1. 알고리즘 간단 정리
1.1. K-NN
1.2. Decision Tree
1.3. Random Forest
1.4. Linear/Logistic Regression
1.5. SVM
2. 머신러닝 기법 장단점 비교
3. 머신러닝 기법 코드 실험
1. 알고리즘 간단 정리
지금까지 알아 본 머신러닝 기법들을 간단히 정리하고, 여러가지 데이터셋들에 대해 실험해보고 결과 한번 확인해 보고 마무리 해보도록 하겠습니다.
1.1. K-NN

알고리즘
- 학습 데이터들을 저장한다.
- 예측해야 하는 데이터가 주어지면, 저장한 데이터들과의 거리를 측정한다.
- 측정한 거리를 보고, 가장 가까운 K개의 데이터의 과반수 라벨, 또는 평균값을 결과값으로 예측한다.
자세한 내용 : https://all-the-meaning.tistory.com/65
[머신러닝] 1. KNN (K-Nearest Neighbors)
1. KNN (K-Nearest Neighbors) 1.1. KNN의 작동원리 1.2. KNN의 하이퍼 파라미터2. KNN의 주요 특징 2.1. KNN의 장점 2.2. KNN의 단점3. KNN 코드 구현 3.1. scikit-learn에서 KNN 3.2. KNN 모델 실험
all-the-meaning.tistory.com
1.2. Decision Tree
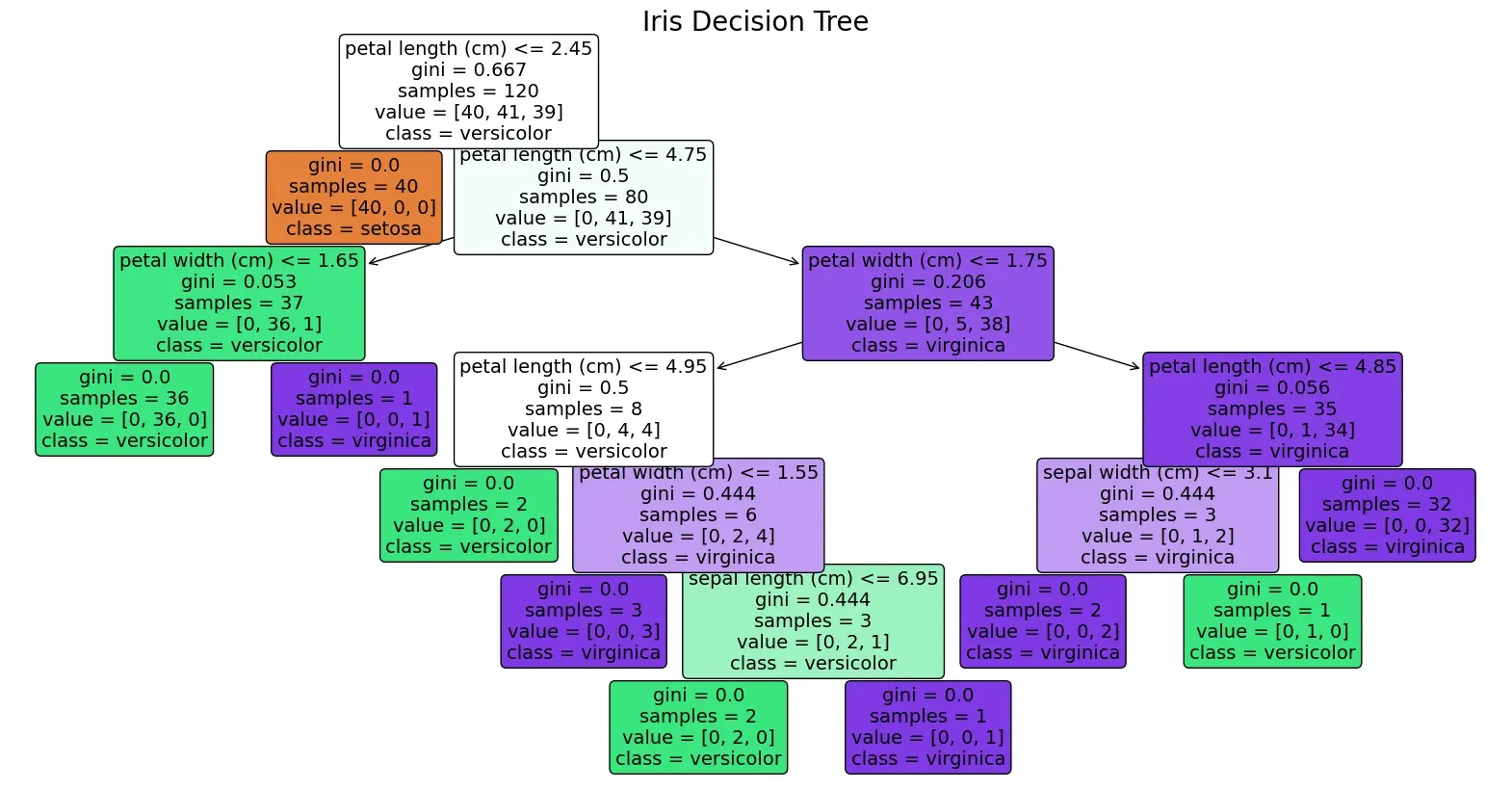
알고리즘
- 전체 데이터를 담고 있는 루트 노드로부터 시작해 이진 트리를 만든다.
