1. 들어가기에 앞서
2. 모델 구조
2.2. Rotary Positional Embedding (RoPE)
2.1. Multi-head Latent Attention (MLA)
2.3. DeepSeekMoE
3. 훈련 과정
3.1. Multi-Token Prediction
3.2. 8-bit precision
3.3. 사전학습 데이터와 방법
3.4. 강화 학습
4. 정리해보면...
1. 들어가기에 앞서
ChatGPT와 같은LLM(거대 언어 모델)은 이제 일반 사용자들도 많이 활용하기 시작했습니다. 하지만 여전한 문제 중 하나는 바로 막대한 비용입니다. ChatGPT와 같은 모델을 개발하고 운영하기 위해 필요한 비용이 너무 크기 때문에 일반 기업이나 연구자들이 쉽게 접근하기 어려운 영역이 되었습니다.
하지만 최근 중국에서 공개한 DeepSeek-V3의 모델이 상대적으로 저렴한 비용으로 chatGPT, Bard에 가까운 성능을 구현했다고 평가되면서 큰 주목을 받고 있습니다.
ChatGPT나 Bard의 정확한 모델 정보가 공식적으로 공개되지 않았기 때문에 직접적인 비교는 어렵습니다. 하지만 DeepSeek-V3는 코드와 모델을 무료로 공개했기 때문에, 이런 대형 모델에 어떤 기법을 적용할 수 있는지 면밀히 알아볼 수 있다는 점에서 살펴 볼 의미가 있다고 생각됩니다.
그래서 이번 글에서는 DeepSeek-V3: Technical Report를 기반으로, 이 모델이 어떤 기술을 이용해 비용을 절감하면서도 강력한 성능을 유지할 수 있었는지 분석해 보겠습니다.
코드 : https://github.com/deepseek-ai/DeepSeek-V3
논문 : https://arxiv.org/pdf/2412.19437
모델 : https://huggingface.co/deepseek-ai/DeepSeek-V3
2. 모델 구조
DeepSeek-V3도 기본적으로 Transformer를 기반으로 하는 구조를 갖습니다. Transformer와 차별화된 최적화를 위한 모델 구조들은 크게 MLA, RoPE, DeepSeekMoE 3가지로 나눠서 볼 수 있을 것 같습니다. 지금부터 하나씩 살펴보도록 하겠습니다.
2.1. Rotary Positional Embedding (RoPE)
Transformer 구조는 RNN 레이어를 사용하지 않기 때문에 텍스트들의 위치 정보를 사용하기 위해 Positional Embedding을 추가적으로 사용합니다. BERT, GPT 기반의 모델들은 주로 Absolute Positional Embedding(고정 위치 임베딩)을 사용했었습니다. 각 텍스트마다 위치 정보를 숫자로 입력하여 임베딩 파라미터를 추가해 위치 임베딩을 함께 학습하는 것이죠.
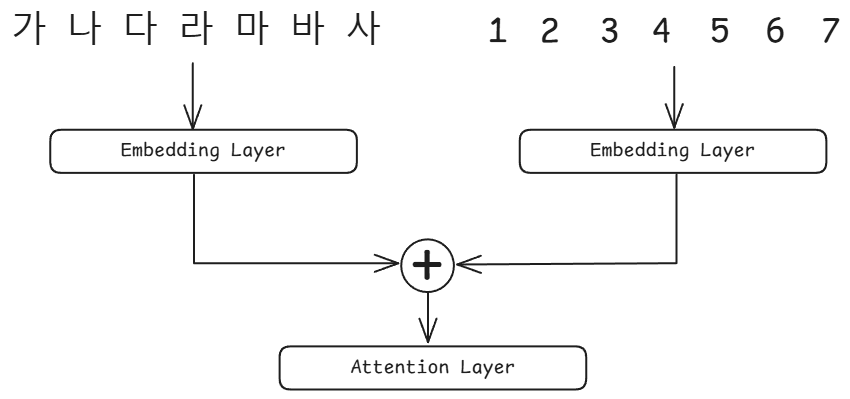
하지만 이 방법은 아래와 같은 단점이 있습니다.
