DeepSeek는 효율적인 모델 학습을 위해 3가지 구조를 적용했습니다.
- RoPE
- MLA
- DeepSeekMoE
이 3가지 구조가 정말 효과가 있는지, 있다면 어느 정도인지 궁금해져서 직접 실험해 보고 결과를 공유하려고 합니다!
자세한 이론적인 내용은 아래 글 참고해 주시고, 이번 글에서는 코드와 실험 결과를 위주로 공유해 드리겠습니다.
https://all-the-meaning.tistory.com/79
[논문 리뷰] DeepSeek-V3: Technical Report
1. 들어가기에 앞서2. 모델 구조 2.2. Rotary Positional Embedding (RoPE) 2.1. Multi-head Latent Attention (MLA) 2.3. DeepSeekMoE3. 훈련 과정 3.1. Multi-Token Prediction 3.2. 8-bit precision 3.3. 사전학습 데
all-the-meaning.tistory.com
1. 실험 방식
실험은 적당한 텍스트 데이터셋을 사용할건데, 저 같은 경우엔 빠른 실험을 위해 아래 링크의 샘플 데이터만 사용했습니다.
https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=543
AI-Hub
샘플 데이터 ? ※샘플데이터는 데이터의 이해를 돕기 위해 별도로 가공하여 제공하는 정보로써 원본 데이터와 차이가 있을 수 있으며, 데이터에 따라서 민감한 정보는 일부 마스킹(*) 처리가 되
www.aihub.or.kr
이 텍스트 데이터를 이용해 일반 GPT를 학습해 보고, RoPE, MLA, DeepSeekMoE를 차례대로 적용해 보면서 모델의 성능이 향상되는지, 학습 속도가 빨라지는지를 관찰해 보려고 합니다.
2. 데이터 전처리
데이터에서 필요한 대화 텍스트만 불러오기 위해 아래 코드를 사용했습니다. JSON 파일에서 원하는 부분을 추출한 뒤, 필요 없는 화자 구분이나 줄 바꾸기 기호 등을 제거해 줬습니다.
text_files = glob.glob('dataset/원천데이터/TS_02. FACEBOOK/*.txt')
texts = []
for txt_file in text_files:
text = ""
with open(txt_file, "r", encoding="utf-8") as f:
lines = f.readlines()
text = text.join(lines)
text = text.replace("1 : ", "").replace("2 : ", "").replace("\n", " ")
texts.append(text)토크나이저는 huggingface의 "klue/bert-base"를 사용했습니다. (사전학습 모델을 사용할 것이 아니라 아무 토크나이저나 사용해도 상관 없습니다.)
from transformers import AutoTokenizer
from sklearn.model_selection import train_test_split
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")
def tokenize_function(sentence):
return tokenizer(sentence, truncation=True, padding="max_length", max_length=256, return_token_type_ids=False, return_attention_mask=False)
datasets = [tokenize_function(data) for data in texts]
train_datasets, test_datasets = train_test_split(datasets, train_size=0.8)3. 기본 GPT 학습
GPT 모델에 직접 여러가지 구조들을 추가할 거라 모델도 직접 구현을 해야 했습니다. ChatGPT 도움 받아서 금방 작성했습니다.
class CustomMultiheadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value):
batch_size, seq_len, embed_dim = query.shape
q = self.q_proj(query).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(key).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(value).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_probs = nn.functional.softmax(attn_scores, dim=-1)
attn_probs = self.dropout(attn_probs)
attn_output = torch.matmul(attn_probs, v).transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
return self.out_proj(attn_output)
class CustomTransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward, activation='gelu'):
super().__init__()
self.self_attn = CustomMultiheadAttention(d_model, nhead)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.activation = nn.GELU() if activation == 'gelu' else nn.ReLU()
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
attn_output = self.self_attn(x, x, x)
x = x + self.dropout(attn_output)
x = self.norm1(x)
ff_output = self.linear2(self.activation(self.linear1(x)))
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x
class GPT(PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.token_embedding = nn.Embedding(config.vocab_size, config.hidden_size)
self.pos_embedding = nn.Embedding(config.max_seq_len, config.hidden_size)
self.layers = nn.ModuleList([
CustomTransformerEncoderLayer(d_model=config.hidden_size,
nhead=config.num_heads,
dim_feedforward=4*config.hidden_size,
activation='gelu')
for _ in range(config.num_layers)
])
self.ln_f = nn.LayerNorm(config.hidden_size)
self.head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.max_seq_len = config.max_seq_len
def forward(self, input_ids):
seq_length = input_ids.size(1)
positions = torch.arange(0, seq_length, device=input_ids.device).unsqueeze(0)
x = self.token_embedding(input_ids) + self.pos_embedding(positions)
for layer in self.layers:
x = layer(x)
x = self.ln_f(x)
logits = self.head(x)
loss = None
labels = input_ids
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, logits.size(-1)), labels.view(-1))
return CausalLMOutputWithCrossAttentions(loss=loss, logits=logits)모델의 설정은 아래와 같이 했습니다. (그래픽카드가 RTX3060이라 너무 큰 모델은 실험이 불가능 합니다😥)
# GPT 모델 정의
class GPTConfig(PretrainedConfig):
def __init__(self, vocab_size=50257, hidden_size=768, num_layers=12, num_heads=12, max_seq_len=512):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_heads = num_heads
self.max_seq_len = max_seq_len
gpt_config = GPTConfig(
vocab_size=tokenizer.vocab_size, hidden_size=256, num_heads=4, max_seq_len=256
)
model = GPT(gpt_config)그 뒤에 huggingface trainer를 사용해서 학습을 해줬습니다.