- 2개의 자식 노드로 분류하기 위한 최적의 threshold를 찾는다.
- 여러 가지 threshold를 선정한 뒤, 해당 threshold로 생성된 자식 노드들의 불순도를 계산한다.
- 부모 노드의 불순도보다 불순도가 가장 크게 줄어든 threshold를 최종 threshold로 선정한다.
- 이 과정을 모든 분류가 끝날 때까지, 혹은 미리 지정한 횟수까지 반복하여 이진트리를 완성한다.
자세한 내용 : https://all-the-meaning.tistory.com/69
[머신러닝] 2. Decision Tree
1. Decision Tree 1.1. CART 알고리즘 A. 분류 문제 B. 회귀 문제2. Pruning 2.1. 소제목 2.2. 소제목3. Decision Tree의 주요 특징 3.1. Decision Tree의 장점 3.2. Decision Tree의
all-the-meaning.tistory.com
1.3. Random Forest

알고리즘
- 학습 데이터들을 랜덤하게 샘플링하여 새로운 데이터셋을 N개 만들어낸다.
- 각 샘플 데이터마다 Decision Tree를 하나씩 학습한다.
- 각 트리의 예측 결과를 앙상블하여 최종 결과를 도출한다.
자세한 내용 : https://all-the-meaning.tistory.com/70
[머신러닝] 3. Random Forest
1. Random Forest 1.1. Random Forest의 알고리즘2. Random Forest의 특징 2.1. 장점 2.2. 단점3. Random Forest 코드 구현 3.1. scikit-learn에서의 Random Forest 3.2. Random Forest 모델 실험
all-the-meaning.tistory.com
1.4. Linear/Logistic Regression

알고리즘
- 데이터를 표현하기 위한 선형함수를 가정한다.
- 가정한 선형함수를 계산한 예측값과 실제 계산값의 차이(=손실)를 계산한다.
- 손실을 줄일 수 있는 방향으로 gradient 계산, 혹은 newton 기반 계산을 통해 파라미터를 갱신한다.
- 손실이 최대한 줄어들 때까지 일정 횟수 반복 후 종료한다.
자세한 내용 : https://all-the-meaning.tistory.com/71
[머신러닝] 4. Linear Regression과 Logistic Regression
1. Linear Regression과 Logistic Regression 1.1. Linear Regression 1.2. Logistic Regression2. 손실 함수 2.1. Linear Regression 2.2. Logistic Regression3. 학습 방법 3.1. Linear Regression의 학습 방법 3.2. Log
all-the-meaning.tistory.com
1.5. SVM
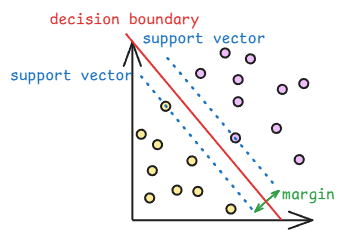
알고리즘
- 최적의 결정 경계를 찾기 위해 마진을 최대화 해야한다.
$margin={2\over||w||}$ - 마진을 최대화하기 위해 라그랑주 함수를 최소화하는 방법을 사용한다.
