안녕하세요! 오늘은 VLA에 대해서 알아보려고 합니다. 요즘 딥러닝의 발전이 정말 하루가 무섭게 빠르게 되고 있습니다. 하지만 그에 반해 실제 움직임, 즉 로봇에 관련해서는 발전이 꽤 늦다고 생각이 드는데요. VLA 연구를 통해 로봇의 발전도 큰 발전의 첫 걸음을 떼고 있는 것 같습니다.
VLA는 Vision Language Action Model의 줄임말로, Vision-Language AI 모델을 이용해 행동(Action) 을 학습하는 인공지능 모델을 말합니다. 딥러닝을 공부해 본 입장에서 현재 AI 모델들이 텍스트를 어떻게 학습하는지, 이미지를 어떻게 학습하는지에 대해서는 잘 알고 있지만, 이들을 활용해 어떻게 로봇의 행동을 학습하는 지가 궁금했습니다. 이에 대한 궁금증을 풀어내기 위해 가장 유명하면서 코드까지 공개되어 있는 OpenVLA 모델의 논문을 리뷰해보도록 하겠습니다.
VLA는 어떤 데이터로 학습될까?
OpenVLA 모델은 OpenX 데이터셋으로 학습되었다고 합니다. OpenX 데이터셋은 70개 이상의 로봇 데이터셋을 모아둔 데이터셋입니다. 저는 데이터셋의 생김새가 궁금했는데, github에서 데이터를 확인할 수 있는 jupyter notebook 코드를 제공해 주고 있었습니다.
Open-X-Embodiment : https://github.com/google-deepmind/open_x_embodiment/tree/main/colabs
위 링크에 있는 노트북을 실행해 보면 실제 데이터를 확인할 수 있습니다.

'action', {'base_displacement_vector': <tf.Tensor: shape=(2,),
dtype=float32, numpy=array([0., 0.], dtype=float32)>,
'base_displacement_vertical_rotation': <tf.Tensor: shape=(1,),
dtype=float32, numpy=array([0.], dtype=float32)>,
'gripper_closedness_action': <tf.Tensor: shape=(1,),
dtype=float32, numpy=array([0.], dtype=float32)>,
'rotation_delta': <tf.Tensor: shape=(3,), dtype=float32,
numpy=array([ 0.09483817, -0.02472992, 0.1407963 ], dtype=float32)>,
'terminate_episode': <tf.Tensor: shape=(3,), dtype=int32,
numpy=array([0, 1, 0], dtype=int32)>,
'world_vector': <tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 0.04174042, 0.00145912, -0.06551304], dtype=float32)>})
데이터셋은 이미지와 로봇의 action과 관련된 데이터들로 구성되어 있습니다.
- 로봇에게 보여지는 시각 이미지 : 동작을 수행하는 동안 관찰되는 이미지가 시간 순으로 저장되어 있습니다.
- 로봇의 행동 데이터 : 팔의 각도, 위치, 집게의 세기 등이 저장되어 있습니다.
- 지시문 : 로봇에게 내리는 지시 내용이 embedding vector 형태로 저장되어 있습니다.
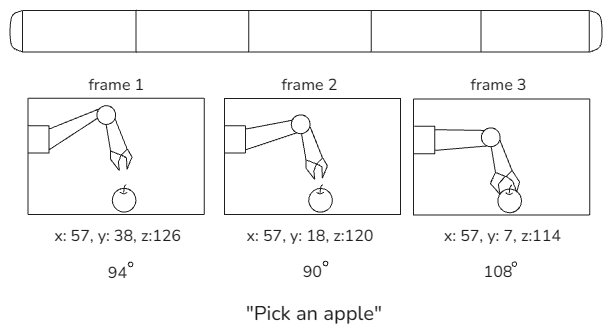
즉, VLA 모델은 각 시각 프레임마다 주어진 시각 정보와 지시문을 보고, 다음에 취해야 할 로봇의 행동 데이터를 예측하는 방식으로 학습된다는 것을 알 수 있습니다.
OpenX 데이터셋에 포함되어 있는 데이터셋들은 사용된 로봇의 종류가 모두 다르기 때문에 행동에 필요한 정보가 모두 다릅니다. 그래서 OpenVLA는 3인칭 카메라 시점의 이미지만 활용하고, 팔이 하나만 존재하는 로봇의 데이터만 사용해서 학습했다고 합니다.
OpenVLA는 어떻게 학습되었을까?
그러면 OpenVLA 모델은 이 데이터를 어떻게 학습했을까요? 우선 구조부터 살펴보겠습니다.