# 학습 설정
training_args = TrainingArguments(
output_dir="./gpt_model",
logging_strategy="epoch",
eval_strategy="epoch",
learning_rate=5e-4,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=5,
weight_decay=0.01,
save_total_limit=2,
)
# Trainer 설정
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_datasets,
eval_dataset=test_datasets,
)
# 학습 시작
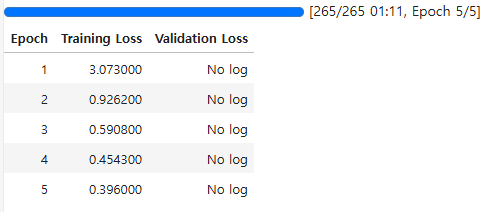
trainer.train()실험 결과는 아래와 같이 나왔습니다.

왜인지 Validation Loss가 기록되지 않는데(...) 5에포크 학습 정도로는 과적합이 발생할 것 같진 않아서 그냥 Training Loss로 성능을 비교하기로 했습니다.
시간은 1분 14초가 걸렸으며, 최종 loss는 0.5764가 나왔습니다.
4. RoPE, MLA 적용
4.1. RoPE
이번에는 RoPE 임베딩과 MLA를 적용해서 실험해 보도록 하겠습니다. DeepSeek-V3의 공식 깃허브를 참고해서 코드를 작성했습니다.
우선 RoPE를 적용하기 위해선 사전에 회전 변환 행렬을 계산해 둘 필요가 있습니다. 코드는 아래와 같이 작성했습니다.
def precompute_freqs_cis(dim, seqlen):
base = 10000.0
freqs = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.float32) / dim))
t = torch.arange(seqlen)
freqs = torch.outer(t, freqs)
'''
torch.polar(abs, angle) : Constructs a complex tensor whose elements are Cartesian coordinates
corresponding to the polar coordinates with absolute value abs and angle angle.
'''
# freqs_cis : freqs를 복소수 형태로 변환.
freqs_cis = torch.polar(abs=torch.ones_like(freqs), angle=freqs)
return freqs_cis
freqs_cis = precompute_freqs_cis(256//8, 256)
freqs_cis = freqs_cis.to('cuda')dim은 아래와 같이 계산합니다.
$$\text{dim}=\text{config.hidden_size}/\text{config.num_heads/}2$$
RoPE 회전 변환을 적용하는 시점이 Attention 연산 과정이기 때문에 attention heads의 차원 수로 맞춰줘야 하며, 회전 변환 연산을 복소수를 이용해 계산하기 때문에 2로 한 번 더 나눠줍니다. (복소수(torch.view_as_complex(x))를 적용하면 tensor가 실수 부분과 허수 부분으로 나눠지기 때문)
RoPE 적용은 아래와 같이 구현할 수 있습니다.
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
dtype = x.dtype
# 복소수 행렬곱 연산을 위해 입력 벡터(query와 key)도 복소수로 변환.
x = x.float().view(*x.shape[:-1], -1, 2)
x = torch.view_as_complex(x)
# 행렬 연산을 위해 회전변환 행렬의 shape 변형.
freqs_cis = freqs_cis.view(1, freqs_cis.size(0), 1, freqs_cis.size(1))
# 회전 변환을 적용한 뒤 다시 실수 형태로 변환.
y = torch.view_as_real(x * freqs_cis).flatten(3)
return y.to(dtype)이를 Attention 모듈의 query와 key에 적용해주면 되겠죠?
4.2. MLA
MLA의 핵심은 query, key, value의 압축을 통해 연산 속도를 절약하는 것입니다.