$L(w,b,\alpha)={1\over2}||w||^2-\sum^n_{i=1}\alpha_i[y_i(wx_i+b)_-1]$ - 라그랑주 함수를 최소화하기 위해 라그랑주 승수 $\alpha$를 최대화해야 하며, 이를 위해 아래 이중 문제를 해결한다.
$\underset{\alpha}{\text{max}}\sum^n_{i=1}\alpha_i-{1\over2}\sum^n_{i=1}\sum^n_{j=1}\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)$ - 이중문제의 $\alpha$에 대한 도함수가 0이 되는 지점을 찾는다. 이를 통해 최적의 결정 경계를 찾아가게 된다.
자세한 내용 : https://all-the-meaning.tistory.com/72
[머신러닝] 5. SVM (Support Vector Machine)
1. SVM이란?2. 결정 경계 찾기 2.1. 결정 경계와 서포트 벡터 방정식 2.2. 마진 측정 방법 2.3. ||w|| 최소화하기 2.4. 목적함수 설정하기 2.5. $\alpha$ 최대화하기 2.6. 정리3. 커널
all-the-meaning.tistory.com
2. 머신러닝 기법 장단점 비교
실험에 앞서 위 5개 기법들의 장단점을 비교해 보겠습니다.
| 장점 | 단점 | |
| K-NN | - 구현이 간단하고 이해하기 쉽다. - 학습 과정이 필요하지 않다. - 새로운 데이터를 추가하기 쉽다. - 비선형 데이터 학습이 가능함. |
- 거리 계산 과정에 계산 비용이 높음. - 데이터를 저장해야하기 때문에 메모리 문제가 발생 가능. - 노이즈에 민감하게 반응. - 고차원 데이터에서 거리 계산의 효과가 떨어져 성능 저하 문제 발생 가능. |
| Decision Tree | - 시각화하기 좋아 해석이 쉬움. - 데이터 전처리가 크게 필요하지 않음. - 비선형 데이터 학습이 가능함. |
- 노이즈에 영향을 크게 받을 수 있음. - 데이터를 완전히 일반화하는 optimal한 트리를 만들기 어려움. (과적합 되기 쉬움) - 희소 데이터 처리가 어려움. |
| Random Forest | - 과적합 위험이 낮음. - 노이즈의 영향을 적게 받음. - 병렬 학습으로 속도를 높일 수 있음. - 안정적인 성능을 보일 수 있음. |
- 계산 비용이 높음. - 해석이 어려움. |
| Logistic Regression | - 선형 함수를 사용해 간단하고 해석이 가능함. - 확률 출력이 가능함. |
- 비선형 데이터 처리가 불가능. - 고차원 데이터 처리가 어려움. - 특성들 사이의 상관관계가 높은 경우 성능이 잘 안 나올 수 있음. |
| SVM | - 커널 트릭으로 고차원 데이터에서도 강력. - 선형/비선형 문제 모두 처리 가능. - 과적합 위험 낮음. |
- 큰 데이터셋에서 학습 속도가 느림. - 커널, 하이퍼파라미터 선택이 까다로움. - 해석 어려움. |
비교해 볼 만한 점들로는 아래와 같은 특징들이 있습니다.
| 적합 | 부적합 | |
| 해석 가능성 | K-NN, Decision Tree, Logistic Regression | Random Forest, SVM |
| 비선형 데이터 처리 | KNN, Random Forest, SVM | Decision Tree, Logistic Regression |
| 노이즈 처리 | Random Forest | KNN, Decision Tree |
| 계산 효율 | Logistic Regression | KNN, Random Forest, SVM |
3. 머신러닝 기법 코드 실험
지금까지 살펴본 머신러닝 기법들의 성능을 여러가지 데이터셋들에 대해 실험해보고 결과를 비교 분석 해보도록 하겠습니다.
실험에 사용할 데이터셋들은 아래와 같습니다.
- iris : 3개의 꽃잎 특성을 보고 3종류의 꽃으로 분류하는 문제. 총 150개의 데이터 샘플.
- breast cancer : 30개의 신체 특성을 바탕으로 유방암 여부를 판별하는 문제. 총 569개의 데이터 샘플.
- digits : 8** 크기의 숫자 이미지를 보고 0~9까지의 숫자 중 하나로 분류하는 문제. 총 1797개의 데이터 샘플.