OpenVLA의 뼈대는 Prismatic VLM이라는 모델입니다. 이 모델은 '눈' 역할을 하는 비전 인코더와 '뇌' 역할을 하는 언어 모델(LLM)로 구성되어 있습니다. Prismatic은 GPT가 다음 단어를 예측하듯, 비전 인코더가 추출한 이미지 정보를 보고 그 뒤에 올 적절한 텍스트 토큰을 생성하도록 학습되었습니다.
OpenVLA 역시 이 원리를 그대로 가져왔습니다. 차이점이 있다면 이미지와 사용자의 명령어를 입력받은 뒤, 텍스트 대신 로봇이 수행해야 할 적절한 '액션 토큰'을 예측합니다.
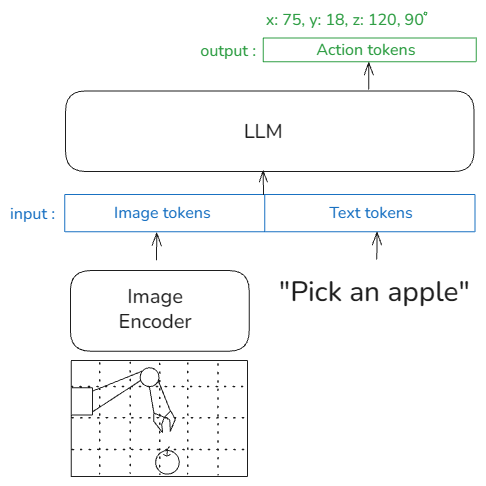
원리는 GPT와 ViT에 대해서 알고 있다면 어렵지 않게 이해할 수 있습니다. 그렇지만 여기서 액션 토큰은 뭘까요? 어떻게 로봇 팔의 좌표, 팔의 각도, 그립 등의 정보들을 토큰으로 변환할 수 있을까요?
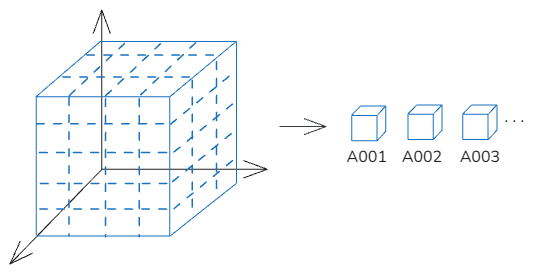
로봇의 액션 정보는 대부분 연속적인 숫자로 구성됩니다. 그렇기 때문에 정해진 값인 토큰으로 변환할 수 없습니다. 그래서 이를 모두 이산적인(discrete) 숫자로 변경합니다. OpenVLA 모델에 사용되는 액션 정보는 팔의 위치 좌표(x, y, z), 팔의 자세(roll, pitch, yaw), 집게 상태(open/close) 7개의 값을 활용하는데, 이 7개의 숫자로 이뤄진 공간을 256개의 공간으로 나눕니다. 그리고 각 공간마다 토큰을 하나씩 부여하는 것이죠. 이를 이용해서 로봇의 액션 정보를 토큰으로 변환할 수 있게 됩니다.
OpenVLA의 목표
모든 논문에는 어떤 문제점들을 해결하고자 하는 목표가 있습니다. OpenVLA 이전에도 VLA 모델들은 존재했습니다만, OpenVLA가 이전의 모델들과 차별화되는 점이 분명 존재하겠죠?
첫 번째는 모델이 완전 공개되어 있다는 점입니다. 기존 VLA의 SOTA 모델은 RT-2-X라는 모델입니다. 하지만 ChatGPT나 gemini와 같이 모델이 공개되어 있지는 않고 API와 같은 형태로만 이용할 수 있죠. 그렇기 때문에 이를 이용해서 나만의 로봇 AI를 새로 학습한다거나 하는 것은 불가능합니다. OpenVLA는 모델이 공개되어 있어 누구나 모델을 fine-tuning하거나 자유롭게 사용할 수 있도록 합니다. 아래 링크에서 실제 모델과 코드를 모두 확인 가능합니다.
모델 링크 : https://huggingface.co/openvla/openvla-7b
모델 코드 : https://github.com/openvla/openvla
기존 VLA 연구의 또 다른 문제점은, VLA 모델을 학습하기 위한 데이터셋이 부족하다는 것입니다. VLA 모델을 학습하기 위해선 로봇의 움직임과 관련된 데이터와 그 움직임에 대응하는 시각 자료와 해당 움직임을 설명하는 텍스트가 필요합니다. 그러나 이런 대응 쌍을 새롭게 만들어내는 것은 굉장히 오래 걸리겠죠? 그래서 기존에 이미지와 텍스트를 학습한 VLM 모델을 활용한다면, VLA의 데이터셋이 부족한 점을 어느정도 보완할 수 있지 않을까 하고 생각합니다. 이미지와 텍스트에 대한 사전지식을 갖고 있기 때문에, VLA 데이터셋에 존재하지 않는 물체나 상황에 대해서도 어느정도 적응할 수 있을 거라고 기대하는 것이죠.