- 학습된 길이보다 긴 문장을 처리하기 어려움 : 예를 들어 512 토큰 길이까지만 학습된 모델이 600 토큰 길이의 문장을 입력 받으면, 새로운 위치의 임베딩을 다시 학습해야 합니다.
- 절대적인 위치만 반영하고, 단어 간 상대적인 위치 관계는 고려하지 않음 : 문장이 길어질수록 앞 뒤 단어의 연관성이 떨어지는데 이를 고려하지 못합니다.
그래서 최근의 LLM들은 Rotary Positional Embedding(RoPE)를 주로 사용합니다. RoPE는 Relative Positional Embedding(상대적 위치 임베딩)의 일종으로, 회전 변환을 이용해 각 단어의 위치 정보 임베딩을 추가합니다. RoPE가 고정 위치 임베딩에 비해 갖는 장점은 아래와 같습니다.
- 추가적인 학습 파라미터가 필요 없음.
- 문장이 길어져도 추가 학습이 필요 없음.
- 긴 문장에서도 상대적인 위치 관계를 고려할 수 있음.
DeepSeek 역시 RoPE를 사용했으며, 학습 길이를 지정해 사전에 회전 변환에 필요한 행렬을 미리 계산하여 학습 속도를 향상시켰습니다.
# https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/model.py#L294
def precompute_freqs_cis(dim, seqlen):
base = 10000.0
freqs = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.float32) / dim))
t = torch.arange(seqlen)
freqs = torch.outer(t, freqs)
freqs_cis = torch.polar(abs=torch.ones_like(freqs), angle=freqs)
return freqs_cis
만약 Positional Embedding에 대해 더 자세히 알고 싶다면 아래 글을 참고하면 좋을 것 같습니다.
https://all-the-meaning.tistory.com/78
2.2. Multi-head Latent Attention (MLA)
기존의 Transformer 구조에 사용되는 attention은 multi-head attention입니다.

입력 받은 'input_embedding'을 query, key, value로 나눈 뒤, 각각 n개의 attention head로 분할하여 dot-product scale attention을 수행하는 방식입니다.
반면, MLA는 아래와 같이 input_embedding을 압축하는 low-rank compression이 추가됩니다.

Compressed Query(논문에서 $c^Q_t$)와 Compressed Key-Value(논문에서 $c^{KV}_t$)는 input_embedding의 차원 수를 줄인 압축된 벡터입니다. Query와 Key는 이 압축된 벡터를 이용해 위치 정보(RoPE)를 이용해 Query와 Key 벡터가 만들어집니다.
또한 Compressed Key-Value와 Key(RoPE)(논문에서 $k^R_t$)는 캐시로 저장됩니다. 이를 통해 중복 연산을 줄이고, 연산 속도를 향상 시킬 수 있습니다.
2.3. DeepSeekMoE
Original MoE
MoE(Mixture-of-Experts) 구조는 transformer block의 attention 뒤에 따라오는 feed-forward-network를 더 효율적으로 개조한 버전입니다.

MoE의 핵심 개념은 FFN을 여러 개의 전문가(expert)로 나누는 것입니다. MoE는 Gate function을 이용해 각 토큰에 특화된 2개의 전문가를 선택합니다.

"MoE가 더 효율적인 이유는?"
"기존의 FFN을 사용하면 모든 토큰이 모든 파라미터를 거치지만 MoE는 토큰마다 일부 전문가의 파라미터만 거칩니다. 따라서 토큰 처리에 사용되는 파라미터의 수가 훨씬 줄어듭니다. 따라서 같은 파라미터 수를 사용하더라도 실제로 활성화되는 파라미터의 수는 훨씬 적기 때문에 더 효율적으로 학습을 수행할 수 있습니다."
간략한 코드로 살펴보자면 아래와 같이 구현할 수 있습니다.
