(3, 3), strides=1, padding='same'
)
self.conv4 = tf.keras.layers.Conv2D(
filters=16, kernel_size=(3, 3), strides=1, padding='same'
)
self.pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)
self.flatten = tf.keras.layers.Flatten()
self.dense = tf.keras.layers.Dense(10, activation='softmax')
self.relu = tf.keras.layers.ReLU()
def call(self, inputs):
x = self.conv1(inputs)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool1(x)
x = self.conv3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.relu(x)
x = self.pool2(x)
x = self.flatten(x)
outputs = self.dense(x)
return outputs# PyTorch
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(
in_channels=1, out_channels=32, kernel_size=(3, 3), stride=1, padding='same'
)
self.conv2 = nn.Conv2d(
in_channels=32, out_channels=32, kernel_size=(3, 3), stride=1, padding='same'
)
self.pool1 = nn.MaxPool2d(
kernel_size=(2, 2), stride=2
)
self.conv3 = nn.Conv2d(
in_channels=32, out_channels=16, kernel_size=(3, 3), stride=1, padding='same'
)
self.conv4 = nn.Conv2d(
in_channels=16, out_channels=16, kernel_size=(3, 3), stride=1, padding='same'
)
self.pool2 = nn.MaxPool2d(
kernel_size=(2, 2), stride=2
)
self.dense = nn.Linear(in_features=7*7*16, out_features=10)
self.flatten = nn.Flatten()
self.relu = nn.ReLU()
def forward(self, inputs):
x = self.conv1(inputs)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.pool1(x)
x = self.conv3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.relu(x)
x = self.pool2(x)
x = self.flatten(x)
outputs = self.dense(x)
return outputs모델 작성 코드의 가장 큰 차이점은 PyTorch는 input shape를 입력해야 한다는 것입니다.
# TensorFlow
self.conv1 = tf.keras.layers.Conv2D(
filters=32, kernel_size=(3, 3), strides=1, padding='same'
)
self.dense = tf.keras.layers.Dense(10, activation='softmax')
# PyTorch
self.conv1 = nn.Conv2d(
in_channels=1, out_channels=32, kernel_size=(3, 3), stride=1, padding='same'
)
self.dense = nn.Linear(in_features=7*7*16, out_features=10)TensorFlow는 input shape를 입력하지 않아도 되기 때문에 코드를 작성하기 쉽습니다. 하지만 제대로 설계하지 않으면 shape 에러가 발생하기 쉽습니다. PyTorch는 매 레이어마다 input shape를 입력해야 하기 때문에 매번 shape을 계산해야 하는 번거러움이 있지만 그만큼 나중에 shape 에러가 잘 발생하지 않을 수 있습니다.
다음으로 CNN에서 입력되는 이미지의 shape에 차이가 있습니다. TensorFlow의 경우 (width, height, channel) 순으로 channel이 마지막이어야 하지만 PyTorch는 (channel, width, height)로 채널이 먼저입니다.
마지막으로 TensorFlow는 softmax를 통해 0에서 1사이 값으로 출력값을 조정해야 하지만 PyTorch는 nn.CrossEntropyLoss()에서 이를 수행하기 때문에 따로 코드를 작성하지 않아도 됩니다.
# TensorFlow
model = CNN()
model.build(input_shape=(16, 28, 28, 1))
model.summary()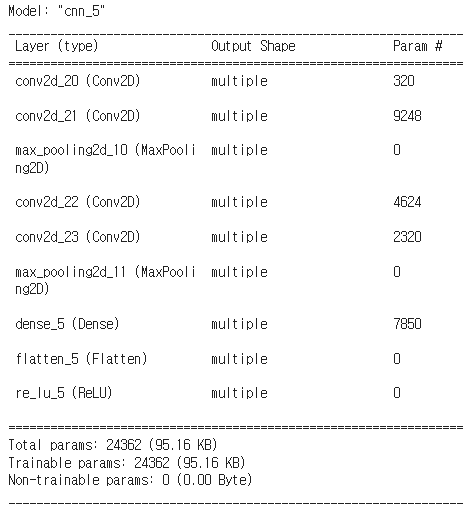
그 외에도 TensorFlow의 경우 .summary()를 통해 모델 구조와 파라미터 수, output shape등을 위와 같이 편하게 확인할 수 있습니다.
1-4. 학습하기
# TensorFlow
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
loss_fn = tf.keras.losses.CategoricalCrossentropy()
batch_size = 16
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(
buffer_size=train_dataset.cardinality(), reshuffle_each_iteration=True
).batch(batch_size)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(batch_size)
train_metric = tf.keras.metrics.CategoricalAccuracy()
valid_metric = tf.keras.metrics.CategoricalAccuracy()TensorFlow는 .from_tensor_slices()를 이용해 tensorflow Dataset으로 바꿔줄 수 있습니다. .batch()를 통해 배치를 구성할 수 있으며 .shuffle()을 통해 데이터를 섞을 수 있습니다. buffer_size는 섞을 데이터의 숫자이며 train_dataset.cardinality()를 통해 데이터 전체를 섞도록 설정할 수 있습니다.