OpenVLA 모델 성능
중요한 것은 학습되지 않은 상황에서도 모델이 잘 작동하는 지를 테스트하는 것입니다. 이런 일반화 성능을 이전 모델들과 비교하기 위해 위해 WindowX 로봇과 google robot 2개에서 성능을 측정해봤습니다.


결과 그래프를 보면 대부분의 task에서 OpenVLA의 성능이 우수한 것을 볼 수 있습니다. 이 결과가 더욱 놀라운 점은 RT-2-X 모델은 550억 개의 파라미터로 이루어져 있지만 OpenVLA 모델은 70억 개의 파라미터 만으로 이런 성능을 보여주었다는 겁니다. 이런 결과는 인터넷의 방대한 이미지와 텍스트를 사전 학습한 prismatic VLM 모델을 활용한 것이 영향을 줬다고 분석하고 있습니다.
또한 70억 개의 파라미터밖에 사용하지 않았기 때문에 좀 더 낮은 성능의 GPU에서도 사용이 가능합니다. 물론 모델을 그대로 사용하는 것은 불가하고, 양자화를 사용합니다.
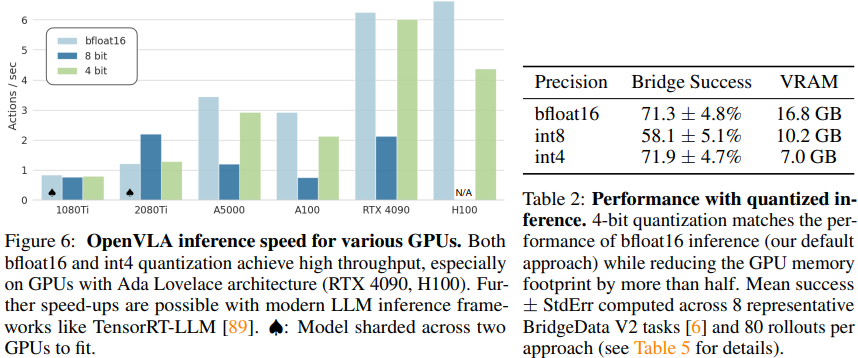
좌측의 그래프는 각 GPU별 inference 속도(1초당 수행 가능한 행동 수)를, 우측의 표는 양자화 기법을 사용했을 때 사용되는 VRAM의 크기와 모델 정확도입니다. 아직은 누구나 자유롭게 사용 가능할 정도까진 아닌 것 같지만 그래도 많이 완화된 것 같습니다.
VLA에 대해서 궁금해서 논문을 한 번 살펴보게 되었습니다. 어떻게 LLM 모델과 로봇이 연결되는지, 어떤 데이터로 학습 하는지 등이 궁금했습니다. OpenVLA는 로봇의 행동을 토큰화하고, 이미지와 지시문을 보고 그 뒤의 행동 토큰을 예측하는 방식으로 학습됩니다. 그리고 OpenVLA는 나름 모델의 크기도 작은 편이고, 코드와 모델이 공개되어 있다는 점에서도 의미 있는 것 같습니다. AI가 발달하는 것은 좋지만 너무 소수의 대기업에 모든 것들이 집중되는 느낌이 있었는데 이런 모델이 계속 나와준다면 작은 회사들에서도 이용할 수 있으니까요. 아직은 로봇 팔을 움직이는 정도지만 앞으로 어떻게 더 발전해서 로봇을 발전시킬 지 궁금해지기도 합니다. 그럼 여기서 마치겠습니다. 감사합니다.
'딥러닝 논문리뷰' 카테고리의 다른 글
| [실험] DeepSeek에 사용된 기법들, 정말 효과적일까? (1) | 2025.03.22 |
|---|---|
| [논문 리뷰] DeepSeek-V3: Technical Report (0) | 2025.02.13 |
| [논문 리뷰] Image Inpainting for Irregular Holes using Partial Convolutions (0) | 2025.01.01 |
| [EEVE] Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models (1) | 2024.05.02 |
| Textbooks are all you need (phi-1) (1) | 2024.01.17 |