- bigdata : make_classifcation() 메소드를 이용해 만든 120개의 feautre로 구성된 노이즈가 있는 데이터셋. 총 20000개의 데이터 샘플.
- nonlinear : make_circles() 메소드를 이용해 만든 비선형 데이터셋. 총 1000개의 데이터 샘플.
최적의 결과를 비교하기 위해 각 모델마다 조정 가능한 파라미터들을 조절해가면서 최고 점수를 낸 모델을 비교에 사용했습니다. (svc의 경우 시간이 너무 오래 걸려서 kernel만 조정해 봤습니다.) 또, 결과의 재연성을 위해 random seed를 설정했습니다.
코드는 아래 링크에서 확인 가능합니다.
https://colab.research.google.com/drive/1ASVqPruGPpFdh7lB6citIHBHzhMgUxk8?usp=sharing
머신러닝 비교 분석.ipynb
Colab notebook
colab.research.google.com
A. 성능 비교

1. 간단한 데이터셋(IRIS)에 대한 결과
Iris 데이터셋에 대해서는 KNN의 성능이 가장 높게 나타났습니다. Iris 데이터셋이 노이즈도 없고 데이터 분리가 쉬운 편이기 때문에 KNN 방식이 가장 잘 통한 것으로 보입니다. 그 외에는 decision tree의 성능이 가장 낮게 나타났는데 과적합이 일어난 것으로 보입니다.
2. 라벨 불균형 대응 능력
라벨 불균형을 해결하는 능력을 보기 위해 bigdata의 라벨 비율은 8:2로 설정하였습니다. 그리고 f1 score를 통해 비율이 적은 라벨도 잘 맞추고 있는지를 확인해 봤습니다.
결과는 전체적으로 f1 score가 accuracy에 비해 떨어지는(대체로 비율이 많은 라벨로 예측하는 경향을 보인다는 뜻) 결과를 보였는데, 그 중에서도 KNN이 특히 accuracy와 f1 score의 차이가 큰 것을 볼 수 있었습니다. 즉, KNN은 라벨 불균형에도 영향을 크게 받는 것으로 보입니다.
3. Decision Tree와 Random Forest
Decision Tree의 경우 전반적으로 성능이 떨어지는 것을 볼 수 있었습니다. 아무래도 데이터를 일반화하기 어렵다는 단점이 크게 작용한 것으로 생각됩니다. 대신 상위호환이라 볼 수 있는 Random Forest의 성능은 전체적으로 높은 성능을 보여줬습니다.
4. 비선형 데이터
Nonlinear 데이터셋의 결과를 보면 Logistic Regression의 정확도는 30%대로 사실상 학습이 되지 않은거나 마찬가지인 모습을 보였습니다. Logistic Regression은 선형 함수를 사용해 비선형 데이터에 전혀 대응하지 못하는 것을 알 수 있었습니다.
5. Big Data에 대한 결과
Big Data의 경우 노이즈도 어느정도 있고 입력 feature의 수나 데이터 샘플의 수도 가장 많습니다. 이 데이터셋에 대해서는 SVM>Random Forest 순으로 높은 성능을 보였고, 나머지는 비슷한 성능을 보였습니다. 다른 데이터셋들에 대해서는 모델에 따른 성능 차이가 상대적으로 크지 않았던 것을 생각해 보면 복잡한 데이터셋에 대해서는 SVM과 Random Forest가 확실히 강점을 보인다고 생각할 수 있습니다.
B. 학습 시간 비교
주의
- KNN의 경우, 학습 시간 대신 예측 시간을 측정했습니다.
- 학습을 빠르게 하기 위해 일부 모델에 n_jobs를 이용한 병렬 학습을 설정했기 때문에 실제 학습시간보다 더 짧게 측정된 결과가 있을 수도 있습니다.
- 모든 파라미터를 다 조정한 것은 아니기 때문에 더 최적의 결과를 끌어낼 수도 있습니다.