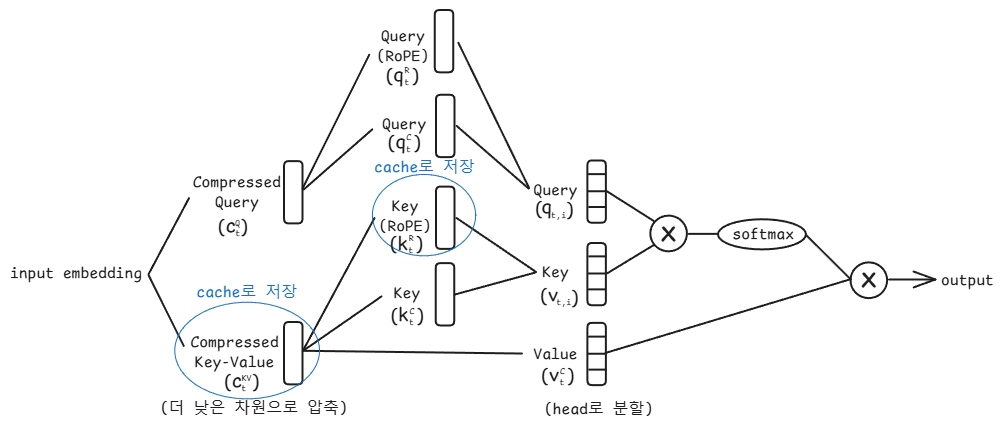
MLA 클래스의 생성자부터 살펴보겠습니다.
class CustomMultiheadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"
# compressed key-value를 만드는 레이어
self.w_dkv = nn.Linear(embed_dim, embed_dim)
# key와 value를 만드는 레이어
self.wkv = nn.Linear(embed_dim-self.head_dim//2, self.head_dim*6)
# compressed query를 만드는 레이어
self.w_dq = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
# key와 value는 캐시로 저장하여 중복 연산을 줄입니다.
self.register_buffer("k_cache", torch.zeros(32, 256, 4, 64), persistent=False)
self.register_buffer("v_cache", torch.zeros(32, 256, 4, 64), persistent=False)forward() 함수는 아래와 같이 구현합니다.
def forward(self, h):
batch_size, seq_len, embed_dim = h.shape
# query 계산 후 multi-head로 분할.
q = self.w_dq(h)
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim)
# query를 둘로 나눠 한 쪽에만 RoPE 적용.
q_nope, q_pe = torch.split(q, [self.head_dim//2, self.head_dim//2], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
q = torch.cat([q_nope, q_pe], dim=-1) # q : torch.Size([4, 256, 4, 64])
# key-value 계산
kv = self.w_dkv(h)
# key-value를 둘로 나눠 한 쪽에만 RoPE 적용
kv, k_pe = torch.split(kv, [embed_dim-self.head_dim//2, self.head_dim//2], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
# key-value를 key와 value로 분리
# query, key, value의 shape를 맞추기 위해 차원 수를 다시 계산해야 함.
kv = self.wkv(kv) # kv : torch.Size([4, 256, 384])
kv = kv.view(batch_size, seq_len, self.num_heads, int(self.head_dim*3/2)) # kv : torch.Size([4, 256, 4, 96])
k_nope, v = torch.split(kv, [self.head_dim//2, self.head_dim], dim=-1)
# k_nope : torch.Size([4, 256, 4, 32])
# v : torch.Size([4, 256, 4, 64])
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.num_heads, -1)], dim=-1) # k: torch.Size([4, 256, 4, 64])
# key와 value는 캐시로 저장.
self.k_cache = k
self.v_cache = v
# attention 연산 수행
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_probs = nn.functional.softmax(attn_scores, dim=-1)
attn_probs = self.dropout(attn_probs)
attn_output = torch.matmul(attn_probs, v).transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)
return self.out_proj(attn_output)나머지 코드는 모두 그대로 쓰면 됩니다! 그대로 실험을 해보면...
| Original GPT | GPT+RoPE+MLA | |
| Training Loss | 0.5764 | 0.3960 |
| 학습 시간 | 01:14 | 01:11 |
RoPE 적용으로 Training Loss가 원래 모델에 비해 0.2 가량 감소했고, MLA 적용으로 학습 시간이 3초 정도 줄었습니다. 학습 시간은 모델이 커질수록 더 차이가 날 것이라고 생각됩니다.
5. DeepSeekMoE 적용
DeepSeekMoE는 기존 transformer block의 Feed-Forward Network를 더 효율적인 레이어로 대체하는 방법입니다. MoE는 차원 수가 크던 기존의 Linear 레이어를 여러 개의 전문가(expert)로 나눠 단어마다 효율적인 전문가들을 선택하여 활성화되는 파라미터의 수를 줄이는 방법입니다.
DeepSeekMoE는 여기에 shared_experts라고 하는 항상 선택되는 expert를 추가합니다. 이 shared_experts는 기본적인 언어 상식을 담당하기 위함으로 더 좋은 성능을 보장하기 위한 방법입니다.