# https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/model.py #L532
class Gate(nn.Module):
...
def forward(self, x):
scores = self.linear(x)
scores = scores.sigmoid()
scores = scores.view(x.size(0), self.n_groups, -1) # n개의 전문가 그룹으로 분할
group_scores = scores.amax(dim=-1) # 각 그룹의 최고 점수를 출력
indices = group_scores.topk(self.topk_groups, dim=-1)[1] # top-k개의 전문가 index 선택
weights = scores.gather(1, indices) # 선택된 전문가 weights들 추출
weights /= weights.sum(dim=-1, keepdim=True) # 정규화
return weightsDeepSeekMoE
여기까지 기존의 MoE였다면 DeepSeek의 MoE는 전문가를 2개가 아니라 4개를 선택합니다. 토큰을 좀 더 많은 전문가에 할당함으로써 전문가 사이에 좀 더 많은 정보를 공유하도록 하기 위함입니다. 또, 이와 함께 전문가의 수도 2배로 늘려 파라미터의 수가 더 늘어나지 않도록 합니다.
여기서 한 발 더 나가 문법 구조, 일반 상식과 같은 언어 이해에 필요한 기본지식을 처리할 전문가를 공유함으로써 성능 향상을 꾀했습니다. 이 일반 상식을 담당하는 전문가는 모든 단어 토큰에서 고정적으로 선택됩니다. 따라서 DeepSeekMoE는 단어 토큰의 전문가를 선택할 때 하나의 일반상식 전문가와 3개의 각 단어토큰에 특화된 전문가를 선택하게 됩니다.

MoE를 적용함에 있어 가장 중요한 문제는 전문가가 불균형하게 선택되는 것을 방지하는 것입니다. 특정 전문가만 과도하게 선택되고 특정 전문가들은 거의 선택되지 않는다면 전문가를 분리한 의미가 없겠죠? 따라서 DeepSeek에서는 선택되는 비중을 균등하게 맞추기 위해 여러가지 기법을 추가로 사용합니다.
1. Auxiliary-Loss-Free Load Balancing
전문가의 score에 bias를 더해 균형을 맞추는 방법입니다. 이 bias term은 학습 도중에 함께 학습되는 파라미터가 아니라 실험자들이 직접 expert가 loading되는 과정을 모니터링하면서 직접 조절하는 상수항입니다.
2. Complementary Sequence-Wise Auxiliary Loss
추가 Loss term을 통해 전문가들의 균형을 유지하도록 합니다. Loss Term은 아래와 같이 생겼습니다.

$\alpha$는 loss 비율을 결정하는 하이퍼 파라미터, T는 입력 시퀀스의 토큰 수, N은 전문가의 수입니다. 쉽게 말해 모든 전문가가 균등하게 선택될수록 작아지는 loss term을 나타냅니다.
3. 훈련 과정
이번엔 DeepSeekMoE의 훈련과정에 대해 살펴보겠습니다.
3.1. Multi-Token Prediction (MTP)
Transformer 기반 모델은 attention 연산을 통해 병렬적으로 시퀀스를 처리한다고는 하지만, 최종적으로 토큰을 생성하는 부분에서는 순차적으로 토큰을 예측해 나가는 방법을 사용합니다. 결국 생성해야 할 텍스트의 길이가 길어질수록 추론 속도가 느려질 수 밖에 없습니다.
Multi-Token Prediction(MTP)은 이런 비효율성을 해결하기 위해 여러 개의 토큰을 한 번에 예측하는 방법입니다. MTP를 구현하기 위해 여러 개의 MTP Module을 이용해 여러 개의 토큰을 동시에 예측합니다.

맨 왼쪽의 그림이 일반적인 Transformer 구조의 모델입니다. 여기서 Transformer Block의 output을 다음 MTP Module1에 넘겨주어 그 다음 토큰 예측을 수행합니다. 그리고 MTP Module1의 Transformer Block의 output을 또 다음 MTP Module2에 넘겨주어 그 다음 토큰 예측을 수행하죠.
단순하게 보면 계산 과정은 그대로 길어지고 토큰도 사실상 순차적으로 생성되는 것이라 생각될 수 있습니다. 하지만 가장 연산량이 많은 맨 첫번째 Main Model의 L개의 Transformer Block을 거치지 않으면서 Output Head와 Embedding Layer의 파라미터를 공유하기 때문에 기존의 방식보다 훨씬 빠르게 다음 토큰들을 예측할 수 있습니다.
이 것이 가능한 이유는 훈련 과정에서는 그 다음에 와야 하는 토큰이 무엇인지 알기 때문입니다. 실제 사용 단계인 추론 과정에선 모델이 생성하는 토큰을 기반으로 다음 토큰을 예측해야 하기 때문에 이를 사용할 수 없습니다.