# PyTorch
from torchmetrics import Accuracy
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.CrossEntropyLoss()
batch_size=16
train_dataset = torch.utils.data.DataLoader(
mnist_train, batch_size=batch_size, shuffle=True
)
val_dataset = torch.utils.data.DataLoader(
mnist_test, batch_size=batch_size, shuffle=False
)
acc_fn = Accuracy(task="multiclass", num_classes=10)PyTorch의 경우 metrics 관련 모듈이 없기 때문에 torchmetrics를 따로 설치해줘야 합니다. 또 optimizer를 선언할 때 model.parameters()를 인자로 전달하기 때문에 optimizer와 모델이 바로 짝을 이루게 됩니다.
마지막으로 학습코드입니다.
# TensorFlow
from tqdm import tqdm
epochs = 3
for epoch in range(epochs):
print(f"Epoch {epoch+1}/{epochs}")
train_loss = 0
for step, (x_batch, y_batch) in enumerate(tqdm(train_dataset)):
with tf.GradientTape() as tape:
logits = model(x_batch, training=True)
loss = loss_fn(y_batch, logits)
grads = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_metric.update_state(y_batch, logits)
train_loss += loss
print("loss: %.4f, acc: %.4f" % (float(train_loss)/(step+1), float(train_metric.result())))
train_metric.reset_states()
valid_loss = 0
for step, (x_batch, y_batch) in enumerate(val_dataset):
logits = model(x_batch, training=False)
loss = loss_fn(y_batch, logits)
valid_metric.update_state(y_batch, logits)
valid_loss += loss
print("val_loss: %.4f, val_acc: %.4f" % (float(valid_loss)/(step+1), float(valid_metric.result())))
valid_metric.reset_states()#PyTorch
from tqdm import tqdm
epochs = 3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("curretn device is ", device)
model.to(device)
for epoch in range(epochs):
print(f"Epoch {epoch+1}/{epochs}")
train_loss = 0
train_acc = 0
for step, (x, y) in enumerate(tqdm(train_dataset)):
x, y = x.to(device), y.to(device)
logits = model(x)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += acc_fn(logits.cpu(), y.cpu())
train_loss += loss.detach().cpu()
print("loss: %.4f, acc: %.4f" % (float(train_loss)/(step+1), train_acc/(step+1)))
valid_loss = 0
valid_acc = 0
for step, (x, y) in enumerate(tqdm(val_dataset)):
x, y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
loss = loss_fn(logits, y)
valid_acc += acc_fn(logits.cpu(), y.cpu())
valid_loss += loss.cpu()
print("loss: %.4f, acc: %.4f" % (float(valid_loss)/(step+1), valid_acc/(step+1)))PyTorch의 경우 GPU를 이용해 학습을 하려면 모델과 데이터를 GPU에 일일이 올려줘야 합니다. 반면에 TensorFlow는 자동으로 GPU에 올라가기 때문에 별도의 코드 작성이 필요 없습니다. 개인적으로 PyTorch에서 제일 불편했던 점 중 하나로 데이터, 모델을 일일이 GPU에 올리고, loss나 결과 기록할 때 자원을 아끼기 위해 .detach().cpu()도 일일이 붙이고 이런 것들이 너무 귀찮았습니다...
학습 루프에서도 다른 점이 있습니다. TensorFlow의 경우 파라미터 업데이트가 필요할 때(training 시) with tf.GradientTape() as tape: 를 이용해 gradient를 기록해야 합니다. PyTorch는 반대로 파라미터 업데이트를 하고 싶지 않을 때 (validation, test 시) with torch.no_grad(): 를 통해 gradient를 기록하지 않겠다고 해야합니다.
TensorFlow의 경우 위 코드를 실행하면 학습 속도가 오래 걸립니다. 이는 학습 코드가 컴파일 되지 않고 실행되기 때문인데 아래와 같이 training step을 함수로 만들고 @tf.function 데코레이터를 달아 컴파일을 해주면 학습속도가 빨라집니다.