DeepSeekMoE부터 코드를 보여드리겠습니다.
class Expert(nn.Module):
def __init__(self, dim=256, inter_dim=128):
super().__init__()
self.w1 = nn.Linear(dim, inter_dim)
self.w2 = nn.Linear(inter_dim, dim)
self.w3 = nn.Linear(dim, inter_dim)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class MOE(nn.Module):
def __init__(self, n_experts=4, topk=2, dim=256):
super().__init__()
self.dim = dim
self.n_experts = n_experts
self.gate = Gate(n_experts, topk, dim)
self.experts = nn.ModuleList(
Expert(dim, dim//topk) for i in range(n_experts)
)
self.shared_experts = Expert(dim, dim//topk)
def forward(self, x):
shape = x.size()
# MoE는 모든 배치 데이터를 통합하여 처리합니다.
x = x.view(-1, self.dim)
# gate 함수를 통해 선택할 expert 인덱스를 계산합니다.
weights, indices = self.gate(x)
# y에 expert 연산 결과를 담습니다.
y = torch.zeros_like(x)
# bincount를 통해 각 전문가가 몇번 선택됐는지 알 수 있습니다.
counts = torch.bincount(indices.flatten(), minlength=self.n_experts).tolist()
for i in range(self.n_experts):
# 선택 되지 않은 전문가에 대한 연산은 스킵.
if counts[i] == 0:
continue
expert = self.experts[i]
idx, top = torch.where(indices == i)
y[idx] += expert(x[idx]) * weights[idx, top, None]
z = self.shared_experts(x)
return (y + z).view(shape), indices전문가를 계산하는 Gate 클래스는 아래와 같이 구현했습니다.
class Gate(nn.Module):
def __init__(self, n_experts=4, topk=2, dim=256):
super().__init__()
self.n_experts = n_experts
self.topk = topk
self.linear = nn.Linear(dim, n_experts, bias=False)
def forward(self, x):
scores = self.linear(x)
# deepseek는 sigmoid를 이용해 score를 계산합니다.
scores = scores.sigmoid()
original_scores = scores
# 가장 점수가 높은 topk개의 전문가 인덱스 저장.
indices = torch.topk(scores, self.topk, dim=-1)[1]
# 선택된 전문가들의 점수를 계산.
w = original_scores.gather(1, indices)
# 점수 합이 1이 되도록 정규화.
w /= w.sum(dim=-1, keepdim=True)
return w, indices이제 인코더 레이어에서 FFN을 MOE로 대체해주면 구현 끝입니다.
class CustomTransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward, n_experts, topk, activation='gelu'):
super().__init__()
self.self_attn = CustomMultiheadAttention(d_model, nhead)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
# FFN -> MOE
# self.ffn = FFN(d_model, dim_feedforward)
self.ffn = MOE(n_experts=n_experts, topk=topk, dim=dim_feedforward)
def forward(self, x):
attn_output = self.self_attn(x)
x = x + self.dropout(attn_output)
x = self.norm1(x)
ff_output, indices = self.ffn(x)
x = x + self.dropout(ff_output)
x = self.norm2(x)
return x, indices전문가의 수는 8로 지정하고, 선택할 전문가의 수는 1로 설정해서 실험했습니다. 결과는...

| Original GPT | GPT+RoPE+MLA | GPT+RoPE+MLA +DeepSeekMoE |
|
| Training Loss | 0.5764 | 0.3960 | 0.2230 |
| 학습 시간 | 01:14 | 01:11 | 02:54 |
Training Loss가 더 감소했습니다. 대신 학습 시간은 2배 이상 증가 했습니다. expert를 고르는 과정이 오히려 병목으로 작용하여 학습 시간이 길어진 것으로 보입니다. (모델의 차원 수가 증가하면 다른 결과가 나타날 수도 있을 것 같지만, 실험 할 수가 없으니...)
그래도 성능이 향상되었다는 것은 기대 이상의 결과였습니다.
6. 정리
- RoPE : 기존의 position embedding 학습 방식에 비해 확실히 성능 향상 효과가 있었음.
- MLA : 효율적인 연산으로 학습 시간을 절약함.
- DeepSeekMoE : 성능 향상에 도움을 주지만 작은 차원 수의 모델에서는 오히려 병목으로 작용해 느려지는 것으로 보임.
'딥러닝 논문리뷰' 카테고리의 다른 글
| VLA란 무엇일까? OpenVLA 논문 리뷰 (1) | 2026.01.11 |
|---|---|
| [논문 리뷰] DeepSeek-V3: Technical Report (0) | 2025.02.13 |
| [논문 리뷰] Image Inpainting for Irregular Holes using Partial Convolutions (0) | 2025.01.01 |
| [EEVE] Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models (1) | 2024.05.02 |
| Textbooks are all you need (phi-1) (1) | 2024.01.17 |