즉, MTP의 목적은 보다 빠르고 효율적인 학습을 수행하는 데 있습니다.
3.2. 8bit-precision 적용
대부분 LLM 모델의 학습에선 32bit의 float 단위가 사용됩니다. 하지만 여기 사용되는 bit의 수를 줄일 수 있다면 메모리를 아낄 수 있겠죠? 이런 생각에서 비롯된 방법이 16bit-precision(FP16 training)입니다. 하지만 단순히 비트 수를 32비트에서 16비트로 줄이기만 하면 되는 것이 아닙니다. 그 과정에서 손실되는 데이터가 모델의 성능에 악영향을 미치기 때문입니다.
따라서 16bit-precision을 적용할 때도 그냥 적용하는 것이 아니라, Gradient Scaling, LayerNorm 유지 등의 특수한 기법들을 함께 활용해 학습의 안정성을 보장해 주어야 합니다.
16bit-precision은 PyTorch나 Tensorflow에서 기본적으로 제공해 주는 보편화된 기술이지만, DeepSeek-V3에서는 한 발 더 나아가 8bit-precision을 적용했다고 합니다. 이를 통해 FP16보다 더 적은 메모리를 사용하면서도 성능 저하를 최대한 줄여 효율적으로 학습을 수행할 수 있었던 것으로 보입니다.
3.3. 사전 학습 데이터와 방법
데이터의 크기
사전 학습에 사용된 단어 토큰의 수는 약 14.8조 개라고 합니다. 이전 DeepSeek-V2에 비해 수학, 프로그래밍과 관련된 데이터의 비중을 높였으며, 영어와 중국어가 혼용된 문서의 양도 증가시켰다고 합니다.
토크나이저
토크나이저는 BPE 토크나이저를 사용했으며 이로 인해 생성된 토큰 사전의 크기는 128,000개라고 합니다.
Prefix-Suffix-Middle(PSM) framework
사전 학습에 사용된 특별한 방법이라고 하면 Prefix-Suffix-Middle(PSM) framework라는 것을 적용시켰다고 합니다. 원래의 학습 방식대로라면 모델은 텍스트를 앞에서부터 순차적으로 하나씩 예측해 나가게 됩니다. PSM은 문장이 주어졌을 때 중간에 구멍을 뚫고 그 중간에 들어갈 단어를 예측하는 방법입니다.
$$<|fim\_begin|>f_{pre}<|fim\_hole|>f_{suf}<|fim\_end|>f_{middle}<|eos\_token|>$$
$<|fim\_begin|>$, $<|fim\_end|>$는 각각 문장의 시작과 끝을 알리는 특수 토큰이며, $<|fim\_hole|>$은 모델에게 구멍이란 것을 알려주는 특수 토큰입니다.
$f_{pre}$와 $f_{suf}$는 각각 문장의 첫 부분과 끝 부분으로, 모델은 이를 보고 $<|fim\_hole|>$에 들어갈 적절한 단어 토큰 $f_{middle}$을 예측해야 합니다.
이런 식으로 순차적으로 예측을 하는 것은 똑같지만, 특수 토큰과 문장 구조의 변형을 통해 모델이 뒷 글자 뿐만이 아니라 중간 글자도 예측할 수 있게끔 하여 효용성을 더 높였다고 합니다. PSM이 적용된 문장의 수는 전체 데이터의 10% 정도라고 합니다.
YaRN(Yet another RoPE extensioN)
사전 학습을 마친 후에는 YaRN(Yet another RoPE extensioN)을 적용해 모델이 처리 가능한 문맥의 길이를 증가시켰다고 합니다.
기존의 RoPE의 문제점
- 문맥이 길어지면 회전 변환이 과하게 적용되며 문맥 정보를 제대로 유지하지 못함.
YaRN의 개선안
- 문맥 길이에 따라 회전 변환 보간(interpolation)을 통해 적절한 비율로 조절하여 멀리 있는 단어 사이의 관계도 잘 유지되게끔 함.
YaRN은 2단계에 걸쳐 모델이 처리 가능한 문맥의 길이를 확장하는데, 처음 1,000step 동안은 4,000 단어 토큰에서 32,000 단어 토큰으로, 다음 1,000step을 더 학습하여 최종적으로 128,000단어 토큰 길이까지 증가시켰다고 합니다.