# TensorFlow 학습 루프는 컴파일을 사용하도록 하자.
@tf.function
def train_step(x_batch, y_batch):
with tf.GradientTape() as tape:
logits = model(x_batch, training=True)
loss = loss_fn(y_batch, logits)
grads = tape.gradient(loss, model3.trainable_weights)
optimizer.apply_gradients(zip(grads, model3.trainable_weights))
train_metric.update_state(y_batch, logits)
return loss
@tf.function
def test_step(x_batch, y_batch):
logits = model(x_batch, training=False)
loss = loss_fn(y_batch, logits)
valid_metric.update_state(y_batch, logits)
return loss
for epoch in range(epochs):
print(f"Epoch {epoch+1}/{epochs}")
train_loss = 0
for step, (x_batch, y_batch) in enumerate(tqdm(train_dataset)):
loss = train_step(x_batch, y_batch)
train_loss += loss
print("loss: %.4f, acc: %.4f" % (float(train_loss)/(step+1), float(train_metric.result())))
train_metric.reset_states()
valid_loss = 0
for step, (x_batch, y_batch) in enumerate(val_dataset):
test_step(x_batch, y_batch)
valid_loss += loss
print("val_loss: %.4f, val_acc: %.4f" % (float(valid_loss)/(step+1), float(valid_metric.result())))
valid_metric.reset_states()2. PyTorch Lightning과 TensorFlow Keras
이렇게 PyTorch와 TensorFlow를 비교해보면 여러모로 TensorFlow가 더 편리한 부분이 많다고 느낄 수 있습니다. 이는 사실 Keras 덕분입니다. Keras는 TensorFlow를 더 편하게 사용하기 위해 만들어진 라이브러리인데 TensorFlow 2.0부터 keras가 tensorflow에 정식으로 합쳐지게 되면서 tensorflow를 더 쉽게 사용할 수 있게 되었습니다.
PyTorch 역시 마찬가지로 더 쉽게 사용하기 위한 pytorch lightning이라는 라이브러리가 존재합니다. Keras나 PyTorch Lightning을 사용할 때 가장 편리한 점 중 하나는 항상 길게 반복되던 훈련loop 코드를 크게 줄일 수 있다는 겁니다.
우선 Keras의 경우, model.compile()과 model.fit()을 이용해 위의 길던 학습 코드를 단 두 줄로 줄일 수 있습니다.
# TensorFlow
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=["acc"],
)
model.fit(
x_train, y_train, batch_size=16, epochs=3, validation_data=(x_test, y_test)
)PyTorch Lightning 역시 Trainer()를 이용해 훨씬 쉽게 학습 코드를 작성할 수 있습니다. 우선 PyTorch Lightning을 설치해야 합니다.
pip install lightningPyTorch Lightning의 Trainer()를 사용하기 위해선 LightningModule을 상속 받아서 모델 코드를 작성해야 합니다.
import lightning as L
class LightCNN(L.LightningModule):
def __init__(self):
super().__init__()
self.cnn = CNN()
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, inputs):
outputs = self.cnn(inputs)
return outputs
def training_step(self, batch, batch_idx):
x, y = batch
pred = self.cnn(x)
loss = self.loss_fn(pred, y)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
pred = self.cnn(x)
loss = self.loss_fn(pred, y)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer__init__()과 forward()는 nn.module()과 같습니다. training_step()과 validation_step()은 forward()와 비슷하지만 loss를 출력합니다. 즉, forward()는 inference에 사용되고 training_step()은 학습에 사용되는 함수라고 볼 수 있습니다.
또 configure_optimizers() 함수를 이용해 optimizer 설정을 할 수 있습니다.
이 3개의 함수는 아래와 같이 Trainer()를 통해 자동으로 실행되게 됩니다.
lightning_model = LightCNN()
trainer = L.Trainer(max_epochs=3)
trainer.fit(
model=lightning_model, train_dataloaders=train_dataset, val_dataloaders=val_dataset
)이렇게 PyTorch Lightning이나 Keras를 사용하면 학습 코드를 쉽고 간단하게 작성할 수 있습니다. 또 구현하기 귀찮고 어려운 fp-16, multi-gpu도 Trainer에 옵션으로 제공하면 쉽게 사용할 수 있습니다.
하지만 무조건 편리하고 좋기만 하진 않습니다. 만약 학습 loop에서 커스터마이징이 필요한 경우 Lightning이나 Keras의 모듈을 상속받아서 코드를 다시 작성해야 하는 번거로움이 있습니다. 그리고 PyTorchLightning의 경우 PyTorch와 별개의 라이브러리이기 때문에 PyTorch가 업데이트 되면 호환성 문제가 발생할 수 있는 문제도 있습니다.
이렇게 TensorFlow와 PyTorch 코드에 대해서 살펴봤습니다. 어떤 쪽이 더 편하신가요? 물론 편하다고 해서 하나만 사용할 수 있는 것은 아닙니다. 하나로 합쳐진다면 더 좋겠지만... 이 글을 참고해서 익숙치 않았던 TensorFlow, 혹은 PyTorch 코드에 익숙해지면 좋겠습니다. 감사합니다.
'처음부터 하는 딥러닝' 카테고리의 다른 글
| [딥러닝 기초] learning rate scheduler (1) | 2024.01.21 |
|---|---|
| [딥러닝 기초] 데이터셋에 대한 고찰 (0) | 2023.12.11 |
| 분류 모델의 평가 지표 (Accuracy와 F1 score) (1) | 2023.11.14 |
| [딥러닝 기초] 본인 컴퓨터에서 직접 딥러닝 코드를 작성하고 실행해보자 (0) | 2023.10.01 |
| [딥러닝 기초] 전이 학습 (Transfer learning) (0) | 2023.06.19 |