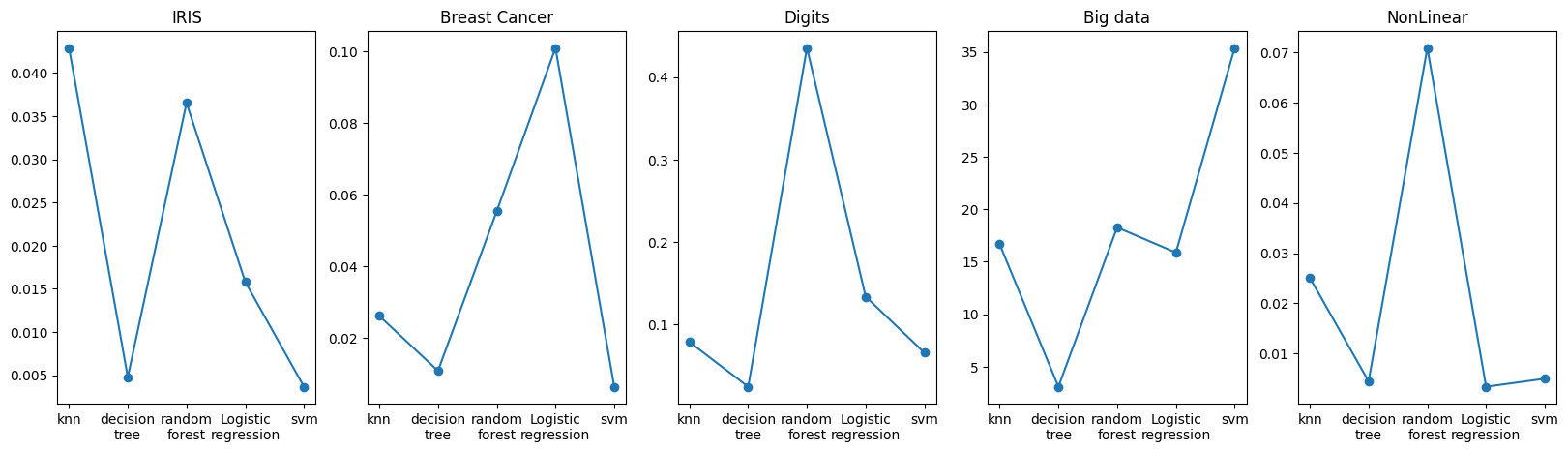
- Decision Tree는 전체적으로 적은 가장 낮은 학습시간을 보였습니다.
- SVM의 경우 작은 데이터셋들에 대해서는 학습시간이 짧았지만, Bigdata에 대해서는 압도적으로 오래 걸린 것을 확인할 수 있었습니다. 이는 SVM이 데이터셋이 커질수록 학습이 오래 걸린다는 특징을 확실히 보여주고 있습니다.
- Random Forest 역시 전반적으로 높은 학습시간을 보입니다. 여러 개의 트리를 학습하고 앙상블하기 때문에 나타나는 현상으로 보입니다.
4. 총정리
이렇게 각 머신러닝 기법들의 알고리즘, 장단점 비교, 코드 실험을 통한 비교까지 마쳤습니다. 저는 이를 공부하기 전에 scikit-learn에서 제공하는 다양한 머신러닝 기법들과 다양한 파라미터가 너무 많아서 뭘 어떻게 설정해야 할 지 알 수가 없었는데, 이번 정리를 통해 데이터와 상황에 따라서 어떤 모델을 어떤 파라미터로 적용해야 할 지에 대해 감을 잡을 수 있었습니다. 여러분들도 이번 글을 읽고 머신러닝 기법들에 대해 어느정도 이해를 갖추고 실제 데이터 예측에서 적절한 모델을 선택하는데 도움이 되었으면 좋겠습니다. 감사합니다.
0. 들어가는 글 : https://all-the-meaning.tistory.com/59
1. KNN : https://all-the-meaning.tistory.com/65
2. Decision Tree : https://all-the-meaning.tistory.com/69
3. Random Forest : https://all-the-meaning.tistory.com/70
4. Linear/Logistic Regression : https://all-the-meaning.tistory.com/71
'머신러닝 알아보기' 카테고리의 다른 글
| [머신러닝] 5. SVM (Support Vector Machine) (1) | 2024.12.04 |
|---|---|
| [머신러닝] 4. Linear Regression과 Logistic Regression (1) | 2024.12.03 |
| [머신러닝] 3. Random Forest (0) | 2024.11.27 |
| [머신러닝] 2. Decision Tree (0) | 2024.11.27 |
| [머신러닝] 1. KNN (K-Nearest Neighbors) (0) | 2024.11.26 |