3.4. 강화 학습
사전 학습 후에 모델이 사용자가 원하는 방향으로 작동하도록 하기 위해 강화 학습을 적용했습니다. 강화 학습을 위해 2가지의 모델이 사용되었습니다.
Rule-Base RM
딥러닝이 적용되지 않은 rule-based 모델로, 정답의 형식이 지정된 문제 ('1~5의 보기 중 하나를 고르시오'와 같은 문제)에서 사용되었습니다. 모델이 지정된 형식을 잘 지켜서 답을 낼 경우 모델에 reward를 제공해 그런 행동을 더 많이 하도록 유도해주는 역할을 수행합니다.
Model-Based RM
딥러닝을 통해 학습한 모델로 정답의 형식이 지정되지 않은 유형의 문제(글 짓기 등)에 사용된 모델입니다. 이 Reward Model은 사전학습된 DeepSeek-V3 모델을 통해 학습되었으며, 모델이 논리적인 답을 냄과 동시에 그 추론 과정까지 논리적으로 잘 설명한 텍스트를 생성할 경우에 reward를 제공해 그런 행동을 더 많이 하도록 유도했다고 합니다.
4. 정리해 보면...
이렇게 DeepSeek-V3에 사용된 다양한 경량화 방법들에 대해 알아 봤습니다. 길었던만큼 한 번 더 정리하고 마무리 하도록 하겠습니다.
- RoPE : 회전 변환을 이용한 positional embedding 방법으로 추가적인 파라미터 없이 상대적인 토큰 간의 거리를 잘 표현함.
- DeepSeekMoE : FFN을 여러 개의 전문가로 분할하여 각 토큰마다 특정 전문가들만 활성화하여 활성화 되는 파라미터 수를 효율적으로 줄임.
- MTP : MTP Module을 활용해 여러 개의 토큰을 한번에 예측하는 방식으로 학습의 효율성을 높임.
- 8-bit precision : 32bit의 계산값들을 8bit로 줄여서 표현하여 메모리 공간을 절약함.
- YaRN : 사전학습을 마친 후, 문맥 길이에 따른 부드러운 회전 변환을 RoPE에 적용하여 모델이 처리 가능한 문맥의 길이를 2단계에 걸쳐 늘림.
- 강화 학습 : 강화 학습을 통해 모델이 사용자의 의도대로 동작하게끔 post-training을 수행함.
물론 이런 것들이 적용되어 LLM의 무게를 많이 줄인 것은 사실이지만, 그럼에도 여전히 14.8조 개의 단어 토큰이라는 어마어마한 데이터가 필요하며, 2000개 가량의 H800 GPU로 2달동안 학습했으며 렌탈비가 5,576,000달러(80억 정도)가 들었다고 합니다. 이는 최종 학습에 사용된 비용이니 그 전에 실험에 사용한 비용까지 합하면 훨씬 많이 들겠죠... 여전히 웬만한 기업은 엄두를 내기 힘든 비용이라고 생각되지만 그래도 이런 노력들이 계속되다 보면 (혹은 양자 컴퓨터가 개발된다면..?) 비용을 더 줄일 수 있겠죠.
그리고 이런 기법들은 LLM이 아닌 모델들에도 충분히 적용 가능한 기법들이기 때문에 최적화와 경량화에 관심이 있다면 한 번씩 보면 좋을 것 같다는 생각이 듭니다. 그럼 DeepSeek-V3 리뷰는 여기서 마치도록 하겠습니다. 읽어 주셔서 감사합니다!
'딥러닝 논문리뷰' 카테고리의 다른 글
| [논문 리뷰] Image Inpainting for Irregular Holes using Partial Convolutions (0) | 2025.01.01 |
|---|---|
| [EEVE] Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models (1) | 2024.05.02 |
| Textbooks are all you need (phi-1) (1) | 2024.01.17 |
| 구글의 BARD와 openAI의 ChatGPT는 어떻게 다를까? (1) | 2023.12.20 |
| FASTSPEECH 2: FAST AND HIGH-QUALITY END-TOEND TEXT TO SPEECH (1) | 2023.10.29 |



